![]() 668
668
![]()
![]() 阿裏雲
阿裏雲
MapReduce開發插件介紹__Eclipse開發插件_工具_大數據計算服務-阿裏雲
選擇ODPS項目中的WordCount示例:
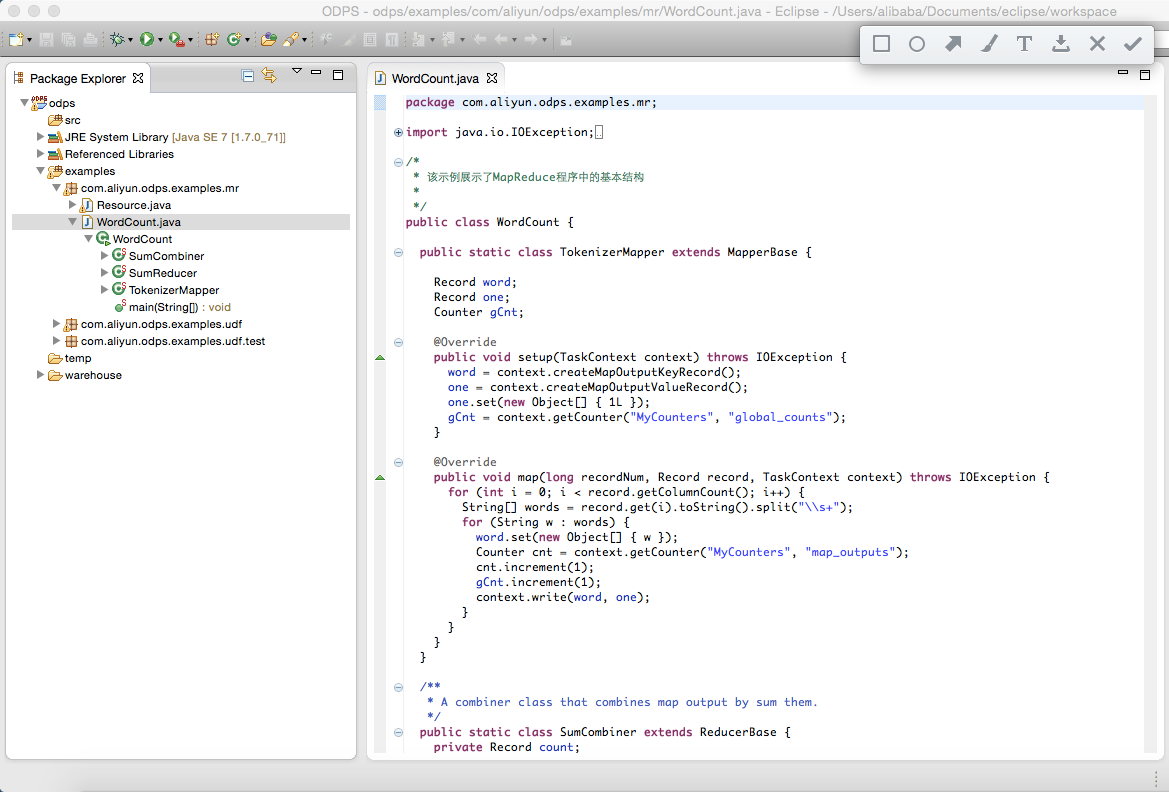
右鍵”WordCount.java”,依次點擊”Run As”,”ODPS MapReduce”:

彈出對話框後,選擇”example_project”,點擊確認:
運行成功後,會出現以下結果提示:

運行自定義MapReduce程序
右鍵選擇src目錄,選擇新建(New) -> Mapper:
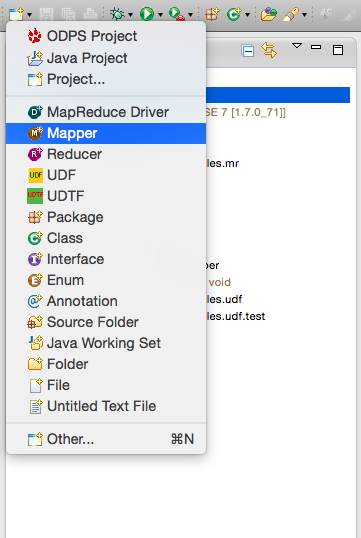
選擇Mapper後出現下麵的對話框。輸入Mapper類的名字,並確認:

會看到在左側包資源管理器(Package Explorer)中,src目錄下生成文件UserMapper.java。該文件的內容即是一個Mapper類的模板:
package odps;import java.io.IOException;import com.aliyun.odps.data.Record;import com.aliyun.odps.mapred.MapperBase;public class UserMapper extends MapperBase {@Overridepublic void setup(TaskContext context) throws IOException {}@Overridepublic void map(long recordNum, Record record, TaskContext context)throws IOException {}@Overridepublic void cleanup(TaskContext context) throws IOException {}}
模板中,將package名稱默認配置為”odps”,用戶可以根據自己的需求進行修改。編寫模板內容:
package odps;import java.io.IOException;import com.aliyun.odps.counter.Counter;import com.aliyun.odps.data.Record;import com.aliyun.odps.mapred.MapperBase;public class UserMapper extends MapperBase {Record word;Record one;Counter gCnt;@Overridepublic void setup(TaskContext