![]() 884
884
![]()
![]() 阿裏雲
阿裏雲
創建數據同步任務__快速開始_大數據開發套件-阿裏雲
【說明】目前數據同步任務支持的數據源類型包括:MaxCompute、RDS(MySQL、SQL Server、PostgreSQL)、Oracle、FTP、ADS、OSS、OCS、DRDS。

以RDS數據同步至MaxCompute為例,詳細說明如下:
step1:創建數據表
創建MaxCompute表的詳細操作詳見 :創建表。
step2:新建數據源
【說明】新建數據源需項目管理員角色才能夠創建。
準備工作
目前RDS數據源僅支持華東1(杭州)域的RDS,北京地域暫時不支持。另外當杭州地域的RDS也遇到數據源測試不連通的時候,需要到自己RDS上添加數據同步機器ip白名單:
10.152.69.0/24,10.153.136.0/24,10.143.32.0/24,120.27.160.26,10.46.67.156,120.27.160.81,10.46.64.81,121.43.110.160,10.117.39.238,121.43.112.137,10.117.28.203,118.178.84.74,10.27.63.41,118.178.56.228,10.27.63.60,118.178.59.233,10.27.63.38,118.178.142.154,10.27.63.15
具體操作如下:
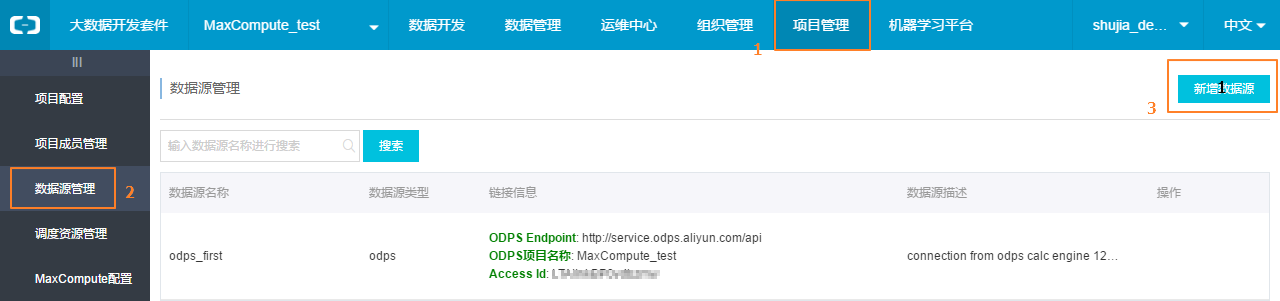
step2.1:以開發者身份進入阿裏雲數加平台>大數據開發套件>管理控製台,點擊對應項目操作欄中的進入工作區。
step2.2:點擊頂部菜單欄中的項目管理,點擊左側導航數據源管理。
step2.3:點擊新增數據源。
step2.4:在新增數據源彈出框中填寫相關配置項。
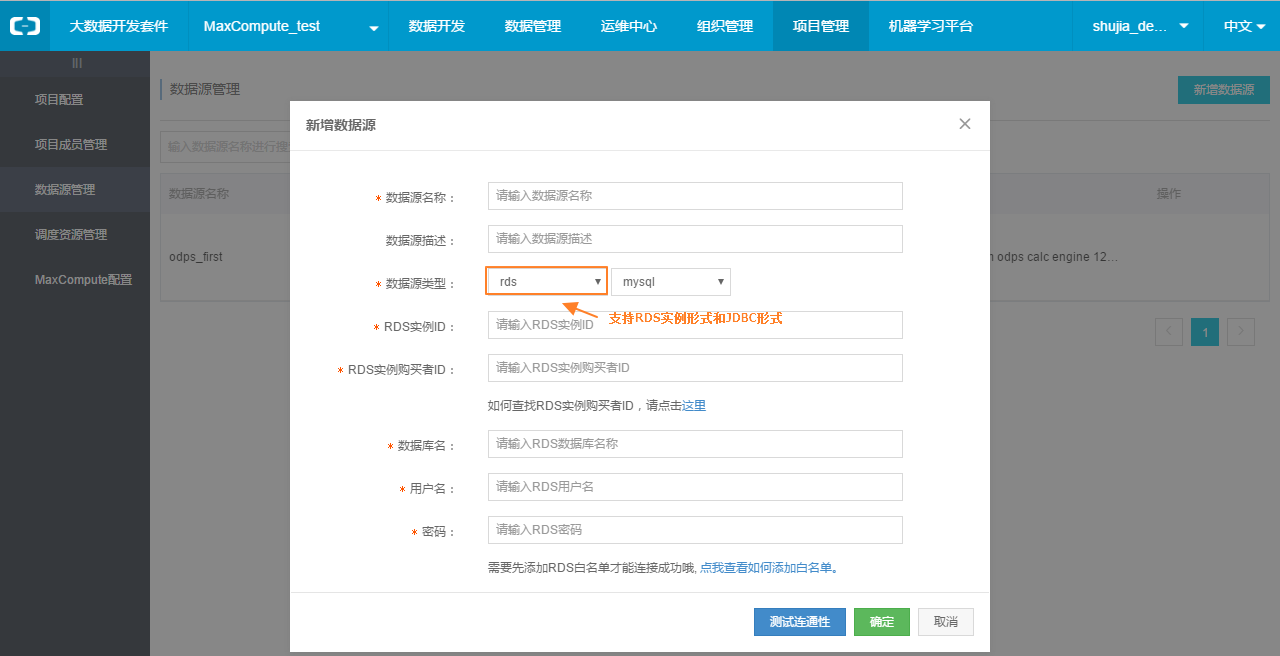
上圖中的配置項具體說明如下:
- 數據源名稱:由英文字母、數字、下劃線組成且需以字符或下劃線開頭,長度不超過30個字符。
- 數據源描述:對數據源的簡單描述,不超過1024個字符。
- 數據源類型:當前選擇的數據源類型(RDS>MySQL>RDS實例形式)。
- RDS實例ID:該MySQL數據源的RDS實例ID。
- RDS實例購買者ID:該MySQL數據源的RDS實例購買者ID。
【備注】若選擇JDBC形式來配置數據源,其JDBC連接信息,格式為:jdbc:mysql://IP:Port/database。
- 數據庫名:該數據源對應的數據庫名。
- 用戶名/密碼:數據庫對應的用戶名和密碼。
step2.5:點擊測試連通性。
step2.6:若測試連通性成功,則點擊保存按鈕完成配置信息保存。
關於其他類型(MaxCompute、RDS、Oracle、FTP、ADS、OSS、OCS、DRDS)數據源的配置,詳見:數據源配置。
step3:新建任務
