![]() 707
707
![]()
![]() 阿里云
阿里云
统计分析__使用手册(new)_机器学习-阿里云
统计分析
目录
百分位
对一个存在的表,单列数据计算百分位
参数设置
选择需要分析的字段,仅支持double类型和bigint类型
运行结果,如下
PAI 命令
PAI -name Percentile -project algo_public -DoutputTableName="pai_temp_666_6014_1"-DcolName="euribor3m" -DinputTableName="bank_data";
- name: 组件名字
- project: project名字,用于指定算法所在空间。系统默认是algo_public,用户自己更改后系统会报错
- outputTableName: 系统执行百分位运算后自动分配的结果表
- colName:要计算百分位的列,仅支持数字型
- inputTableName: 输入表的名字
全表统计
对一个存在的表,进行全表基本统计,或者仅对选中的列做统计
PAI 命令
PAI -name stat_summary-project algo_public-DinputTableName=test_data-DoutputTableName=test_summary_out-DinputTablePartitions="ds='20160101'"-DselectColNames=col0,col1,col2-Dlifecycle=1
参数说明
| 参数名称 | 参数描述 | 参数值可选项 | 默认值 |
|---|---|---|---|
| inputTableName | 必选,输入表名 | - | - |
| outputTableName | 必选,推荐结果的输出表名 | - | - |
| inputTablePartitions | 可选,输入表的分区 | - | “” |
| selectColNames | 可选,指定需要统计的列名 | - | “” |
| lifecycle | 可选,输出结果表的生命周期 | - | 不设生命周期 |
| coreNum | 可选,指定instance的总数 | - | -1 |
| memSizePerCore | 可选,指定memory大小,范围在100~64*1024之间 | - | -1 |
输入格式:选择输入列框中可选择需要进行统计的列,默认情况下统计全部列
输出格式:输出统计结果的全部字段如下
| 列名 |
|---|
| colname |
| datatype |
| totalcount |
| count |
| missingcount |
| nancount |
| positiveinfinitycount |
| negativeinfinitycount |
| min |
| max |
| mean |
| variance |
| standarddeviation |
| standarderror |
| skewness |
| kurtosis |
| moment2 |
| moment3 |
| moment4 |
| centralmoment2 |
| centralmoment3 |
| centralmoment4 |
| sum |
| sum2 |
| sum3 |
| sum4 |
实例
测试数据
新建数据SQL
drop table if exists summary_test_input;create table summary_test_input asselect*from(select 'a' as col1, 1 as col2, 0.001 as col3 from dualunion allselect 'b' as col1, 2 as col2, 100.01 as col3 from dual) tmp;
运行命令
PAI -name stat_summary-project algo_public-DinputTableName=summary_test_input-DoutputTableName=summary_test_input_out-DselectColNames=col1,col2,col3-Dlifecycle=1;
运行结果
| colname | datatype | totalcount | count | missingcount | nancount | positiveinfinitycount | negativeinfinitycount | min | max | mean | variance | standarddeviation | standarderror | skewness | kurtosis | moment2 | moment3 | moment4 | centralmoment2 | centralmoment3 | centralmoment4 | sum | sum2 | sum3 | sum4 || col1 | string | 2 | 2 | 0 | 0 | 0 | 0 | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL || col2 | bigint | 2 | 2 | 0 | 0 | 0 | 0 | 1 | 2 | 1.5 | 0.5 | 0.7071067811865476 | 0.5 | 0 | -2 | 2.5 | 4.5 | 8.5 | 0.25 | 0 | 0.0625 | 3 | 5 | 9 | 17 || col3 | double | 2 | 2 | 0 | 0 | 0 | 0 | 0.001 | 100.01 | 50.0055 | 5000.900040500001 | 70.71704207968544 | 50.00450000000001 | 2.327677906939552e-16 | -1.999999999999999 | 5001.000050500001 | 500150.0150005006 | 50020003.00020002 | 2500.45002025 | 2.91038304567337e-11 | 6252250.303768232 | 100.011 | 10002.000101 | 1000300.030001001 | 100040006.0004 |
皮尔森系数
对输入表或分区的2列(必须为数值列),计算其pearson相关系数,结果存入输出表。
使用说明
组件的仅两个参数:输入列1、输入列2;将需要计算相关系数的两列的列名填入即可;
运行后,组件右击菜单—> 查看分析报告,如下
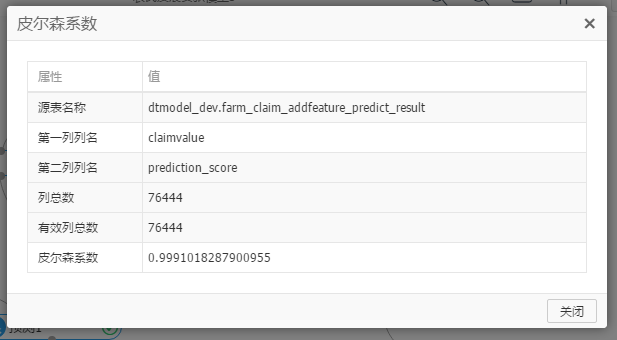 最后一列皮尔森系数值
最后一列皮尔森系数值
pai命令示例
pai -name pearson-project algo_test-DinputTableName=wpbc-Dcol1Name=f1-Dcol2Name=f2-DoutputTableName=wpbc_pear;
算法参数
| 参数key名称 | 参数描述 | 取值范围 | 是否必选,默认值/行为 |
|---|---|---|---|
| inputTableName | 输入表的表名 | 表名 | 必选 |
| inputTablePartitions | 输入表中指定哪些分区参与计算 | 格式为: partition_name=value。如果是多级格式为name1=value1/name2=value2;如果是指定多个分区,中间用’,’分开 | 输入表的所有partition |
| col1Name | 输入列1 | 列名 | 必选 |
| col2Name | 输入列2 | 列名 | 必选 |
| outputTableName | 输出结果表 | 表名 | 必选 |
直方图
对一个存在的表,单列数据计算直方图
参数设置
选择需要分析字段,支持double类型和bigint类型
查看分析报告,如下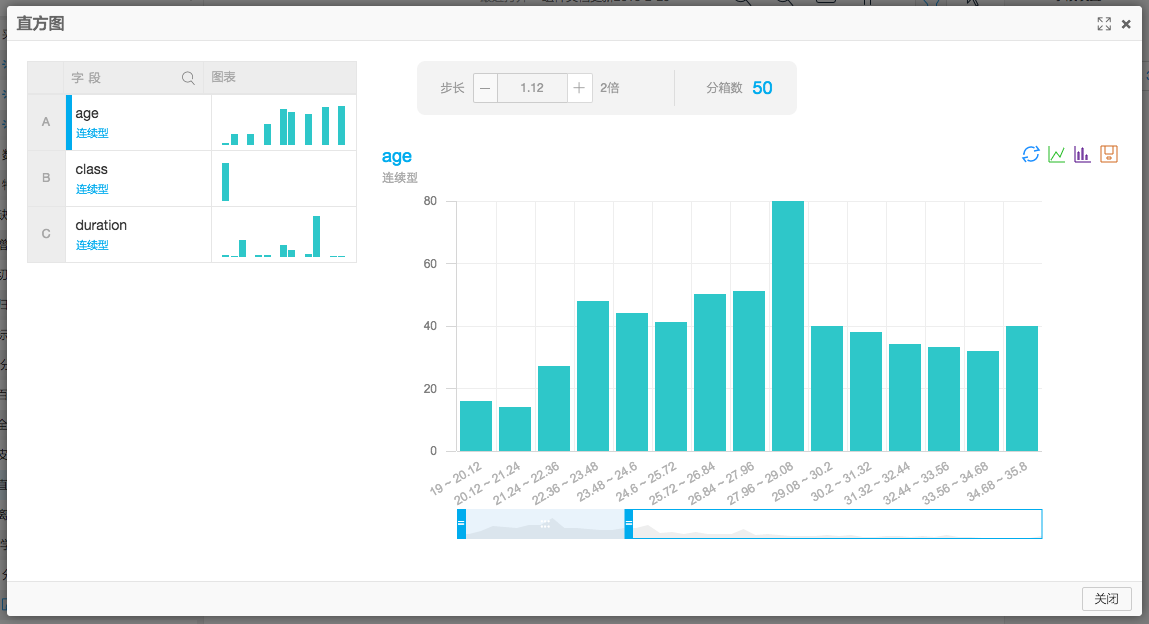 可调节步长大小,以及滑动查看直方图
可调节步长大小,以及滑动查看直方图
离散值特征分析
离散值特征分析统计离散特征的分布,gini,entropy,gini gain,infomation gain,infomation gain ratio等指标
其中计算每个离散值对应的gini,entropy
计算单列对应的gini gain,infomation gain,infomation gain ratio
gini index:
entropy:
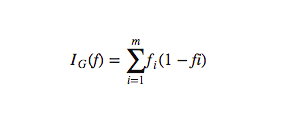
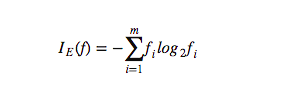
pai命令示例
PAI-name enum_feature_selection-project algo_public-DinputTableName=enumfeautreselection_input-DlabelColName=label-DfeatureColNames=col0,col1-DenableSparse=false-DoutputCntTableName=enumfeautreselection_output_cntTable-DoutputValueTableName=enumfeautreselection_output_valuetable-DoutputEnumValueTableName=enumfeautreselection_output_enumvaluetable;
算法参数
| 参数key名称 | 参数描述 | 取值范围 | 默认值 |
|---|---|---|---|
| inputTableName | 必选,输入表名 | - | - |
| inputTablePartitions | 可选,输入表选择的分区 | - | 默认选择全表 |
| featureColNames | 可选,输入表选择的列名 | - | 默认选择除label外的其他列,如果输入表为KV格式,则默认选择所有的string类型的列 |
| labelColName | 必选,label所在的列 | - | - |
| enableSparse | 可选,输入表是否是KV格式 | - | 默认为表 |
| kvFeatureColNames | 可选,KV格式的特征 | - | 默认选择全表 |
