日志服务监控指标__常见问题_日志服务-阿里云
监控数据入口请参考LogHub监控章节。
- 写入/读取流量
- 含义:每个日志库(logstore)写入、以及读取实时情况
- 单位:Bytes/min
- 含义:统计该logStore通过ilogtail和SDK、API等读写实时流量,大小为传输大小(压缩情况下为压缩后),每分钟统计一个点,单位为字节/分钟。
- 原始数据大小
- 含义:每个Logstore写入数据原始大小(压缩前)
- 单位:Byte/min
- 总体QPS
- 含义:所有操作QPS,每分钟统计一个点
- 单位:Count/Min
- 操作次数
- 含义:统计用户的各种操作对应的QPS,每分钟统计一个点
- 单位:次/分钟(Count/Min)
- 所有的操作包括:
- 写入操作:
- PostLogStoreLogs :0.5API以后版本接口。
- PutData : 0.4 API以前版本接口。
- 根据关键字查询:
- GetLogStoreHistogram: 查询关键字分布情况,0.5API以后版本接口。
- GetLogStoreLogs: 查询关键字命中日志,0.5API以后版本接口。
- GetDataMeta : 同GetLogStoreHistogram,为0.4API以前版本接口。
- GetData : 同GetLogStoreLogs,为0.4API以前版本接口。
- 批量获取数据:
- GetCursorOrData:该操作包含了获取Cursor和批量获取数据两种方法。
- ListShards:获取一个LogStore下所有的Shard。
- List操作:
- ListLogStoreLogs:遍历一个project下所有的LogStore。
- ListCategory:同ListLogStoreLogs,为0.4API以前版本接口。
- ListLogStoreTopics:遍历一个Logstore下所有的Topic。
- 写入操作:
- 服务状态
- 含义:该视图统计用户的各种操作返回的HTTP 状态码对应的QPS,方便用户根据错误的返回码来判断操作异常,及时调整程序。
- 各状态码:
- 200:为正常的返回码,表示操作成功。
- 400:错误的参数,包括Host,Content-length,APIVersion,RequestTimeExpired,查询时间范围,Reverse,AcceptEncoding,AcceptContentType,Shard ,Cursor,PostBody,Paramter,ContentType等方面的错误。
- 401:鉴权失败,包括AccessKeyId不存在、签名不匹配、或者签名账户没有操作权限,请到SLSweb上查看project权限列表,是否包含了该AK。
- 403: 超过预定Quota,包括能够创建的LogStore个数、Shard总数、以及读写操作的每分钟限额,请根据返回的Message判断发生了哪种错误。
- 404:请求的资源不存在,包括project、 LogStore、Topic 、User等资源。
- 405:错误的操作方法,请检查请求的URL路径。
- 500:服务端错误,请重试。
- 502:服务端错误,请重试。
- 客户端解析成功流量
- 含义:Logtail收集成功的日志大小,为原始数据大小
- 单位:字节
- 客户端(Logtail)解析成功行数
- 含义:Logtail收集成功的日志的行数
- 单位: 行
- 客户端解析失败行数
