![]() 761
761
![]()
![]() 阿里云
阿里云
Java UDF__UDF_SQL_大数据计算服务-阿里云
实现UDF需要继承com.aliyun.odps.udf.UDF类,并实现evaluate方法。evaluate方法必须是非static的public方法。Evaluate方法的参数和返回值类型将作为SQL中UDF的函数签名。这意味着用户可以在UDF中实现多个evaluate方法,在调用UDF时,框架会依据UDF调用的参数类型匹配正确的evaluate方法。
下面是一个UDF的例子。
package org.alidata.odps.udf.examples;import com.aliyun.odps.udf.UDF;public final class Lower extends UDF {public String evaluate(String s) {if (s == null) { return null; }return s.toLowerCase();}}
可以通过实现void setup(ExecutionContext ctx)和void close()来分别实现UDF的初始化和结束代码。
UDF的使用方式于ODPS SQL中普通的内建函数相同,详情请参考内建函数。
UDAF
实现Java UDAF类需要继承com.aliyun.odps.udf.Aggregator,并实现如下几个接口:
public abstract class Aggregator implements ContextFunction {@Overridepublic void setup(ExecutionContext ctx) throws UDFException {}@Overridepublic void close() throws UDFException {}/*** 创建聚合Buffer* @return Writable 聚合buffer*/abstract public Writable newBuffer();/*** @param buffer 聚合buffer* @param args SQL中调用UDAF时指定的参数* @throws UDFException*/abstract public void iterate(Writable buffer, Writable[] args) throws UDFException;/*** 生成最终结果* @param buffer* @return Object UDAF的最终结果* @throws UDFException*/abstract public Writable terminate(Writable buffer) throws UDFException;abstract public void merge(Writable buffer, Writable partial) throws UDFException;}
其中最重要的是iterate,merge和terminate三个接口,UDAF的主要逻辑依赖于这三个接口的实现。此外,还需要用户实现自定义的Writable buffer。以实现求平均值avg为例,下图简要说明了在ODPS UDAF中这一函数的实现逻辑及计算流程:
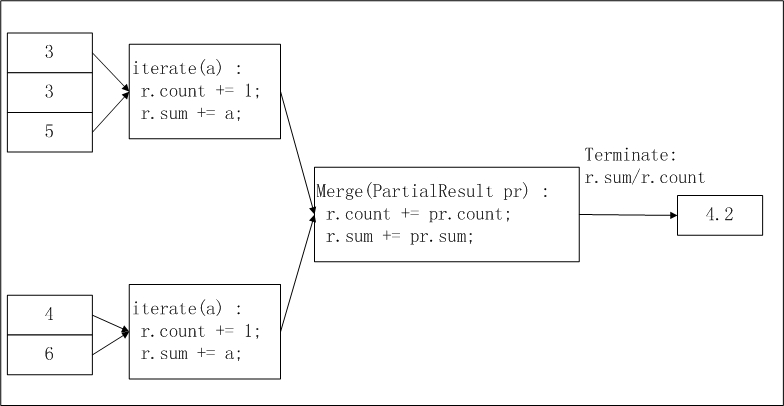
在上图中,输入数据被按照一定的大小进行分片(有关分片的描述可参考 MapReduce ),每片的大小适合一个worker在适当的时间内完成。这个分片大小的设置需要用户手动配置完成。UDAF的计算过程分为两阶段:
- 在第一阶段,每个worker统计分片内数据的个数及汇总值,我们可以将每个分片内的数据个数及汇总值视为一个中间结果;
- 在第二阶段,worker汇总上一个阶段中每个分片内的信息。在最终输出时,r.sum / r.count即是所有输入数据的平均值;
下面是一个计算平均值的UDAF的代码示例:
import java.io.DataInput;import java.io.DataOutput;import java.io.IOException;import com.aliyun.odps.io.DoubleWritable;import com.aliyun.odps.io.Writable;import com.aliyun.odps.udf.Aggregator;import com.aliyun.odps.udf.UDFException;import com.aliyun.odps.udf.annotation.Resolve;@Resolve({"double->double"})public class AggrAvg extends Aggregator {private static class AvgBuffer implements Writable {private double sum = 0;private long count = 0;@Overridepublic void write(DataOutput out) throws IOException {out.writeDouble(sum);out.writeLong(count);}@Overridepublic void readFields(DataInput in) throws IOException {sum = in.readDouble();count = in.readLong();}}private DoubleWritable ret = new DoubleWritable();@Overridepublic Writable newBuffer() {return new AvgBuffer();}@Overridepublic void iterate(Writable buffer, Writable[] args) throws UDFException {DoubleWritable arg = (DoubleWritable) args[0];AvgBuffer buf = (AvgBuffer) buffer;if (arg != null) {buf.count += 1;buf.sum += arg.get();}}@Overridepublic Writable terminate(Writable buffer) throws UDFException {AvgBuffer buf = (AvgBuffer) buffer;if (buf.count == 0) {ret.set(0);} else {ret.set(buf.sum / buf.count);}return ret;}@Overridepublic void merge(Writable buffer, Writable partial) throws UDFException {AvgBuffer buf = (AvgBuffer) buffer;AvgBuffer p = (AvgBuffer) partial;buf.sum += p.sum;buf.count += p.count;}}
注意:
UDTF
Java UDTF需要继承com.aliyun.odps.udf.UDTF类。这个类需要实现4个接口。
| 接口定义 | 描述 |
|---|---|
| public void setup(ExecutionContext ctx) throws UDFException | 初始化方法,在UDTF处理输入数据前,调用用户自定义的初始化行为。在每个Worker内setup会被先调用一次。 |
| public void process(Object[] args) throws UDFException | 这个方法由框架调用,SQL中每一条记录都会对应调用一次process,process的参数为SQL语句中指定的UDTF输入参数。输入参数以Object[]的形式传入,输出结果通过forward函数输出。用户需要在process函数内自行调用forward,以决定输出数据。 |
| public void close() throws UDFException | UDTF的结束方法,此方法由框架调用,并且只会被调用一次,即在处理完最后一条记录之后。 |
| public void forward(Object …o) throws UDFException | 用户调用forward方法输出数据,每次forward代表输出一条记录。对应SQL语句UDTF的as子句指定的列。 |
下面将给出一个UDTF程序示例:
package org.alidata.odps.udtf.examples;import com.aliyun.odps.udf.UDTF;import com.aliyun.odps.udf.UDTFCollector;import com.aliyun.odps.udf.annotation.Resolve;import com.aliyun.odps.udf.UDFException;// TODO define input and output types, e.g., "string,string->string,bigint".@Resolve({"string,bigint->string,bigint"})public class MyUDTF extends UDTF {@Overridepublic void process(Object[] args) throws UDFException {String a = (String) args[0];Long b = (Long) args[1];for (String t: a.split("\s+")) {forward(t, b);}}}
注:
- 以上只是程序示例,关于如何在ODPS中运行UDTF,方法与UDF类似,具体实现步骤请参考运行UDF。
在SQL中可以这样使用这个UDTF,假设在ODPS上创建UDTF时注册函数名为user_udtf:
select user_udtf(col0, col1) as (c0, c1) from my_table;
假设my_table的col0, col1的值为:
+------+------+| col0 | col1 |+------+------+| A B | 1 || C D | 2 |+------+------+
则select出的结果为:
+----+----+| c0 | c1 |+----+----+| A | 1 || B | 1 || C | 2 || D | 2 |+----+----+
使用说明
UDTF在SQL中的常用方式如下:
select user_udtf(col0, col1, col2) as (c0, c1) from my_table;select user_udtf(col0, col1, col2) as (c0, c1) from(select * from my_table distribute by key sort by key) t;select reduce_udtf(col0, col1, col2) as (c0, c1) from(select col0, col1, col2 from(select map_udtf(a0, a1, a2, a3) as (col0, col1, col2) from my_table) t1distribute by col0 sort by col0, col1) t2;
但使用UDTF有如下使用限制:
- 同一个SELECT子句中不允许有其他表达式
select value, user_udtf(key) as mycol ...
- UDTF不能嵌套使用
select user_udtf1(user_udtf2(key)) as mycol...