| kvDelimiter | 可选,KV之间的分隔符 | - | 默认为: |
| itemDelimiter | 可选,K和V的分隔符 | - | 默认为, |
| outputCntTableName | 必选,输出离散特征的枚举值分布数表 | - | - |
| outputValueTableName | 必选,输出离散特征的gini,entropy表 | - | - |
| outputEnumValueTableName | 必选,输出离散特征枚举值gini,entropy表 | - | - |
| lifecycle | 可选,输入表的声明周期 | - | 默认不设置声明周期 |
| coreNum | 可选,总得core个数 | - | 默认自动设置 |
| memSizePerCore | 可选,单个core对应的内存数量,单位为M | - | 默认为自动设置 |
示例
测试数据
新建数据SQL
drop table if exists enum_feature_selection_test_input;create table enum_feature_selection_test_inputasselect*from(select'00' as col_string,1 as col_bigint,0.0 as col_doublefrom dualunion allselectcast(null as string) as col_string,0 as col_bigint,0.0 as col_doublefrom dualunion allselect'01' as col_string,0 as col_bigint,1.0 as col_doublefrom dualunion allselect'01' as col_string,1 as col_bigint,cast(null as double) as col_doublefrom dualunion allselect'01' as col_string,1 as col_bigint,1.0 as col_doublefrom dualunion allselect'00' as col_string,0 as col_bigint,0.0 as col_doublefrom dual) tmp;
输入数据说明
+------------+------------+------------+| col_string | col_bigint | col_double |+------------+------------+------------+| 01 | 1 | 1.0 || 01 | 0 | 1.0 || 01 | 1 | NULL || NULL | 0 | 0.0 || 00 | 1 | 0.0 || 00 | 0 | 0.0 |+------------+------------+------------+
运行命令
drop table if exists enum_feature_selection_test_input_enum_value_output;drop table if exists enum_feature_selection_test_input_cnt_output;drop table if exists enum_feature_selection_test_input_value_output;PAI -name enum_feature_selection -project algo_public -DitemDelimiter=":" -Dlifecycle="28" -DoutputValueTableName="enum_feature_selection_test_input_value_output" -DkvDelimiter="," -DlabelColName="col_bigint" -DfeatureColNames="col_double,col_string" -DoutputEnumValueTableName="enum_feature_selection_test_input_enum_value_output" -DenableSparse="false" -DinputTableName="enum_feature_selection_test_input" -DoutputCntTableName="enum_feature_selection_test_input_cnt_output";
界面
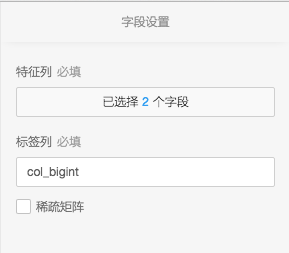
参数界面
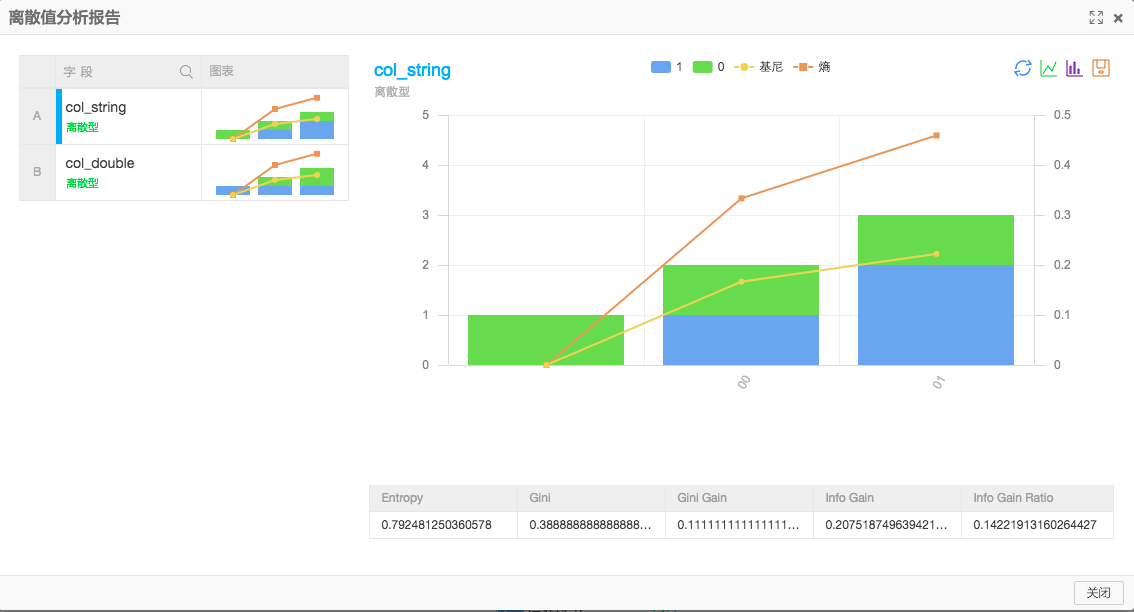
界面运行结果
运行结果
enum_feature_selection_test_input_cnt_output