context) throws IOException {word = context.createMapOutputKeyRecord();one = context.createMapOutputValueRecord();one.set(new Object[] { 1L });gCnt = context.getCounter("MyCounters", "global_counts");}@Overridepublic void map(long recordNum, Record record, TaskContext context)throws IOException {for (int i = 0; i < record.getColumnCount(); i++) {String[] words = record.get(i).toString().split("\s+");for (String w : words) {word.set(new Object[] { w });Counter cnt = context.getCounter("MyCounters", "map_outputs");cnt.increment(1);gCnt.increment(1);context.write(word, one);}}}@Overridepublic void cleanup(TaskContext context) throws IOException {}}
同理,右鍵選擇src目錄,選擇新建(New)->Reduce:
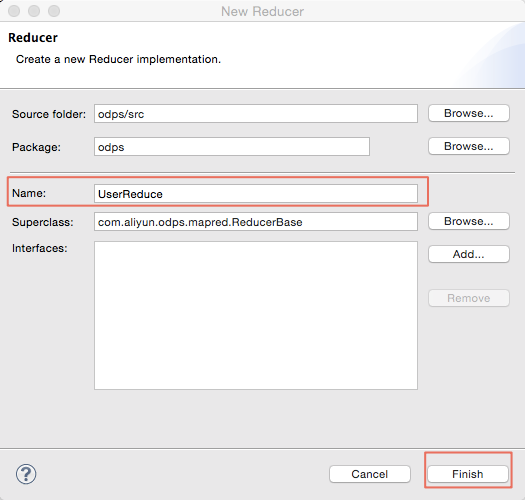
輸入Reduce類的名字(本示例使用UserReduce):
同樣在包資源管理器(Package Explorer)中,src目錄下生成文件UserReduce.java。該文件的內容即是一個Reduce類的模板。編輯模板:
package odps;import java.io.IOException;import java.util.Iterator;import com.aliyun.odps.counter.Counter;import com.aliyun.odps.data.Record;import com.aliyun.odps.mapred.ReducerBase;public class UserReduce extends ReducerBase {private Record result;Counter gCnt;@Overridepublic void setup(TaskContext context) throws