![]() 113
113
![]()
![]() 阿裏雲
阿裏雲
Hive 開發手冊__Hadoop_開發人員指南_E-MapReduce-阿裏雲
在 Hive 中使用 OSS
要在 Hive 中讀寫 OSS,需要在使用 OSS 的 URI 時加上 AccessKeyId、AccessKeySecret 以及 endpoint。如下示例介紹了如何創建一個 external 的表:
CREATE EXTERNAL TABLE eusers (userid INT)LOCATION 'oss://emr/users';
為了保證能正確訪問 OSS,這個時候需要修改這個 OSS URI 為:
CREATE EXTERNAL TABLE eusers (userid INT)LOCATION 'oss://${AccessKeyId}:${AccessKeySecret}@${bucket}.${endpoint}/users';
參數說明:
${accessKeyId}:您賬號的 accessKeyId。
${accessKeySecret}:該 accessKeyId 對應的密鑰。
${endpoint}:訪問 OSS 使用的網絡,由您集群所在的 region 決定,對應的 OSS 也需要是在集群對應的 region。
具體的值參考 OSS Endpoint
使用Tez作為計算引擎
從E-MapReduce產品版本2.1.0+開始,引入了Tez,Tez是一個用來優化處理複雜DAG調度任務的計算框架。在很多場景下可以有效的提高Hive作業的運行速度。
用戶在作業中,可以通過設置Tez作為執行引擎來優化作業,如下:
set hive.execution.engine=tez
示例 1
請參見如下步驟:
編寫如下腳本,保存為 hiveSample1.sql,並上傳到 OSS 上。
USE DEFAULT;set hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;set hive.stats.autogather=false;DROP TABLE emrusers;CREATE EXTERNAL TABLE emrusers (userid INT,movieid INT,rating INT,unixtime STRING )ROW FORMAT DELIMITEDFIELDS TERMINATED BY 't'STORED AS TEXTFILELOCATION 'oss://${AccessKeyId}:${AccessKeySecret}@${bucket}.${endpoint}/yourpath';SELECT COUNT(*) FROM emrusers;SELECT * from emrusers limit 100;SELECT movieid,count(userid) as usercount from emrusers group by movieid order by usercount desc limit 50;
測試用數據資源。您可通過下麵的地址下載 Hive 作業需要的資源,然後將其放到您 OSS 對應的目錄下。
資源下載:公共測試數據
創建作業。在 E-MapReduce 中新建一個作業,使用類似如下的參數配置:
-f ossref://${bucket}/yourpath/hiveSample1.sql
這裏的 ${bucket} 是您的一個 OSS bucket,yourPath 是這個 bucket 上的一個路徑,需要您填寫實際保存 Hive 腳本的位置。
創建執行計劃並運行。創建一個執行計劃,您可以關聯一個已有的集群,也可以自動按需創建一個,然後關聯上這個作業。請將作業保存為“手動運行”,回到界麵上就可以點擊“立即運行”來運行作業了。
示例 2
以 HiBench 中的 scan 為例,若輸入輸出來自 OSS,則需進行如下過程運行 Hive 作業,代碼修改源於 AccessKeyId、AccessKeySecret 以及存儲路徑的設置。請注意 OSS 路徑的設置形式為 oss://${accesskeyId}:${accessKeySecret}@${bucket}.${endpoint}/object/path。