+------------+------------+------------+------------+| colname | colvalue | labelvalue | cnt |+------------+------------+------------+------------+| col_double | NULL | 1 | 1 || col_double | 0 | 0 | 2 || col_double | 0 | 1 | 1 || col_double | 1 | 0 | 1 || col_double | 1 | 1 | 1 || col_string | NULL | 0 | 1 || col_string | 00 | 0 | 1 || col_string | 00 | 1 | 1 || col_string | 01 | 0 | 1 || col_string | 01 | 1 | 2 |+------------+------------+------------+------------+
enum_feature_selection_test_input_value_output
+------------+------------+------------+------------+------------+---------------+| colname | gini | entropy | infogain | ginigain | infogainratio |+------------+------------+------------+------------+------------+---------------+| col_double | 0.3888888888888889 | 0.792481250360578 | 0.20751874963942196 | 0.1111111111111111 | 0.14221913160264427 || col_string | 0.38888888888888884 | 0.792481250360578 | 0.20751874963942196 | 0.11111111111111116 | 0.14221913160264427 |+------------+------------+------------+------------+------------+---------------+
enum_feature_selection_test_input_enum_value_output
+------------+------------+------------+------------+| colname | colvalue | gini | entropy |+------------+------------+------------+------------+| col_double | NULL | 0.0 | 0.0 || col_double | 0 | 0.22222222222222224 | 0.4591479170272448 || col_double | 1 | 0.16666666666666666 | 0.3333333333333333 || col_string | NULL | 0.0 | 0.0 || col_string | 00 | 0.16666666666666666 | 0.3333333333333333 || col_string | 01 | 0.2222222222222222 | 0.4591479170272448 |+------------+------------+------------+------------+
T检验
单样本T检验是检验某个变量的总体均值和某指定值之间是否存在显着差异。T检验的前提是样本总体服从正态分布。
pai命令示例
pai -name t_test -project algo_public-DxTableName=pai_t_test_all_type-DxColName=col1_double-DoutputTableName=pai_t_test_out-DxTablePartitions=ds=2010/dt=1-Dalternative=less-Dmu=47-DconfidenceLevel=0.95
算法参数
| 参数名称 | 参数描述 | 取值范围 | 是否必选,默认值/行为 |
|---|---|---|---|
| xTableName | 输入表x | 表名 | 必选 |
| xColName | 需要做t检验的列 | 列名,只能是double或者bigint | 必选 |
| outputTableName | 输出表 | 不存在的表名 | 必选 |
| xTablePartitions | 输入表x的分区列表 | 分区列表 | 可选, 默认值:”” |
| alternative | 对立假设 | two.sided, less, greater” | 可选, 默认值: two.sided |
| mu | 假设的均值 | double | 可选,默认值:0 |
| confidenceLevel | 置信度 | 0.8,0.9,0.95,0.99,0.995,0.999 | 可选,默认值:0.95 |
输出说明
输出是一个表,只有一行一列,是json格式。