- 不支持在同一个select子句中与 group by / distribute by / sort by 联用
select user_udtf(key) as mycol ... group by mycol
其他UDTF示例
在UDTF中,用户可以读取ODPS的 资源 。下面将介绍利用udtf读取ODPS资源的示例。
编写udtf程序,编译成功后导出jar包(udtfexample1.jar)。
package com.aliyun.odps.examples.udf;import java.io.BufferedReader;import java.io.IOException;import java.io.InputStream;import java.io.InputStreamReader;import java.util.Iterator;import com.aliyun.odps.udf.ExecutionContext;import com.aliyun.odps.udf.UDFException;import com.aliyun.odps.udf.UDTF;import com.aliyun.odps.udf.annotation.Resolve;/*** project: example_project* table: wc_in2* partitions: p2=1,p1=2* columns: colc,colb*/@Resolve({ "string,string->string,bigint,string" })public class UDTFResource extends UDTF {ExecutionContext ctx;long fileResourceLineCount;long tableResource1RecordCount;long tableResource2RecordCount;@Overridepublic void setup(ExecutionContext ctx) throws UDFException {this.ctx = ctx;try {InputStream in = ctx.readResourceFileAsStream("file_resource.txt");BufferedReader br = new BufferedReader(new InputStreamReader(in));String line;fileResourceLineCount = 0;while ((line = br.readLine()) != null) {fileResourceLineCount++;}br.close();Iterator<Object[]> iterator = ctx.readResourceTable("table_resource1").iterator();tableResource1RecordCount = 0;while (iterator.hasNext()) {tableResource1RecordCount++;iterator.next();}iterator = ctx.readResourceTable("table_resource2").iterator();tableResource2RecordCount = 0;while (iterator.hasNext()) {tableResource2RecordCount++;iterator.next();}} catch (IOException e) {throw new UDFException(e);}}@Overridepublic void process(Object[] args) throws UDFException {String a = (String) args[0];long b = args[1] == null ? 0 : ((String) args[1]).length();forward(a, b, "fileResourceLineCount=" + fileResourceLineCount + "|tableResource1RecordCount="+ tableResource1RecordCount + "|tableResource2RecordCount=" + tableResource2RecordCount);}}
添加资源到ODPS:
Add file file_resource.txt;Add jar udtfexample1.jar;Add table table_resource1 as table_resource1;Add table table_resource2 as table_resource2;
在ODPS中创建UDTF函数(my_udtf):
create function mp_udtf as com.aliyun.odps.examples.udf.UDTFResource using 'udtfexample1.jar, file_resource.txt, table_resource1, table_resource2';
在odps创建资源表table_resource1、table_resource2, 物理表tmp1。并插入相应的数据。
运行该udtf:
select mp_udtf("10","20") as (a, b, fileResourceLineCount) from table_resource1;返回:+-------+------------+-------+| a | b | fileResourceLineCount |+-------+------------+-------+| 10 | 2 | fileResourceLineCount=3|tableResource1RecordCount=0|tableResource2RecordCount=0 || 10 | 2 | fileResourceLineCount=3|tableResource1RecordCount=0|tableResource2RecordCount=0 |+-------+------------+-------+
最后更新:2016-11-23 17:16:04
上一篇: 内建函数-下__SQL_大数据计算服务-阿里云
内建函数-下__SQL_大数据计算服务-阿里云
下一篇: 转义字符__附录_SQL_大数据计算服务-阿里云
- 修改物理专线属性__高速通道相关接口_API 参考_云服务器 ECS-阿里云
- 作业盒子、腾跃校长在线、音乐笔记等获融资;新东方网与新东方拟出资参与设立霍东投资;阿里云发布互联网大学
- 产品使用限制__用户指南_高速通道-阿里云
- 开发者使用引导__开发人员指南_消息服务-阿里云
- 视频_阿里云帮助中心-阿里云,领先的云计算服务提供商
- 事务消息__最佳实践_消息服务-阿里云
- CDN服务如何开启GZIP压缩功能___产品使用问题_CDN-阿里云
- 使用入门__Java SDK_STS SDK使用手册_访问控制-阿里云
- 资源授权场景__场景示例_Open API_消息队列 MQ-阿里云
- 子账号访问__授权管理_阿里云物联网套件-阿里云
相关内容
- 常见错误说明__附录_大数据计算服务-阿里云
- 发送短信接口__API使用手册_短信服务-阿里云
- 接口文档__Android_安全组件教程_移动安全-阿里云
- 运营商错误码(联通)__常见问题_短信服务-阿里云
- 设置短信模板__使用手册_短信服务-阿里云
- OSS 权限问题及排查__常见错误及排除_最佳实践_对象存储 OSS-阿里云
- 消息通知__操作指南_批量计算-阿里云
- 设备端快速接入(MQTT)__快速开始_阿里云物联网套件-阿里云
- 查询API调用流量数据__API管理相关接口_API_API 网关-阿里云
- 使用STS访问__JavaScript-SDK_SDK 参考_对象存储 OSS-阿里云