IOException {result = context.createOutputRecord();gCnt = context.getCounter("MyCounters", "global_counts");}@Overridepublic void reduce(Record key, Iterator<Record> values, TaskContext context)throws IOException {long count = 0;while (values.hasNext()) {Record val = values.next();count += (Long) val.get(0);}result.set(0, key.get(0));result.set(1, count);Counter cnt = context.getCounter("MyCounters", "reduce_outputs");cnt.increment(1);gCnt.increment(1);context.write(result);}@Overridepublic void cleanup(TaskContext context) throws IOException {}}
創建main函數: 右鍵選擇src目錄,選擇新建(New) -> MapReduce Driver。填寫Driver Name(示例中是UserDriver),Mapper及Recduce類(示例中是UserMapper及UserReduce),並確認。同樣會在src目錄下看到MyDriver.java文件:

編輯driver內容:
package odps;import com.aliyun.odps.OdpsException;import com.aliyun.odps.data.TableInfo;import com.aliyun.odps.examples.mr.WordCount.SumCombiner;import com.aliyun.odps.examples.mr.WordCount.SumReducer;import com.aliyun.odps.examples.mr.WordCount.TokenizerMapper;import com.aliyun.odps.mapred.JobClient;import com.aliyun.odps.mapred.RunningJob;import com.aliyun.odps.mapred.conf.JobConf;import com.aliyun.odps.mapred.utils.InputUtils;import