![]() 288
288
![]()
![]() 阿裏雲
阿裏雲
日誌服務監控指標__常見問題_日誌服務-阿裏雲
監控數據入口請參考LogHub監控章節。
- 寫入/讀取流量
- 含義:每個日誌庫(logstore)寫入、以及讀取實時情況
- 單位:Bytes/min
- 含義:統計該logStore通過ilogtail和SDK、API等讀寫實時流量,大小為傳輸大小(壓縮情況下為壓縮後),每分鍾統計一個點,單位為字節/分鍾。
- 原始數據大小
- 含義:每個Logstore寫入數據原始大小(壓縮前)
- 單位:Byte/min
- 總體QPS
- 含義:所有操作QPS,每分鍾統計一個點
- 單位:Count/Min
- 操作次數
- 含義:統計用戶的各種操作對應的QPS,每分鍾統計一個點
- 單位:次/分鍾(Count/Min)
- 所有的操作包括:
- 寫入操作:
- PostLogStoreLogs :0.5API以後版本接口。
- PutData : 0.4 API以前版本接口。
- 根據關鍵字查詢:
- GetLogStoreHistogram: 查詢關鍵字分布情況,0.5API以後版本接口。
- GetLogStoreLogs: 查詢關鍵字命中日誌,0.5API以後版本接口。
- GetDataMeta : 同GetLogStoreHistogram,為0.4API以前版本接口。
- GetData : 同GetLogStoreLogs,為0.4API以前版本接口。
- 批量獲取數據:
- GetCursorOrData:該操作包含了獲取Cursor和批量獲取數據兩種方法。
- ListShards:獲取一個LogStore下所有的Shard。
- List操作:
- ListLogStoreLogs:遍曆一個project下所有的LogStore。
- ListCategory:同ListLogStoreLogs,為0.4API以前版本接口。
- ListLogStoreTopics:遍曆一個Logstore下所有的Topic。
- 寫入操作:
- 服務狀態
- 含義:該視圖統計用戶的各種操作返回的HTTP 狀態碼對應的QPS,方便用戶根據錯誤的返回碼來判斷操作異常,及時調整程序。
- 各狀態碼:
- 200:為正常的返回碼,表示操作成功。
- 400:錯誤的參數,包括Host,Content-length,APIVersion,RequestTimeExpired,查詢時間範圍,Reverse,AcceptEncoding,AcceptContentType,Shard ,Cursor,PostBody,Paramter,ContentType等方麵的錯誤。
- 401:鑒權失敗,包括AccessKeyId不存在、簽名不匹配、或者簽名賬戶沒有操作權限,請到SLSweb上查看project權限列表,是否包含了該AK。
- 403: 超過預定Quota,包括能夠創建的LogStore個數、Shard總數、以及讀寫操作的每分鍾限額,請根據返回的Message判斷發生了哪種錯誤。
- 404:請求的資源不存在,包括project、 LogStore、Topic 、User等資源。
- 405:錯誤的操作方法,請檢查請求的URL路徑。
- 500:服務端錯誤,請重試。
- 502:服務端錯誤,請重試。
- 客戶端解析成功流量
- 含義:Logtail收集成功的日誌大小,為原始數據大小
- 單位:字節
- 客戶端(Logtail)解析成功行數
- 含義:Logtail收集成功的日誌的行數
- 單位: 行