- 含义:Logtail收集日志过程中,采集出错的行数大小,如果该视图有数据,表示有错误发生
- 单位:行
- 客户端错误次数
- 含义:Logtail收集日志过程中,出现所有收集错误的IP总数
- 单位:次
- 发生客户端错误机器数
- 含义:Logtail收集日志过程中,出现收集错误的告警次数
- 单位:个
- 错误IP统计(Count/5min)
- 含义:分类别展示各种采集错误发生的IP数,各种错误包括:
- LOGFILE_PERMINSSION_ALARM:没有权限打开日志文件。
- SENDER_BUFFER_FULL_ALARM:数据采集速度超过了网络发送速度,数据被丢弃。
- INOTIFY_DIR_NUM_LIMIT_ALARM(INOTIFY_DIR_QUOTA_ALARM):监控的目录个数超过了3000个,请把监控的根目录设置成更低层目录。
- DISCARD_DATA_ALARM:数据丢失,因为数据时间在系统时间之前15分钟,请保证新写入日志文件的数据是在15分钟之内的。
- MULTI_CONFIG_MATCH_ALARM:有多个配置在收集同一个文件,logtail会随机选择一个日志文件进行收集,另一个配置则收集不到数据。
- REGISTER_INOTIFY_FAIL_ALARM:注册inotify事件失败,具体原因请查看logtail日志。
- LOGDIR_PERMINSSION_ALARM:没有权限打开监控目录。
- REGEX_MATCH_ALARM:正则式匹配错误,请调整正则式。
- ENCODING_CONVERT_ALARM:转换日志编码格式时出现错误,具体原因请查看logtail日志。
- PARSE_LOG_FAIL_ALARM:解析日志错误,一般是行首正则表达式错误或单条日志超过512KB导致的日志分行错误,请查看Logtail日志确定原因,如行首正则表达式错误请调整配置。
- DISCARD_DATA_ALARM:丢弃数据,Logtail发送数据到日志服务失败且写本地缓存文件失败导致,可能的原因是日志文件产生较快但写磁盘缓存文件较慢。
- SEND_DATA_FAIL_ALARM:解析完成的日志数据发送日志服务失败,请查看Logtail日志发送数据失败相关ErrorCode和ErrorMessage,常见的错误有服务端Quota超限、客户端网络异常等。
- PARSE_TIME_FAIL_ALARM:解析日志time字段出错,Logtail根据正则表达式解析出来的time字段按照时间格式配置无法解析成功,请修改配置。
- OUTDATED_LOG_ALARM:Logtail丢弃历史数据,请保证当前写入日志数据的时间与系统时间相差在5分钟以内。
- 请根据具体错误请找到出错IP,登录机器查看/usr/logtail/ilogtail.LOG查看错误原因
- 含义:分类别展示各种采集错误发生的IP数,各种错误包括:
使用监控+报警
Logtail日志是否完整收集?
客户端(Logtail)在运行过程中,可能会因设置不正确产生错误:例如某些日志格式不匹配,一个日志文件被重复收集等(Logtail场景问题)。为了及时发现这种情况,我们可以对客户端解析失败行数、客户端错误次数等指标进行监控,以及时发现这类问题。步骤如下:
- 打开LogHub云监控页面,参考LogHub监控章节。
- 选择关心的Logstore,新建报警规则:
- 选择”客户端解析错误”
- 设置规则,当出错误后报警
- 设置报警短信接收人进行报警
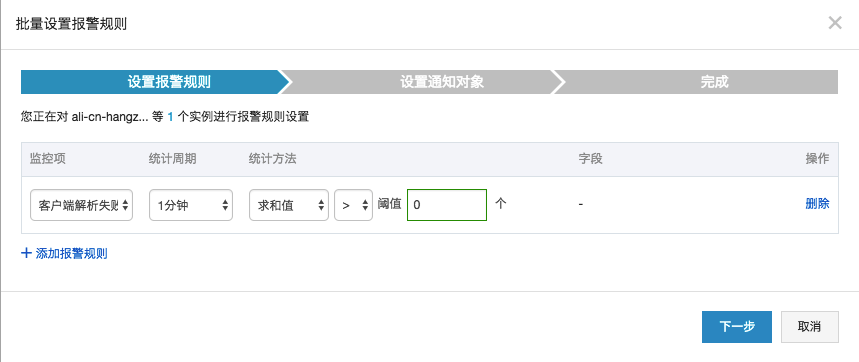