com.aliyun.odps.mapred.utils.OutputUtils;import com.aliyun.odps.mapred.utils.SchemaUtils;public class UserDriver {public static void main(String[] args) throws OdpsException {JobConf job = new JobConf();job.setMapperClass(TokenizerMapper.class);job.setCombinerClass(SumCombiner.class);job.setReducerClass(SumReducer.class);job.setMapOutputKeySchema(SchemaUtils.fromString("word:string"));job.setMapOutputValueSchema(SchemaUtils.fromString("count:bigint"));InputUtils.addTable(TableInfo.builder().tableName("wc_in1").cols(new String[] { "col2", "col3" }).build(), job);InputUtils.addTable(TableInfo.builder().tableName("wc_in2").partSpec("p1=2/p2=1").build(), job);OutputUtils.addTable(TableInfo.builder().tableName("wc_out").build(), job);RunningJob rj = JobClient.runJob(job);rj.waitForCompletion();}}
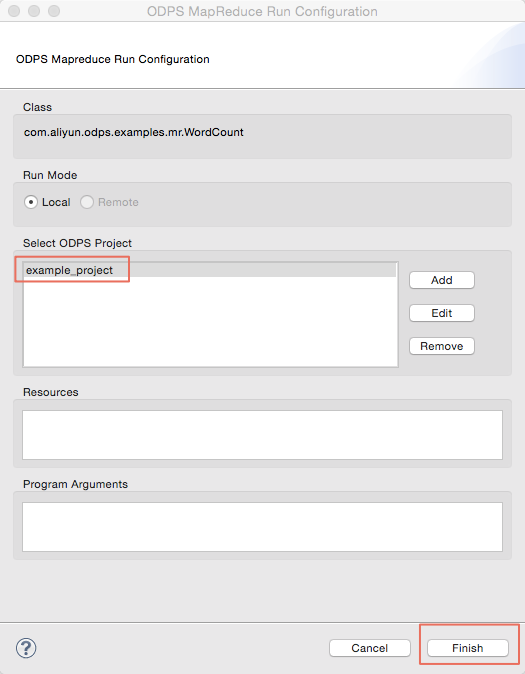
運行MapReduce程序,選中UserDriver.java,右鍵選擇Run As -> ODPS MapReduce,點擊確認。出現如下對話框:

選擇ODPS Project為:example_project,點擊Finish按鈕開始本地運行MapReduce程序:
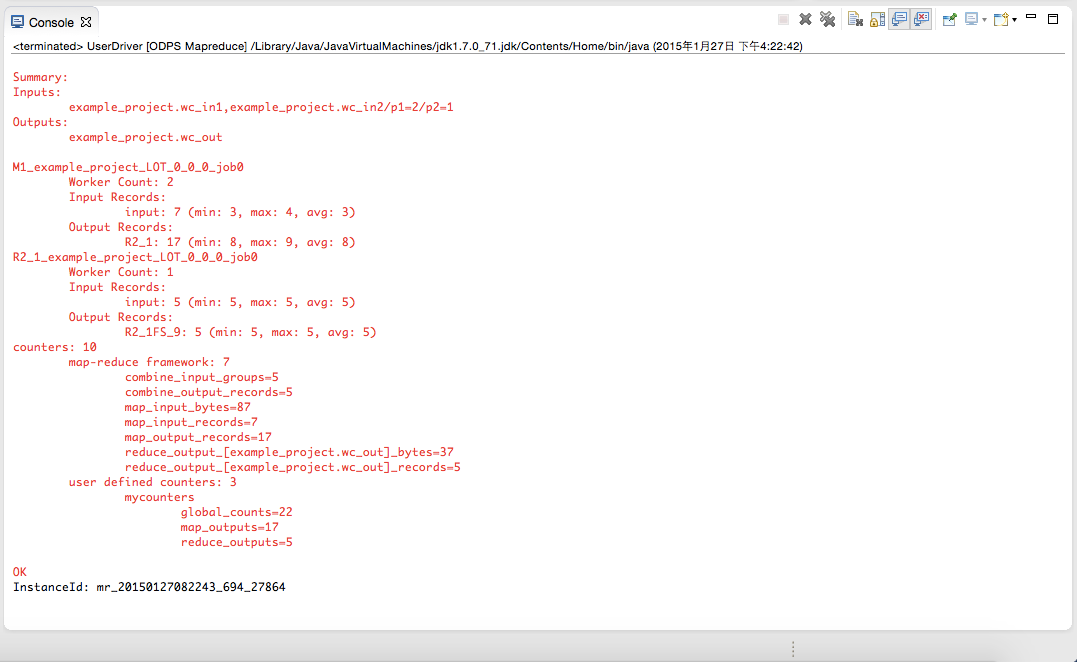
有如上輸出信息,說明本地運行成功。運行的輸出結果在warehouse目錄下。關於warehouse的說明請參考 本地運行 。刷新ODPS工程:
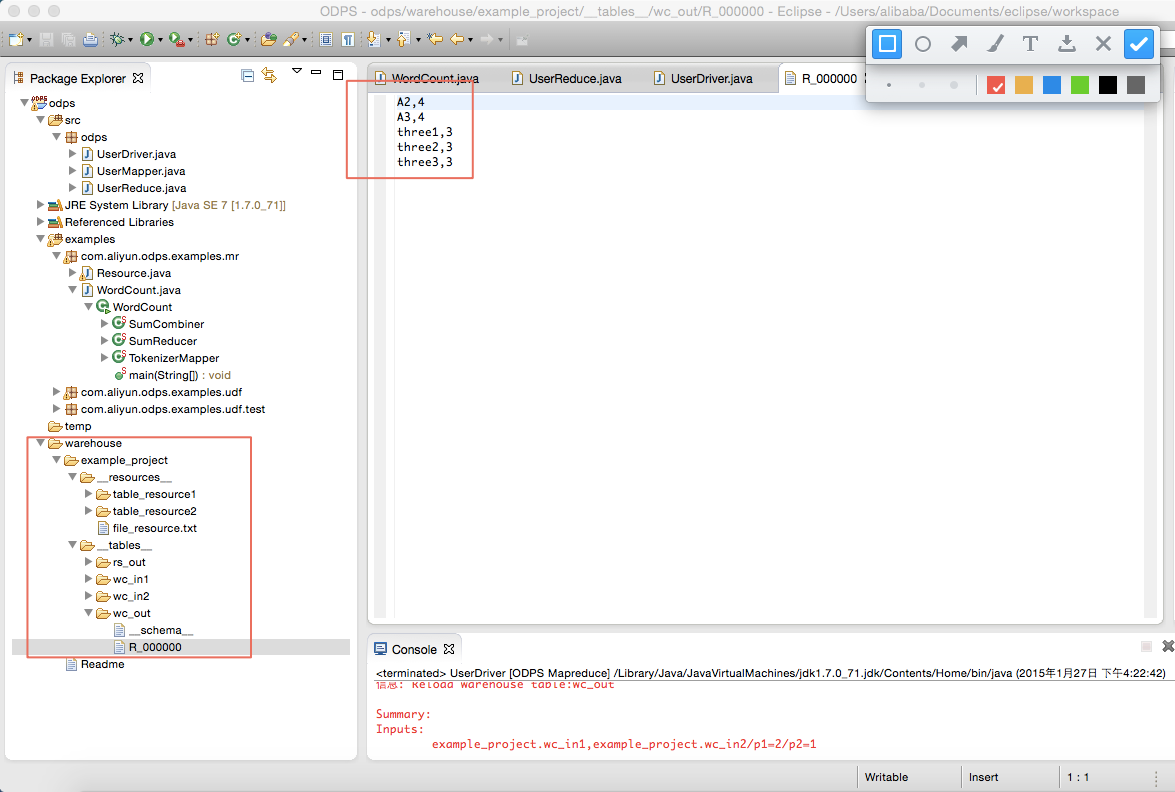