請參見如下操作步驟:
編寫如下腳本。
USE DEFAULT;set hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;set mapreduce.job.maps=12;set mapreduce.job.reduces=6;set hive.stats.autogather=false;DROP TABLE uservisits;CREATE EXTERNAL TABLE uservisits (sourceIP STRING,destURL STRING,visitDate STRING,adRevenue DOUBLE,userAgent STRING,countryCode STRING,languageCode STRING,searchWord STRING,duration INT ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS SEQUENCEFILE LOCATION 'oss://${AccessKeyId}:${AccessKeySecret}@${bucket}.${endpoint}/sample-data/hive/Scan/Input/uservisits';
準備測試數據。您可通過下麵的地址下載作業需要的資源,然後將其放到您 OSS 對應的目錄下。
資源下載:uservisits
創建作業。將步驟 1 中編寫的腳本存儲到 OSS 中,假設存儲路徑為
oss://emr/jars/scan.hive,在 E-MapReduce 中創建如下作業: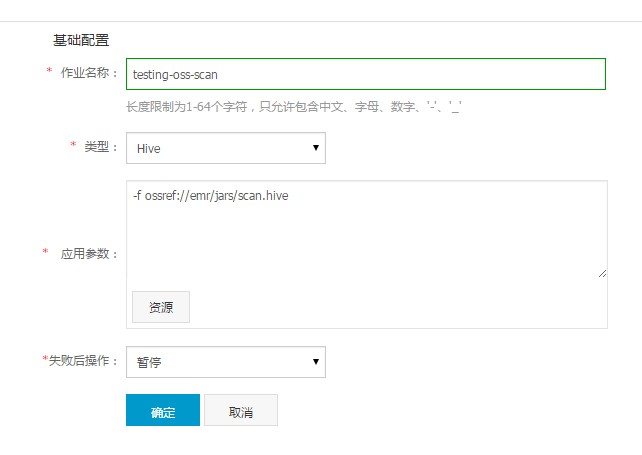
創建執行計劃並運行。創建一個執行計劃,您可以關聯一個已有的集群,也可以自動按需創建一個,然後關聯上這個作業。請將作為保存為“手動運行”,回到界麵上就可以點擊“立即運行”來運行作業了。

最後更新:2016-11-23 16:03:59
上一篇: MapReduce 開發手冊__Hadoop_開發人員指南_E-MapReduce-阿裏雲
MapReduce 開發手冊__Hadoop_開發人員指南_E-MapReduce-阿裏雲
下一篇: Pig 開發手冊__Hadoop_開發人員指南_E-MapReduce-阿裏雲
- 如何開通大數據開發套件__快速開始_大數據開發套件-阿裏雲
- 綁定輸入媒體Bucket__媒體Bucket接口_API使用手冊_視頻點播-阿裏雲
- 擴容係統盤__擴容磁盤概覽_磁盤_用戶指南_雲服務器 ECS-阿裏雲
- ActionTrail__操作事件(Event)樣例_用戶指南_操作審計-阿裏雲
- 瀏覽作業__作業管理_Console參考手冊_數據集成-阿裏雲
- 服務流程__產品簡介_安全管家服務-阿裏雲
- 使用雲服務監控__快速入門_雲監控-阿裏雲
- 自定義標簽-標簽加工及規範__進階功能_移動定向營銷_規則引擎-阿裏雲
- 刪除角色__賬號管理類 API_Open API 參考_企業級分布式應用服務 EDAS-阿裏雲
- OceanBase SQL快速概覽__SQL語法參考_雲數據庫 OceanBase-阿裏雲
相關內容
- 常見錯誤說明__附錄_大數據計算服務-阿裏雲
- 發送短信接口__API使用手冊_短信服務-阿裏雲
- 接口文檔__Android_安全組件教程_移動安全-阿裏雲
- 運營商錯誤碼(聯通)__常見問題_短信服務-阿裏雲
- 設置短信模板__使用手冊_短信服務-阿裏雲
- OSS 權限問題及排查__常見錯誤及排除_最佳實踐_對象存儲 OSS-阿裏雲
- 消息通知__操作指南_批量計算-阿裏雲
- 設備端快速接入(MQTT)__快速開始_阿裏雲物聯網套件-阿裏雲
- 查詢API調用流量數據__API管理相關接口_API_API 網關-阿裏雲
- 使用STS訪問__JavaScript-SDK_SDK 參考_對象存儲 OSS-阿裏雲