![]() 482
482
![]()
![]() 阿里云
阿里云
MapReduce 开发手册__Hadoop_开发人员指南_E-MapReduce-阿里云
在 MapReduce 中使用 OSS
要在 MapReduce 中读写 OSS,需要配置如下的参数
conf.set("fs.oss.accessKeyId", "${accessKeyId}");conf.set("fs.oss.accessKeySecret", "${accessKeySecret}");conf.set("fs.oss.endpoint","${endpoint}");
参数说明:
${accessKeyId}: 您账号的 AccessKeyId。
${accessKeySecret}: 该 AccessKeyId 对应的密钥。
${endpoint}: 访问 OSS 使用的网络,由您集群所在的 region 决定,当然对应的 OSS 也需要是在集群对应的 region。
具体的值请参考 OSS Endpoint
Word Count
以下示例介绍了如何从 OSS 中读取文本,然后统计其中单词的数量。其操作步骤如下:
程序编写。以 JAVA 代码为例,将 Hadoop 官网 WordCount 例子做如下修改。对该实例的修改只是在代码中添加了 Access Key ID 和 Access Key Secret 的配置,以便作业有权限访问 OSS 文件。
package org.apache.hadoop.examples;import java.io.IOException;import java.util.StringTokenizer;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.Mapper;import org.apache.hadoop.mapreduce.Reducer;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import org.apache.hadoop.util.GenericOptionsParser;public class EmrWordCount {public static class TokenizerMapperextends Mapper<Object, Text, Text, IntWritable>{private final static IntWritable one = new IntWritable(1);private Text word = new Text();public void map(Object key, Text value, Context context) throws IOException, InterruptedException {StringTokenizer itr = new StringTokenizer(value.toString());while (itr.hasMoreTokens()) {word.set(itr.nextToken());context.write(word, one);}}}public static class IntSumReducerextends Reducer<Text,IntWritable,Text,IntWritable> {private IntWritable result = new IntWritable();public void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException {int sum = 0;for (IntWritable val : values) {sum += val.get();}result.set(sum);context.write(key, result);}}public static void main(String[] args) throws Exception {Configuration conf = new Configuration();String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();if (otherArgs.length < 2) {System.err.println("Usage: wordcount <in> [<in>...] <out>");System.exit(2);}conf.set("fs.oss.accessKeyId", "${accessKeyId}");conf.set("fs.oss.accessKeySecret", "${accessKeySecret}");conf.set("fs.oss.endpoint","${endpoint}");Job job = Job.getInstance(conf, "word count");job.setJarByClass(EmrWordCount.class);job.setMapperClass(TokenizerMapper.class);job.setCombinerClass(IntSumReducer.class);job.setReducerClass(IntSumReducer.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);for (int i = 0; i < otherArgs.length - 1; ++i) {FileInputFormat.addInputPath(job, new Path(otherArgs[i]));}FileOutputFormat.setOutputPath(job,new Path(otherArgs[otherArgs.length - 1]));System.exit(job.waitForCompletion(true) ? 0 : 1);}}
编译程序。首先要将 jdk 和 Hadoop 环境配置好,然后进行如下操作:
mkdir wordcount_classesjavac -classpath ${HADOOP_HOME}/share/hadoop/common/hadoop-common-2.6.0.jar:${HADOOP_HOME}/share/hadoop/mapreduce/hadoop-mapreduce-client-core-2.6.0.jar:${HADOOP_HOME}/share/hadoop/common/lib/commons-cli-1.2.jar -d wordcount_classes EmrWordCount.javajar cvf wordcount.jar -C wordcount_classes .