{"AlternativeHypthesis": "mean not equals to 0","ConfidenceInterval": "(44.72234194006504, 46.27765805993496)","ConfidenceLevel": 0.95,"alpha": 0.05,"df": 99,"mean": 45.5,"p": 0,"stdDeviation": 3.919647479510927,"t": 116.081867662439}
卡方检验
卡方拟合性检验是检验单个多项分类名义型变量各分类间的实际观测次数与理论次数之间是否一致的问题,其零假设是观测次数与理论次数之间无差异。
pai命令示例
PAI -name chisq_test-project algo_public-DinputTableName=pai_chisq_test_input-DcolName=f0-DprobConfig=0:0.3,1:0.7-DoutputTableName=pai_chisq_test_output0-DoutputDetailTableName=pai_chisq_test_output0_detail
算法参数
| 参数名称 | 参数描述 | 取值范围 | 是否必选,默认值/行为 |
|---|---|---|---|
| inputTableName | 输入表 | 表名 | 必选 |
| colName | 需要做卡方检验的列 | 列名 | 必选 |
| outputTableName | 输出表 | 不存在的表名 | 必选 |
| outputDetailTableName | 输出detail表 | 不存在的表名 | 必选 |
| inputTablePartitions | 输入表的分区列表 | 分区列表 | 可选, 默认值:”” |
| probConfig | 类别概率配置 | kv对,格式 类别:概率,类别:概率…所有概率和为1 | 可选, 默认为所有类别概率相等 |
示例
测试数据
create table pai_chisq_test_input asselect * from(select '1' as f0,'2' as f1 from dualunion allselect '1' as f0,'3' as f1 from dualunion allselect '1' as f0,'4' as f1 from dualunion allselect '0' as f0,'3' as f1 from dualunion allselect '0' as f0,'4' as f1 from dual)tmp;
pai命令
PAI -name chisq_test-project algo_public-DinputTableName=pai_chisq_test_input-DcolName=f0-DprobConfig=0:0.3,1:0.7-DoutputTableName=pai_chisq_test_output0-DoutputDetailTableName=pai_chisq_test_output0_detail
输出说明
输出表outputTableName,只有一行一列,是json格式。
{"Chi-Square": {"comment": "皮尔逊卡方","df": 1,"p-value": 0.75,"value": 0.2380952380952381}}
输出表outputDetailTableName,对应列:类别,观察频率(observed),期望频率(expected),标准误差(residuals = (observed-expected) / sqrt(expected) )

最后更新:2016-08-15 10:00:16
上一篇: 特征工程__使用手册(new)_机器学习-阿里云
特征工程__使用手册(new)_机器学习-阿里云
下一篇: 文本分析__使用手册(new)_机器学习-阿里云
- 阿里云如何炼就“神龙”这个“新物种”?
- ALIYUN::MarketPlace::Order__资源列表_资源编排-阿里云
- 简单路由-域名配置__服务发现和负载均衡_用户指南_容器服务-阿里云
- Job(作业)__产品概念_产品简介_数据集成-阿里云
- 查询媒体工作流__媒体工作流接口_API使用手册_视频点播-阿里云
- 转换函数__函数_SQL语法参考_云数据库 OceanBase-阿里云
- 阿里云的技术到底有多强?
- 新老版本API使用FAQ__图片处理指南_对象存储 OSS-阿里云
- GetGroup__组管理接口_RAM API文档_访问控制-阿里云
- GetCursor__日志库相关接口_API-Reference_日志服务-阿里云
相关内容
- 常见错误说明__附录_大数据计算服务-阿里云
- 发送短信接口__API使用手册_短信服务-阿里云
- 接口文档__Android_安全组件教程_移动安全-阿里云
- 运营商错误码(联通)__常见问题_短信服务-阿里云
- 设置短信模板__使用手册_短信服务-阿里云
- OSS 权限问题及排查__常见错误及排除_最佳实践_对象存储 OSS-阿里云
- 消息通知__操作指南_批量计算-阿里云
- 设备端快速接入(MQTT)__快速开始_阿里云物联网套件-阿里云
- 查询API调用流量数据__API管理相关接口_API_API 网关-阿里云
- 使用STS访问__JavaScript-SDK_SDK 参考_对象存储 OSS-阿里云