wc_out即是輸出目錄,R_000000即是結果文件。通過本地調試,確定輸出結果正確後,可以通過Eclipse導出(Export)功能將MapReduce打包。打包後將jar包上傳到ODPS中。在分布式環境下執行MapReduce,詳情請參考 快速入門 。
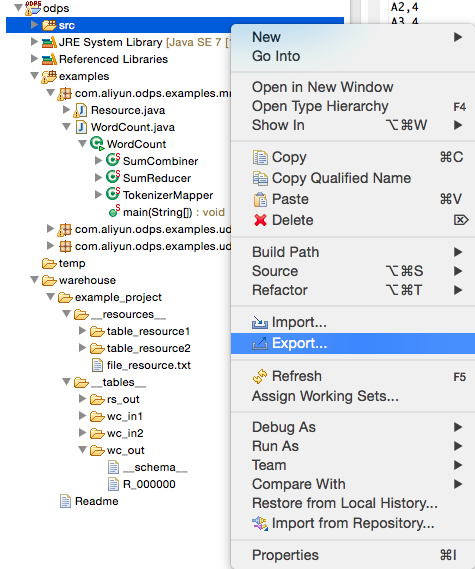
本地調試通過後,用戶可以通過Eclipse的Export功能將代碼打成jar包,供後續分布式環境使用。在本示例中,我們將程序包命名為mr-examples.jar。選擇src目錄,點擊Export:
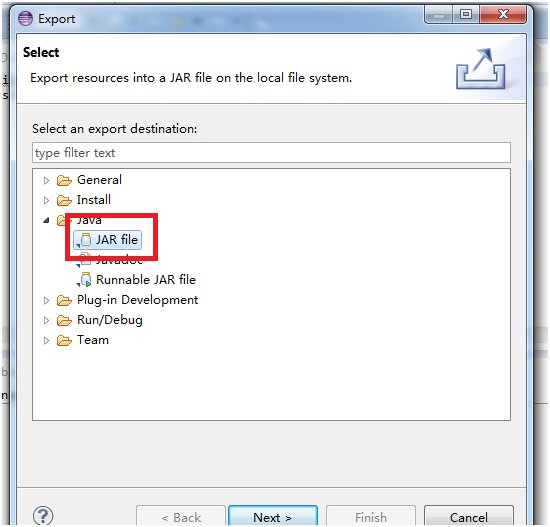
選擇導出模式為Jar File:
僅需要導出src目錄下package(com.aliyun.odps.mapred.open.example),Jar File名稱指定為”mr-examples.jar”:

確認後,導出成功。
如果用戶想在本地模擬新建Project,可以在warehouse下麵,創建一個新的子目錄(與example_project平級的目錄),目錄層次結構為:
<warehouse>|____example_project(項目空間目錄)|____ <__tables__>| |__table_name1(非分區表)| | |____ data(文件)| | || | |____ <__schema__> (文件)| || |__table_name2(分區表)| |____ partition_name=partition_value(分區目錄)| | |____ data(文件)| || |____ <__schema__> (文件)||____ <__resources__>||___table_resource_name (表資源)| |____<__ref__>||___ file_resource_name(文件資源)
schema文件示例:
非分區表:project=project_nametable=table_namecolumns=col1:BIGINT,col2:DOUBLE,col3:BOOLEAN,col4:DATETIME,col5:STRING分區表:project=project_nametable=table_namecolumns=col1:BIGINT,col2:DOUBLE,col3:BOOLEAN,col4:DATETIME,col5:STRINGpartitions=col1:BIGINT,col2:DOUBLE,col3:BOOLEAN,col4:DATETIME,col5:STRING注:當前支持5種數據格式:bigint,double,boolean,datetime,string, 對應到java中的數據類型-long,double,boolean,java.util.Date,java.lang.String。