创建作业。
将上一步打好的 jar 文件上传到 OSS,具体可登录 OSS 官网进行操作。假设 jar 文件在 OSS 上的路径为 oss://emr/jars/wordcount.jar, 输入输出路径分别为 oss://emr/data/WordCount/Input 和 oss://emr/data/WordCount/Output。
在 E-MapReduce作业 中创建如下作业:
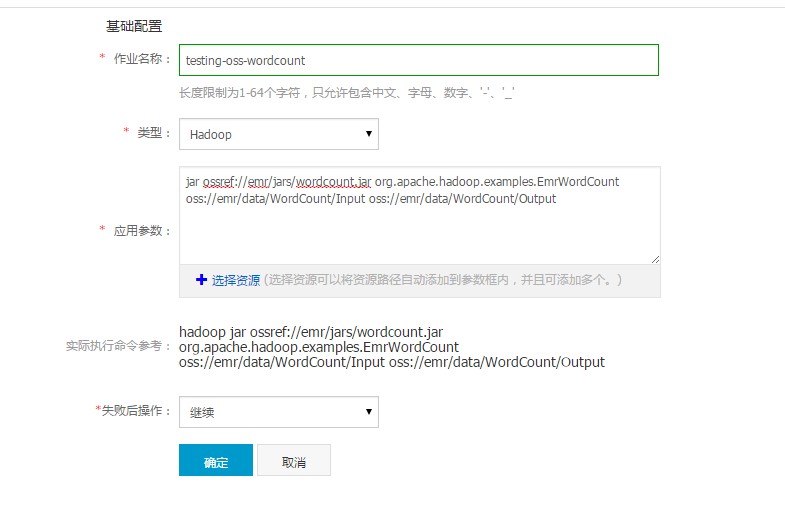
创建执行计划。在 E-MapReduce 执行计划中创建执行计划,将上一步创建好的作业添加到执行计划中,策略选择“立即执行”,这样 wordcount 作业就会在选定集群中运行起来了。

使用 Maven 工程来管理 MR 作业
当您的工程规模越来越大时,会变得非常复杂,不易管理。我们推荐你采用类似 Maven 这样的软件项目管理工具来进行管理。其操作步骤如下:
安装 Maven。首先确保您已经安装了 Maven。
生成工程框架。在您的工程根目录处(假设您的工程开发根目录位置是 D:/workspace)执行如下命令:
mvn archetype:generate -DgroupId=com.aliyun.emr.hadoop.examples -DartifactId=wordcountv2 -DarchetypeArtifactId=maven-archetype-quickstart -DinteractiveMode=false
mvn 会自动生成一个空的 Sample 工程位于 D:/workspace/wordcountv2(和您指定的 artifactId 一致),里面包含一个简单的 pom.xml 和 App 类(类的包路径和您指定的 groupId 一致)。
加入 Hadoop 依赖。使用任意 IDE 打开这个工程,编辑 pom.xml 文件。在 dependencies 内添加如下内容:
<dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-mapreduce-client-common</artifactId><version>2.6.0</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><version>2.6.0</version></dependency>
编写代码。在 com.aliyun.emr.hadoop.examples 包下和 App 类平行的位置添加新类 WordCount2.java。内容如下:
package com.aliyun.emr.hadoop.examples;import java.io.BufferedReader;import java.io.FileReader;import java.io.IOException;import java.net.URI;import java.util.ArrayList;import java.util.HashSet;import java.util.List;import java.util.Set;import java.util.StringTokenizer;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.Mapper;import org.apache.hadoop.mapreduce.Reducer;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import org.apache.hadoop.mapreduce.Counter;import org.apache.hadoop.util.GenericOptionsParser;import org.apache.hadoop.util.StringUtils;public class WordCount2 {public static class TokenizerMapperextends Mapper<Object, Text, Text, IntWritable>{static enum CountersEnum { INPUT_WORDS }private final static IntWritable one = new IntWritable(1);private Text word = new Text();private boolean caseSensitive;private Set<String> patternsToSkip = new HashSet<String>();private Configuration conf;private BufferedReader fis;@Overridepublic void setup(Context context) throws IOException,InterruptedException {conf = context.getConfiguration();caseSensitive = conf.getBoolean("wordcount.case.sensitive", true);if (conf.getBoolean("wordcount.skip.patterns", true)) {URI[] patternsURIs = Job.getInstance(conf).getCacheFiles();for (URI patternsURI : patternsURIs) {Path patternsPath = new Path(patternsURI.getPath());String patternsFileName = patternsPath.getName().toString();parseSkipFile(patternsFileName);}}}private void parseSkipFile(String fileName) {try {fis = new BufferedReader(new FileReader(fileName));String pattern = null;while ((pattern = fis.readLine()) != null) {patternsToSkip.add(pattern);}} catch (IOException ioe) {System.err.println("Caught exception while parsing the cached file '"+ StringUtils.stringifyException(ioe));}}@Overridepublic void map(Object key, Text value, Context context) throws IOException, InterruptedException {String line = (caseSensitive) ?value.toString() : value.toString().toLowerCase();for (String pattern : patternsToSkip) {line = line.replaceAll(pattern, "");}StringTokenizer itr = new StringTokenizer(line);while (itr.hasMoreTokens()) {word.set(itr.nextToken());context.write(word, one);Counter counter = context.getCounter(CountersEnum.class.getName(),CountersEnum.INPUT_WORDS.toString());counter.increment(1);}}}public static class IntSumReducerextends Reducer<Text,IntWritable,Text,IntWritable> {private IntWritable result = new IntWritable();public void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException {int sum = 0;for (IntWritable val : values) {sum += val.get();}result.set(sum);context.write(key, result);}}public static void main(String[] args) throws Exception {Configuration conf = new Configuration();conf.set("fs.oss.accessKeyId", "${accessKeyId}");conf.set("fs.oss.accessKeySecret", "${accessKeySecret}");conf.set("fs.oss.endpoint","${endpoint}");GenericOptionsParser optionParser = new GenericOptionsParser(conf, args);String[] remainingArgs = optionParser.getRemainingArgs();if (!(remainingArgs.length != 2 || remainingArgs.length != 4)) {System.err.println("Usage: wordcount <in> <out> [-skip skipPatternFile]");System.exit(2);}Job job = Job.getInstance(conf, "word count");job.setJarByClass(WordCount2.class);job.setMapperClass(TokenizerMapper.class);job.setCombinerClass(IntSumReducer.class);job.setReducerClass(IntSumReducer.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);List<String> otherArgs = new ArrayList<String>();for (int i=0; i < remainingArgs.length; ++i) {if ("-skip".equals(remainingArgs[i])) {job.addCacheFile(new Path(EMapReduceOSSUtil.buildOSSCompleteUri(remainingArgs[++i], conf)).toUri());job.getConfiguration().setBoolean("wordcount.skip.patterns", true);} else {otherArgs.add(remainingArgs[i]);}}FileInputFormat.addInputPath(job, new Path(EMapReduceOSSUtil.buildOSSCompleteUri(otherArgs.get(0), conf)));FileOutputFormat.setOutputPath(job, new Path(EMapReduceOSSUtil.buildOSSCompleteUri(otherArgs.get(1), conf)));System.exit(job.waitForCompletion(true) ? 0 : 1);}}
其中的 EMapReduceOSSUtil 类代码请参见如下示例,放在和 WordCount2 相同目录:
package com.aliyun.emr.hadoop.examples;import org.apache.hadoop.conf.Configuration;public class EMapReduceOSSUtil {private static String SCHEMA = "oss://";private static String AKSEP = ":";private static String BKTSEP = "@";private static String EPSEP = ".";private static String HTTP_HEADER = "https://";/*** complete OSS uri* convert uri like: oss://bucket/path to oss://accessKeyId:accessKeySecret@bucket.endpoint/path* ossref do not need this** @param oriUri original OSS uri*/public static String buildOSSCompleteUri(String