- 客戶端解析失敗行數
- 含義:Logtail收集日誌過程中,采集出錯的行數大小,如果該視圖有數據,表示有錯誤發生
- 單位:行
- 客戶端錯誤次數
- 含義:Logtail收集日誌過程中,出現所有收集錯誤的IP總數
- 單位:次
- 發生客戶端錯誤機器數
- 含義:Logtail收集日誌過程中,出現收集錯誤的告警次數
- 單位:個
- 錯誤IP統計(Count/5min)
- 含義:分類別展示各種采集錯誤發生的IP數,各種錯誤包括:
- LOGFILE_PERMINSSION_ALARM:沒有權限打開日誌文件。
- SENDER_BUFFER_FULL_ALARM:數據采集速度超過了網絡發送速度,數據被丟棄。
- INOTIFY_DIR_NUM_LIMIT_ALARM(INOTIFY_DIR_QUOTA_ALARM):監控的目錄個數超過了3000個,請把監控的根目錄設置成更低層目錄。
- DISCARD_DATA_ALARM:數據丟失,因為數據時間在係統時間之前15分鍾,請保證新寫入日誌文件的數據是在15分鍾之內的。
- MULTI_CONFIG_MATCH_ALARM:有多個配置在收集同一個文件,logtail會隨機選擇一個日誌文件進行收集,另一個配置則收集不到數據。
- REGISTER_INOTIFY_FAIL_ALARM:注冊inotify事件失敗,具體原因請查看logtail日誌。
- LOGDIR_PERMINSSION_ALARM:沒有權限打開監控目錄。
- REGEX_MATCH_ALARM:正則式匹配錯誤,請調整正則式。
- ENCODING_CONVERT_ALARM:轉換日誌編碼格式時出現錯誤,具體原因請查看logtail日誌。
- PARSE_LOG_FAIL_ALARM:解析日誌錯誤,一般是行首正則表達式錯誤或單條日誌超過512KB導致的日誌分行錯誤,請查看Logtail日誌確定原因,如行首正則表達式錯誤請調整配置。
- DISCARD_DATA_ALARM:丟棄數據,Logtail發送數據到日誌服務失敗且寫本地緩存文件失敗導致,可能的原因是日誌文件產生較快但寫磁盤緩存文件較慢。
- SEND_DATA_FAIL_ALARM:解析完成的日誌數據發送日誌服務失敗,請查看Logtail日誌發送數據失敗相關ErrorCode和ErrorMessage,常見的錯誤有服務端Quota超限、客戶端網絡異常等。
- PARSE_TIME_FAIL_ALARM:解析日誌time字段出錯,Logtail根據正則表達式解析出來的time字段按照時間格式配置無法解析成功,請修改配置。
- OUTDATED_LOG_ALARM:Logtail丟棄曆史數據,請保證當前寫入日誌數據的時間與係統時間相差在5分鍾以內。
- 請根據具體錯誤請找到出錯IP,登錄機器查看/usr/logtail/ilogtail.LOG查看錯誤原因
- 含義:分類別展示各種采集錯誤發生的IP數,各種錯誤包括:
使用監控+報警
Logtail日誌是否完整收集?
客戶端(Logtail)在運行過程中,可能會因設置不正確產生錯誤:例如某些日誌格式不匹配,一個日誌文件被重複收集等(Logtail場景問題)。為了及時發現這種情況,我們可以對客戶端解析失敗行數、客戶端錯誤次數等指標進行監控,以及時發現這類問題。步驟如下:
- 打開LogHub雲監控頁麵,參考LogHub監控章節。
- 選擇關心的Logstore,新建報警規則:
- 選擇”客戶端解析錯誤”
- 設置規則,當出錯誤後報警
- 設置報警短信接收人進行報警
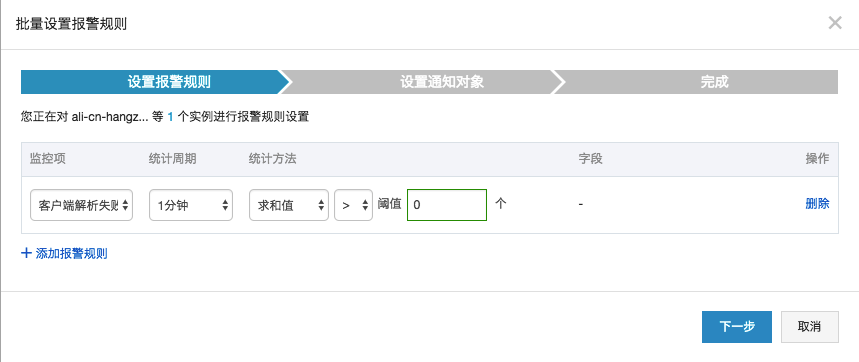