關於新建任務的詳細說明與操作見:新建工作流。
step4:配置數據同步任務
您可向工作流設計器中拖入數據同步節點並雙擊進入數據同步節點配置界麵,包括“選擇數據來源和目標”、“選擇要抽取的列,並映射到目標表字段”、“數據抽取和加載控製”和“流量與出錯控製”四大配置項。
step4.1:選擇數據來源和目標
選擇數據源(數據源為已經建立好的數據源)後並且選擇數據表。
顯示建表DDL:點擊將源頭表的建表語句轉化為符合ODPS SQL語法規範的DDL語句。
添加數據源:點擊添加數據源跳轉到項目管理>數據源管理頁麵。
【備注】若源頭為Mysql數據源,則數據同步任務還支持分庫分表模式的數據導入(前提是無論數據存儲在同一數據庫還是不同數據庫,表結構必須是一致的)。
分庫分表可支持如下場景:
同庫多表:點擊搜索表,添加需要同步的多張表即可。
分庫多表:首先點擊添加選擇源庫,再點擊搜索表來添加表。如下圖所示:
step4.2:字段配置
需對字段映射關係進行配置,左側“源表字段”和右側“宿表字段”為一一對應的關係。
批量編輯,可批量編輯源表或宿表字段,通過此方式添加的表字段類型默認為空。
增加/刪除,點擊”添加一行”可單個增加字段。鼠標Hover上每一行,點擊刪除圖標可以刪除當前字段。
【提示】自定義變量和常量的寫入方法:如果需要把常量或者變量導入ODPS中表的某個字段,隻需要點擊插入按鈕,然後輸入常量或者變量的值,並且用英文單引號包起來即可,如變量‘${yesterday}’,然後再參數配置組件配置給變量賦值如yesterday=$[yyyymmdd]。具體時間參數詳見係統調度參數 說明 。
step4.3:數據抽取和加載控製
數據抽取控製即數據抽取的過濾條件,而數據加載控製即數據寫入時的規則。
抽取控製,可參考相應的SQL語法填寫where過濾語句(不需要填寫where關鍵字),該過濾條件將作為增量同步的條件。
【說明】where條件即針對源頭數據篩選條件,根據指定的column、table、where條件拚接SQL進行數據抽取。利用where條件可進行全量同步和增量同步,具體說明如下:
1)全量同步:第一次做數據導入時通常為全量導入,可不用設置where條件;如隻是在測試時,避免數據量過大,可將where條件指定為limit 10。
2)增量同步:增量導入在實際業務場景中,往往會選擇當天的數據進行同步,通常需要編寫where條件語句,請先確認表中描述增量字段(時間戳)為哪一個。如tableA描述增量的字段為creat_time,那麼在where條件中編寫creat_time>${yesterday},在參數配置中為其參數賦值即可。其中更多內置參數使用方法,請參照“係統調度參數 ”章節。
分區信息:分區是為了便於查詢部分數據引入的特殊列,指定分區便於快速定位到需要的數據。支持常量和變量。
- 清理規則:
1)寫入前清理已有數據:導數據之前,清空表或者分區的所有數據,相當於insert overwrite。