oriUri, String akId, String akSecret, String endpoint) {if (akId == null) {System.err.println("miss accessKeyId");return oriUri;}if (akSecret == null) {System.err.println("miss accessKeySecret");return oriUri;}if (endpoint == null) {System.err.println("miss endpoint");return oriUri;}int index = oriUri.indexOf(SCHEMA);if (index == -1 || index != 0) {return oriUri;}int bucketIndex = index + SCHEMA.length();int pathIndex = oriUri.indexOf("/", bucketIndex);String bucket = null;if (pathIndex == -1) {bucket = oriUri.substring(bucketIndex);} else {bucket = oriUri.substring(bucketIndex, pathIndex);}StringBuilder retUri = new StringBuilder();retUri.append(SCHEMA).append(akId).append(AKSEP).append(akSecret).append(BKTSEP).append(bucket).append(EPSEP).append(stripHttp(endpoint));if (pathIndex > 0) {retUri.append(oriUri.substring(pathIndex));}return retUri.toString();}public static String buildOSSCompleteUri(String oriUri, Configuration conf) {return buildOSSCompleteUri(oriUri, conf.get("fs.oss.accessKeyId"), conf.get("fs.oss.accessKeySecret"), conf.get("fs.oss.endpoint"));}private static String stripHttp(String endpoint) {if (endpoint.startsWith(HTTP_HEADER)) {return endpoint.substring(HTTP_HEADER.length());}return endpoint;}}
编译并打包上传。在工程的目录下,执行如下命令:
mvn clean package -DskipTests
您即可在工程目录的 target 目录下看到一个 wordcountv2-1.0-SNAPSHOT.jar,这个就是作业 jar 包了。请您将这个 jar 包上传到 OSS 中。
创建作业。在 E-MapReduce 中新建一个作业,请使用类似如下的参数配置:
jar ossref://yourBucket/yourPath/wordcountv2-1.0-SNAPSHOT.jar com.aliyun.emr.hadoop.examples.WordCount2 -Dwordcount.case.sensitive=true oss://yourBucket/yourPath/The_Sorrows_of_Young_Werther.txt oss://yourBucket/yourPath/output -skip oss://yourBucket/yourPath/patterns.txt
这里的 yourBucket 是您的一个 OSS bucket,yourPath 是这个 bucket 上的一个路径,需要您按照实际情况填写。请您将
oss://yourBucket/yourPath/The_Sorrows_of_Young_Werther.txt和oss://yourBucket/yourPath/patterns.txt这两个用来处理相关资源的文件下载下来并放到您的 OSS 上。作业需要资源可以从下面下载,然后放到您的 OSS 对应目录下。创建执行计划并运行。在 E-MapReduce 中创建执行计划,关联这个作业并运行。
最后更新:2016-11-23 16:03:59
上一篇: SDK-Release__Spark_开发人员指南_E-MapReduce-阿里云
SDK-Release__Spark_开发人员指南_E-MapReduce-阿里云
下一篇: Hive 开发手册__Hadoop_开发人员指南_E-MapReduce-阿里云
- 修改实例 VPC 属性__实例相关接口_API 参考_云服务器 ECS-阿里云
- 阿里云携手德施曼等ICA联盟企业联合发布《中国智能锁应用与发展白皮书》!
- 数据导入__快速入门_云数据库 Redis 版-阿里云
- InstanceAttributesType__数据类型_API 参考_云服务器 ECS-阿里云
- CreateTable__API 概览_API 参考_表格存储-阿里云
- 查询媒体信息作业__媒体信息接口_API使用手册_媒体转码-阿里云
- 企业信息安全整体解决方案 阿里云栖大会,我们来了!
- 删除伸缩组__伸缩组_用户指南_弹性伸缩-阿里云
- 修改执行计划__执行计划_API参考_E-MapReduce-阿里云
- ALIYUN::RDS::DBInstanceParameterGroup__资源列表_资源编排-阿里云
相关内容
- 常见错误说明__附录_大数据计算服务-阿里云
- 发送短信接口__API使用手册_短信服务-阿里云
- 接口文档__Android_安全组件教程_移动安全-阿里云
- 运营商错误码(联通)__常见问题_短信服务-阿里云
- 设置短信模板__使用手册_短信服务-阿里云
- OSS 权限问题及排查__常见错误及排除_最佳实践_对象存储 OSS-阿里云
- 消息通知__操作指南_批量计算-阿里云
- 设备端快速接入(MQTT)__快速开始_阿里云物联网套件-阿里云
- 查询API调用流量数据__API管理相关接口_API_API 网关-阿里云
- 使用STS访问__JavaScript-SDK_SDK 参考_对象存储 OSS-阿里云