data文件示例:
1,1.1,true,2015-06-04 11:22:42 896,hello worldN,N,N,N,N注:時間格式精確到毫秒級別,所有類型用N表示null。
注解:
- 本地模式運行MapReduce程序,默認情況下先到warehouse下查找相應的數據表或資源,如果表或資源不存在會到服務器上下載相應的數據存入warehouse目錄下,再以本地模式運行。
- 運行完MapReduce後,請刷新warehouse目錄,才能看到生成的結果
最後更新:2016-11-23 17:16:04
上一篇: 創建ODPS工程__Eclipse開發插件_工具_大數據計算服務-阿裏雲
創建ODPS工程__Eclipse開發插件_工具_大數據計算服務-阿裏雲
下一篇: UDF開發插件介紹__Eclipse開發插件_工具_大數據計算服務-阿裏雲
- 更新水印模版__水印模板接口_API使用手冊_媒體轉碼-阿裏雲
- 企業郵箱 在Foxmail 7.0上POP3/IMAP協議設置方法__客戶端使用_郵箱常見問題_企業郵箱-阿裏雲
- DescribeHealthStatus__BackendServer相關API_API 參考_負載均衡-阿裏雲
- 相關限製__標簽管理_用戶指南_負載均衡-阿裏雲
- E-MapReduce監控__雲服務監控_用戶指南_雲監控-阿裏雲
- 阿裏雲與芯訊通SIMCom——互聯網生態與垂直行業的深度融合
- 專屬賬號申請流程?__充值介紹_賬戶資產_財務-阿裏雲
- 地域___產品簡介_雲服務器 ECS-阿裏雲
- Dashboard概覽__Dashboard_用戶指南_雲監控-阿裏雲
- rolling_updates__服務編排文檔_用戶指南_容器服務-阿裏雲
相關內容
- 常見錯誤說明__附錄_大數據計算服務-阿裏雲
- 發送短信接口__API使用手冊_短信服務-阿裏雲
- 接口文檔__Android_安全組件教程_移動安全-阿裏雲
- 運營商錯誤碼(聯通)__常見問題_短信服務-阿裏雲
- 設置短信模板__使用手冊_短信服務-阿裏雲
- OSS 權限問題及排查__常見錯誤及排除_最佳實踐_對象存儲 OSS-阿裏雲
- 消息通知__操作指南_批量計算-阿裏雲
- 設備端快速接入(MQTT)__快速開始_阿裏雲物聯網套件-阿裏雲
- 查詢API調用流量數據__API管理相關接口_API_API 網關-阿裏雲
- 使用STS訪問__JavaScript-SDK_SDK 參考_對象存儲 OSS-阿裏雲