- 除此之外,还可以根据Logtail其他错误项进行报警,第一时间发现各类日志收集过程中发现的问题
Logstore下Shard资源是否足够
Logstore下每个Shard提供5MB/S (1000次/S) 写入能力,这个数值对于大部分用户而言都是足够的,在超过时日志服务会尽可能去服务(非拒绝)你的请求,但在高峰期间不保证超出部分可用性。如果你的日志量非常大,需要添加更多Shard,可以在控制台(日志消费/修改)中进行调整。在之前可以设置logstore出入流量报警以检测该情况。可以设置Logstore流量报警以检测该情况,步骤如下:
- 方案1:对流量预警
- 打开LogHub云监控页面,参考LogHub监控章节。
- 选择关心的Logstore,新建报警规则:
- 选择”原始数据大小”
- 设置规则,超过25GB/Min后进行报警
- 设置报警短信接收人进行报警
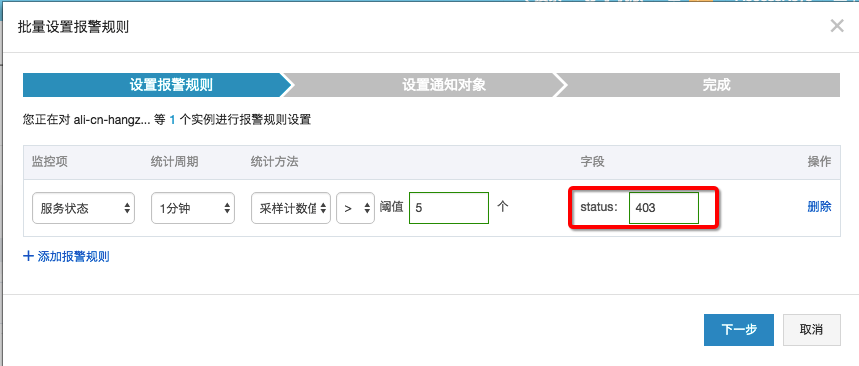
- 方案2:设置状态码报警
- 打开LogHub云监控页面,参考LogHub监控章节。
- 选择关心的Logstore,新建报警规则:
- 选择”服务状态”,status填写403(流量超过阈值)
- 设置规则,超过25GB/Min后进行报警
- 设置报警短信接收人进行报警
- Project Quota是否足够 每个Project默认写入限制为30GB/分钟(原始数据大小),这个数值主要目的是为了保护用户因程序错误产生大量日志设计,在一般场景中对于大部分用户都是足够的。如果你的日志量非常大,可能会超过限制,可以通过工单联系我们调整大这个数值。Logstore流量报警与预警步骤如上。
最后更新:2016-11-24 11:23:47
上一篇: 日志消费与查询区别__常见问题_日志服务-阿里云
日志消费与查询区别__常见问题_日志服务-阿里云
下一篇: kafka用户迁移__常见问题_日志服务-阿里云
- DRDS读写分离__开发手册_分布式关系型数据库 DRDS-阿里云
- RDS实例间的数据迁移__数据迁移_用户指南_数据传输-阿里云
- ActionTrail现在支持哪些产品?__常见问题_常见问题_操作审计-阿里云
- 新建路由器接口__高速通道相关接口_API 参考_云服务器 ECS-阿里云
- 请求签名__API-Reference_日志服务-阿里云
- 管理本地集群__集群管理_用户指南_容器服务-阿里云
- FileZilla使用手册__网站上传/下载_使用指南_云虚机主机-阿里云
- 升级和续费__购买指南_对象存储 OSS-阿里云
- 结合云解析实现跨地域负载均衡__最佳实践_负载均衡-阿里云
- 对象存储(OSS、七牛等)数据迁移NAS工具__数据迁移工具_常用工具_文件存储-阿里云
相关内容
- 常见错误说明__附录_大数据计算服务-阿里云
- 发送短信接口__API使用手册_短信服务-阿里云
- 接口文档__Android_安全组件教程_移动安全-阿里云
- 运营商错误码(联通)__常见问题_短信服务-阿里云
- 设置短信模板__使用手册_短信服务-阿里云
- OSS 权限问题及排查__常见错误及排除_最佳实践_对象存储 OSS-阿里云
- 消息通知__操作指南_批量计算-阿里云
- 设备端快速接入(MQTT)__快速开始_阿里云物联网套件-阿里云
- 查询API调用流量数据__API管理相关接口_API_API 网关-阿里云
- 使用STS访问__JavaScript-SDK_SDK 参考_对象存储 OSS-阿里云