- 除此之外,還可以根據Logtail其他錯誤項進行報警,第一時間發現各類日誌收集過程中發現的問題
Logstore下Shard資源是否足夠
Logstore下每個Shard提供5MB/S (1000次/S) 寫入能力,這個數值對於大部分用戶而言都是足夠的,在超過時日誌服務會盡可能去服務(非拒絕)你的請求,但在高峰期間不保證超出部分可用性。如果你的日誌量非常大,需要添加更多Shard,可以在控製台(日誌消費/修改)中進行調整。在之前可以設置logstore出入流量報警以檢測該情況。可以設置Logstore流量報警以檢測該情況,步驟如下:
- 方案1:對流量預警
- 打開LogHub雲監控頁麵,參考LogHub監控章節。
- 選擇關心的Logstore,新建報警規則:
- 選擇”原始數據大小”
- 設置規則,超過25GB/Min後進行報警
- 設置報警短信接收人進行報警
- 方案2:設置狀態碼報警
- 打開LogHub雲監控頁麵,參考LogHub監控章節。
- 選擇關心的Logstore,新建報警規則:
- 選擇”服務狀態”,status填寫403(流量超過閾值)
- 設置規則,超過25GB/Min後進行報警
- 設置報警短信接收人進行報警
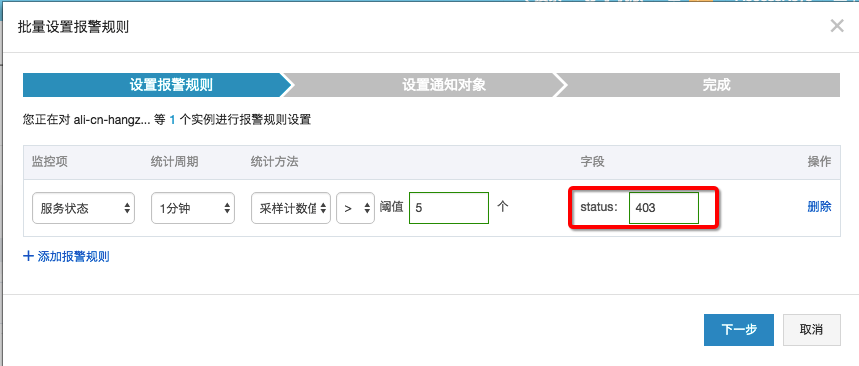
- Project Quota是否足夠 每個Project默認寫入限製為30GB/分鍾(原始數據大小),這個數值主要目的是為了保護用戶因程序錯誤產生大量日誌設計,在一般場景中對於大部分用戶都是足夠的。如果你的日誌量非常大,可能會超過限製,可以通過工單聯係我們調整大這個數值。Logstore流量報警與預警步驟如上。
最後更新:2016-11-24 11:23:47
上一篇: 日誌消費與查詢區別__常見問題_日誌服務-阿裏雲
日誌消費與查詢區別__常見問題_日誌服務-阿裏雲
下一篇: kafka用戶遷移__常見問題_日誌服務-阿裏雲
- DRDS讀寫分離__開發手冊_分布式關係型數據庫 DRDS-阿裏雲
- RDS實例間的數據遷移__數據遷移_用戶指南_數據傳輸-阿裏雲
- ActionTrail現在支持哪些產品?__常見問題_常見問題_操作審計-阿裏雲
- 新建路由器接口__高速通道相關接口_API 參考_雲服務器 ECS-阿裏雲
- 請求簽名__API-Reference_日誌服務-阿裏雲
- 管理本地集群__集群管理_用戶指南_容器服務-阿裏雲
- FileZilla使用手冊__網站上傳/下載_使用指南_雲虛機主機-阿裏雲
- 升級和續費__購買指南_對象存儲 OSS-阿裏雲
- 結合雲解析實現跨地域負載均衡__最佳實踐_負載均衡-阿裏雲
- 對象存儲(OSS、七牛等)數據遷移NAS工具__數據遷移工具_常用工具_文件存儲-阿裏雲
相關內容
- 常見錯誤說明__附錄_大數據計算服務-阿裏雲
- 發送短信接口__API使用手冊_短信服務-阿裏雲
- 接口文檔__Android_安全組件教程_移動安全-阿裏雲
- 運營商錯誤碼(聯通)__常見問題_短信服務-阿裏雲
- 設置短信模板__使用手冊_短信服務-阿裏雲
- OSS 權限問題及排查__常見錯誤及排除_最佳實踐_對象存儲 OSS-阿裏雲
- 消息通知__操作指南_批量計算-阿裏雲
- 設備端快速接入(MQTT)__快速開始_阿裏雲物聯網套件-阿裏雲
- 查詢API調用流量數據__API管理相關接口_API_API 網關-阿裏雲
- 使用STS訪問__JavaScript-SDK_SDK 參考_對象存儲 OSS-阿裏雲