2)寫入前保留已有數據:導數據之前不清理任何數據,每次運行數據都是追加進去的,相當於insert into。
step4.3:流量與出錯控製
流量與出錯控製用來配置作業速率上限和髒數據檢查規則:
- 作業速率上限,即配置當前數據同步任務速率,支持最大為10MB/s(通道流量度量值是數據同步任務本身的度量值,不代表實際網卡流量)。
若數據同步任務是RDS/OracleODPS,在該頁麵中會有切分鍵配置。
- 切分鍵:隻支持類型為整型的字段。讀取數據時,根據配置的字段進行數據分片,實現並發讀取,可提升數據同步效率。隻有同步任務是RDS/Oracle數據導入至ODPS時,才顯示切分鍵配置項。
以下為髒數據檢查規則(寫入RDS、Oracle時可用 ),可配置一個或兩個,兩個規則之間為或的關係:
- 當出錯紀錄數超過,當髒數據數量(即錯誤記錄數)超過所配置的個數時,該數據同步任務結束。
- 錯誤百分比達到,當髒數據數量(即錯誤記錄數)超過所配置的百分比時,該數據同步任務結束。
最後更新:2016-12-19 19:37:51
上一篇: 創建任務(以MaxCompute SQL任務為例)__快速開始_大數據開發套件-阿裏雲
創建任務(以MaxCompute SQL任務為例)__快速開始_大數據開發套件-阿裏雲
下一篇: 創建自定義函數__快速開始_大數據開發套件-阿裏雲
- 人臉技術服務簡介__人臉技術服務_人工智能圖像類-阿裏雲
- 在線安裝命令行工具和 SDK__安裝命令行工具(Windows)_用戶指南_命令行工具 CLI-阿裏雲
- 瀏覽作業__作業管理_Console參考手冊_數據集成-阿裏雲
- 步驟 3:登錄Linux實例__快速入門(Linux)_雲服務器 ECS-阿裏雲
- 簡單下載示例__SDK示例_批量數據通道_大數據計算服務-阿裏雲
- 修改產品信息__接口列表_服務器端API_阿裏雲物聯網套件-阿裏雲
- 天粒度資源使用概覽__資源監控接口_API 手冊_CDN-阿裏雲
- HTTPS 雙向認證常見問題__常見問題_負載均衡-阿裏雲
- 常用管理函數__快速入門(PPAS)_雲數據庫 RDS 版-阿裏雲
- KMS地域分布__API 參考_密鑰管理服務-阿裏雲
相關內容
- 常見錯誤說明__附錄_大數據計算服務-阿裏雲
- 發送短信接口__API使用手冊_短信服務-阿裏雲
- 接口文檔__Android_安全組件教程_移動安全-阿裏雲
- 運營商錯誤碼(聯通)__常見問題_短信服務-阿裏雲
- 設置短信模板__使用手冊_短信服務-阿裏雲
- OSS 權限問題及排查__常見錯誤及排除_最佳實踐_對象存儲 OSS-阿裏雲
- 消息通知__操作指南_批量計算-阿裏雲
- 設備端快速接入(MQTT)__快速開始_阿裏雲物聯網套件-阿裏雲
- 查詢API調用流量數據__API管理相關接口_API_API 網關-阿裏雲
- 使用STS訪問__JavaScript-SDK_SDK 參考_對象存儲 OSS-阿裏雲