![]() 761
761
![]()
![]() 阿裏雲
阿裏雲
示例項目使用說明__開發準備_開發人員指南_E-MapReduce-阿裏雲
示例項目
本項目是一個完整的可編譯可運行的項目,包括 MapReduce、Pig、Hive 和 Spark 示例代碼。請點擊下載,詳情如下:
MapReduce
- WordCount: 單詞統計。
Hive
- sample.hive:表的簡單查詢。
Pig
- sample.pig:Pig 處理 OSS 數據實例。
Spark
SparkPi: 計算 Pi。
SparkWordCount: 單詞統計。
LinearRegression: 線性回歸。
OSSSample: OSS 使用示例。
ONSSample: ONS 使用示例。
ODPSSample: ODPS 使用示例。
MNSSample:MNS 使用示例。
LoghubSample:Loghub 使用示例。
依賴資源
測試數據(data 目錄下):
The_Sorrows_of_Young_Werther.txt:可作為 WordCount(MapReduce/Spark)的輸入數據。
patterns.txt:WordCount(MapReduce)作業的過濾字符。
u.data:sample.hive 腳本的測試表數據。
abalone:線性回歸算法測試數據。
依賴jar包(lib目錄下)
- tutorial.jar:sample.pig作業需要的依賴jar包
準備工作
本項目提供了一些測試數據,您可以簡單地將其上傳到 OSS 中即可使用。其他示例,例如ODPS、MNS、ONS 和 LogService 等等,需要您自己準備數據如下:
【可選】 創建 LogService,參考日誌服務用戶指南。
【可選】 創建 ODPS 項目和表,參考ODPS快速開始。
【可選】 創建 ONS,參考消息隊列快速開始。
【可選】 創建 MNS,參考消息服務控製台使用幫助。
基本概念
OSSURI:oss://accessKeyId:accessKeySecret@bucket.endpoint/a/b/c.txt,用戶在作業中指定輸入輸出數據源時使用,可以類比 hdfs://。
阿裏雲 AccessKeyId/AccessKeySecret 是您訪問阿裏雲 API 的密鑰,您可以在這裏獲取。
集群運行
Spark
SparkWordCount:
spark-submit --class SparkWordCount examples-1.0-SNAPSHOT-shaded.jar <inputPath> <outputPath> <numPartition>參數說明如下:
inputPath: 輸入數據路徑。
outputPath: 輸出路徑。
numPartition: 輸入數據 RDD 分片數目。
SparkPi:
spark-submit --class SparkPi examples-1.0-SNAPSHOT-shaded.jarOSSSample:
spark-submit --class OSSSample examples-1.0-SNAPSHOT-shaded.jar <inputPath> <numPartition>參數說明如下:
inputPath: 輸入數據路徑。
numPartition:輸入數據RDD分片數目。
ONSSample:
spark-submit --class ONSSample examples-1.0-SNAPSHOT-shaded.jar <accessKeyId> <accessKeySecret> <consumerId> <topic> <subExpression> <parallelism>參數說明如下:
accessKeyId: 阿裏雲 AccessKeyId。
accessKeySecret:阿裏雲 AccessKeySecret。
consumerId: 請參考 Consumer ID 說明。
topic: 每個消息隊列都有一個 topic。
subExpression: 參考消息過濾。
parallelism:指定多少個接收器來消費隊列消息。
ODPSSample:
spark-submit --class ODPSSample examples-1.0-SNAPSHOT-shaded.jar <accessKeyId> <accessKeySecret> <envType> <project> <table> <numPartitions>參數說明如下:
MNSSample:
spark-submit --class MNSSample examples-1.0-SNAPSHOT-shaded.jar <queueName> <accessKeyId> <accessKeySecret> <endpoint>參數說明如下:
queueName:隊列名,請參考 MNS 名詞解釋。
accessKeyId: 阿裏雲 AccessKeyId。
accessKeySecret:阿裏雲 AccessKeySecret。
endpoint:隊列數據訪問地址。
LoghubSample:
spark-submit --class LoghubSample examples-1.0-SNAPSHOT-shaded.jar <sls project> <sls logstore> <loghub group name> <sls endpoint> <access key id> <access key secret> <batch interval seconds>參數說明如下:
sls project: LogService 項目名。
sls logstore:日誌庫名。
loghub group name:作業中消費日誌數據的組名,可以任意取。sls project 和 sls store 相同時,相同組名的作業會協同消費 sls store 中的數據;不同組名的作業會相互隔離地消費 sls store 中的數據。
sls endpoint: 請參考日誌服務入口。
accessKeyId: 阿裏雲 AccessKeyId。
accessKeySecret:阿裏雲 AccessKeySecret。
batch interval seconds: Spark Streaming 作業的批次間隔,單位為秒。
LinearRegression:
spark-submit --class LinearRegression examples-1.0-SNAPSHOT-shaded.jar <inputPath> <numPartitions>參數說明如下:
inputPath:輸入數據。
numPartition:輸入數據 RDD 分片數目。
Mapreduce
WordCount:
hadoop jar examples-1.0-SNAPSHOT-shaded.jar WordCount -Dwordcount.case.sensitive=true <inputPath> <outputPath> -skip <patternPath>參數說明如下:
inputPathl:輸入數據路徑。
outputPath:輸出路徑。
patternPath:過濾字符文件,可以使用 data/patterns.txt。
Hive
hive -f sample.hive -hiveconf inputPath=<inputPath>參數說明如下:
- inputPath:輸入數據路徑。
Pig
pig -x mapreduce -f sample.pig -param tutorial=<tutorialJarPath> -param input=<inputPath> -param result=<resultPath>參數說明如下:
tutorialJarPath:依賴 Jar 包,可使用 lib/tutorial.jar。
inputPath:輸入數據路徑。
resultPath:輸出路徑。
注意:
- 在 E-MapReduce 上使用時,請將測試數據和依賴 jar 包上傳到 OSS 中,路徑規則遵循 OSSURI 定義,見上。- 如果集群中使用,可以放在機器本地。
本地運行
這裏主要介紹如何在本地運行 Spark 程序訪問阿裏雲數據源,例如 OSS 等。如果希望本地調試運行,最好借助一些開發工具,例如 Intellij IDEA 或者 Eclipse,尤其是對於 Windows環境,否則需要在 Windows 機器上配置 Hadoop 和 Spark 運行環境。
Intellij IDEA
準備工作
安裝Intellij IDEA,Maven, Intellij IDEA Maven插件,Scala,Intellij IDEA Scala插件。
開發流程
雙擊進入 SparkWordCount.scala。
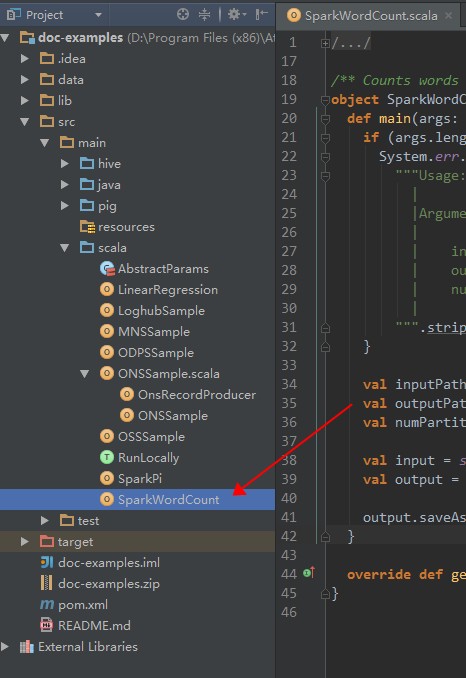
從下圖箭頭所指處進入作業配置界麵。
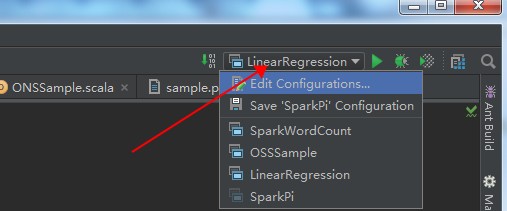
選擇 SparkWordCount,在作業參數框中按照所需傳入作業參數。

點擊 OK。
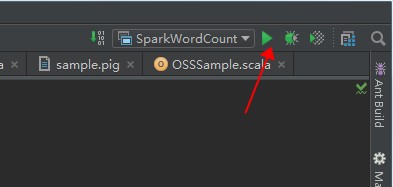
點擊運行按鈕,執行作業。
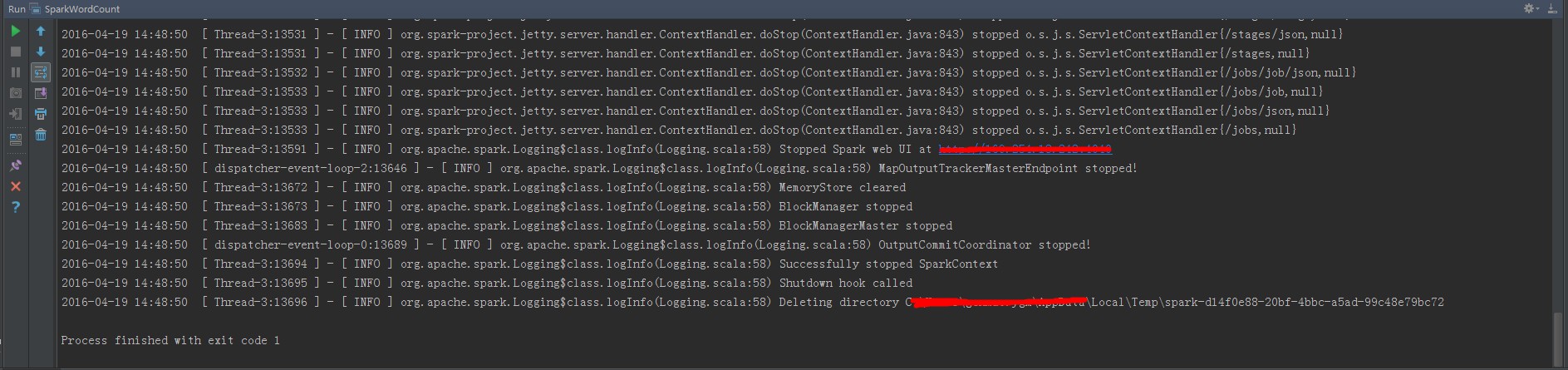
查看作業執行日誌




Scala IDE for Eclipse
準備工作
安裝 Scala IDE for Eclipse、Maven、Eclipse Maven 插件。
開發流程
請根據以下圖示導入項目。
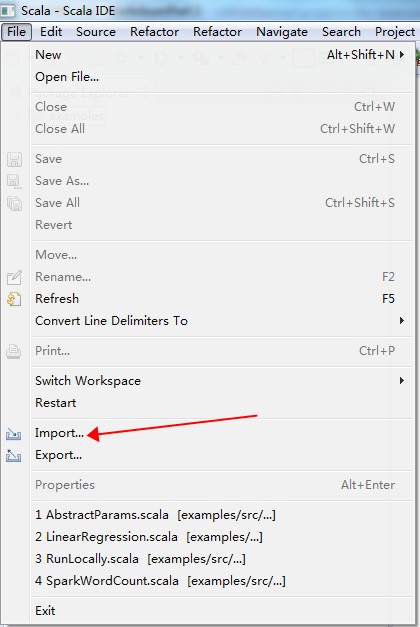
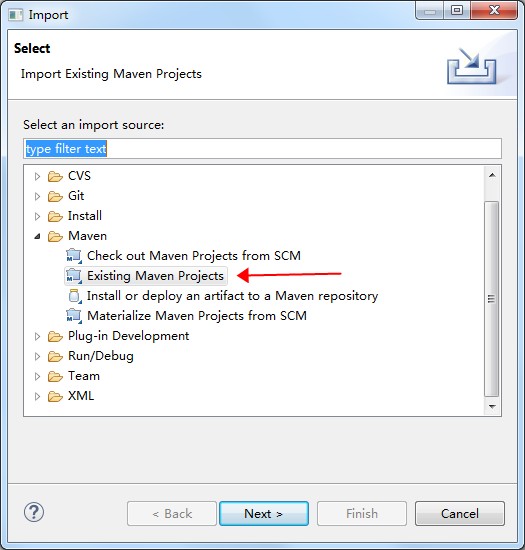
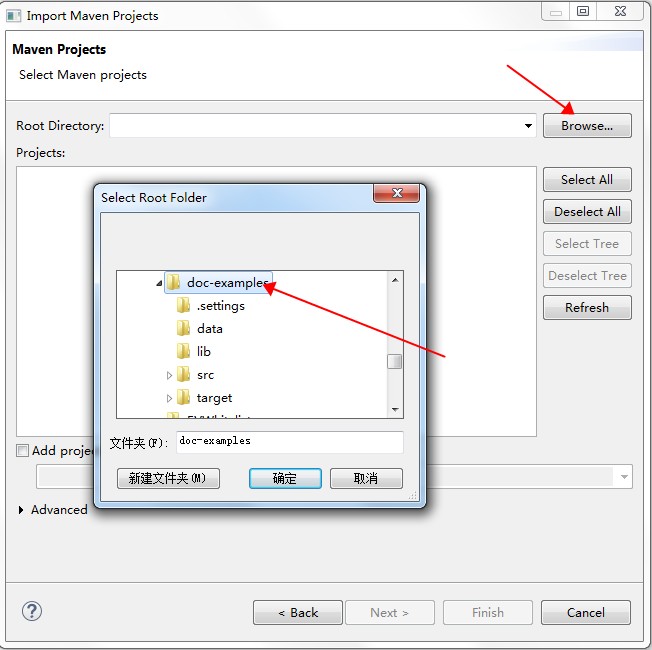
Run As Maven build,快捷鍵是“Alt + Shilft + X, M”;也可以在項目名上右鍵,“Run As”選擇“Maven build”。
等待編譯完後,在需要運行的作業上右鍵,選擇“Run Configuration”,進入配置頁。
在配置頁中,選擇 Scala Application,並配置作業的 Main Class 和參數等等。如下圖所示:
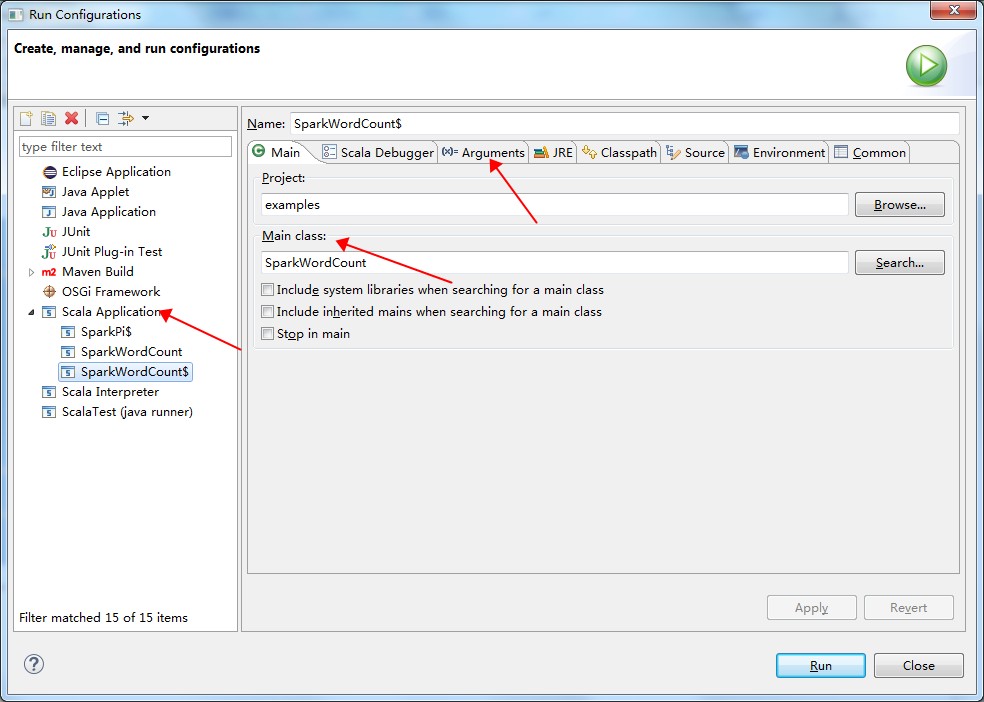
點擊“Run”。
查看控製台輸出日誌,如下圖所示:





最後更新:2016-11-23 16:03:59
上一篇: OSS 參考使用說明__開發準備_開發人員指南_E-MapReduce-阿裏雲
OSS 參考使用說明__開發準備_開發人員指南_E-MapReduce-阿裏雲
下一篇: 參數說明__Spark_開發人員指南_E-MapReduce-阿裏雲
- 在違規處罰中,一般違規、嚴重違規和特別嚴重違規是怎麼定義的?__規則FAQ_常見問題_阿裏雲規則-阿裏雲
- 建立授權關係__快速入門(調用API)_API 網關-阿裏雲
- DRDS自定義注釋__開發手冊_分布式關係型數據庫 DRDS-阿裏雲
- 分析接口配置__使用手冊_畫像分析-阿裏雲
- 錯誤碼表__錯誤說明_API 網關-阿裏雲
- 媒體傳播路徑分析__快速開始_公眾趨勢分析-阿裏雲
- 項目空間__基本概念_基本介紹_大數據計算服務-阿裏雲
- 查詢指定訂閱信息__訂閱管理相關接口_Open API_消息隊列 MQ-阿裏雲
- 解綁彈性公網 IP__網絡相關接口_API 參考_雲服務器 ECS-阿裏雲
- DROP VIEW__數據定義語言_SQL語法參考_雲數據庫 OceanBase-阿裏雲
相關內容
- 常見錯誤說明__附錄_大數據計算服務-阿裏雲
- 發送短信接口__API使用手冊_短信服務-阿裏雲
- 接口文檔__Android_安全組件教程_移動安全-阿裏雲
- 運營商錯誤碼(聯通)__常見問題_短信服務-阿裏雲
- 設置短信模板__使用手冊_短信服務-阿裏雲
- OSS 權限問題及排查__常見錯誤及排除_最佳實踐_對象存儲 OSS-阿裏雲
- 消息通知__操作指南_批量計算-阿裏雲
- 設備端快速接入(MQTT)__快速開始_阿裏雲物聯網套件-阿裏雲
- 查詢API調用流量數據__API管理相關接口_API_API 網關-阿裏雲
- 使用STS訪問__JavaScript-SDK_SDK 參考_對象存儲 OSS-阿裏雲