分布式實時處理係統在高性能計算場景下的應用
本文根據DBAplus社群第82期線上分享整理而成
講師介紹

盧譽聲
Autodesk資深係統研發工程師
-
《分布式實時處理係統:原理、架構與實現》作者,Hurricane實時處理係統主要貢獻者,多部C++領域譯作。
大家好,我們今天主要討論以下幾個問題:
-
機器學習與實時處理係統應用
-
分布式計算拓撲搭建
-
消息算法調優
-
Hurricane計算框架與未來展望
一、機器學習與實時處理係統應用
現在我們先來看看第一部分:機器學習與實時處理係統應用。我們首先簡單了解下機器學習,然後引入分布式實時處理係統的概念以及實時處理係統與機器學的關係。
機器學習在現實世界中的作用越來越重要。
機器學習的方法非常多,比如傳統的知識庫方法,類比方法,歸納方法,演繹方法等各種方法。
目前在大多數領域中應用最多的當屬歸納學習方法。
在通常的歸納型機器學習中,我們的目標是讓計算機學習到一個“模型”(這種模型是人類預先組織好的,有固定的數據結構和算法等等),然後我們就可以用這個“模型”來進行“預測”。 預測就是從現實中輸入一些數據,通過學習到的模型進行計算,得到的輸出。我們希望這個模型可以在很高的概率下輸出一個和真實結果差距不大的結果。
一旦我們得到了這個模型,我們可以使用該模型處理輸入數據,得到輸出數據(即預測結果),而歸納性機器學習的任務就是學習中間的這個模型。
如果我們將這個模型看成一個函數,那麼我們可以認為歸納性機器學習的目的就是學習得到一個函數F,如果該函數的參數為x,輸出為y。那麼我們希望學到的東西就是 y = F(x) 中的F。
我們先用一個最簡單的例子來講一下:
假設我們現在不知道一個物體自由落體速度的計算公式,需要學習如何預測一個物體的自由落體速度 ,機器學習的第一步就是收集數據 。
假設我們可以測量出物體下墜的任何時間點的速度,那麼我們需要收集的數據就是某個物體的下墜時間和那個時間點的速度 。
現在我們收集到一係列數據:
時間 物體速度
1 9.7
2 20.0
3 29.0
4 39.9
5 49.4
6 58.5
7 69.0
8 78.8
9 89.0
我們這裏給出兩個假設。第一個假設是,一個物體自由落體的速度隻和時間有關係 第二個假設是,我們可以使用一個簡單的“模型”:一元一次函數得到物體的速度。(即 F(x) = ax + b)
在這個問題中,a、b 這就是這個模型待學習的“參數”。
現在的問題就是——我們需要用什麼策略來學習這些參數?因為我們可以遍曆的數值空間是無窮大的,因此我們必須采用某種策略指導我們進行學習。
我們就用非常樸素的思想來將解決這個問題吧。
在正式學習前,我們先將收集的數據分成兩組:一組是“訓練數據”,一組是“測試數據”。
假設訓練數據是:
1 9.7
2 20.0
3 29.0
4 39.9
5 49.4
6 58.5
測試數據是:
7 69.0
8 78.8
9 89.0
我們需要根據訓練數據計算出我們的參數a和b。然後使用我們計算出來的a和b預測測試數據,比較F(x)和實際數據的差距 。
如果誤差小到一定程度,說明我們學習到的參數是正確的。
比如和實際數據的差距都小於5% 。
如果滿足條件說明參數正確,否則說明參數不夠精確,需要進一步學習,這個差距,我們稱之為誤差(Loss) 。
現在我們來看一下在這個模型(簡單的一元一次線性函數)下如何學習這兩個參數:
比如我們可以采用這種學習策略 1.首先a和b都假定為整數,假定a的範圍是[-10, 10]這個區間,b的範圍是[-100, 100]這個區間 2.遍曆所有的a和b的組合,使用a和b計算ax + b,x取每個訓練數據的輸入數據,評估計算結果精確性的方法是計算結果和訓練數據結果的差的絕對值除以訓練數據結果,也就是 Loss = |F(x) - Y| / Y 3.計算每個組合的Loss的平均值,取平均Loss最小的為我們假定的“學習結果” 。
現在我們就得到了a和b,並且這個a和b是在我們給定範圍裏精度最高的參數,我們用這個a和b去訓練數據裏麵計算平均的 |F(x) - Y| / Y 。如果平均Loss小於 5%,說明這個a和b是符合我們精度的, 否則我們需要優化我們的學習策略。
這種樸素的基於歸納學習的機器學習方法可以分為以下幾步:
-
預先定義一個模型
-
根據模型製定學習策略
-
使用學習策略使用模型來學習(擬合)訓練數據,得到該模型中的所有參數
-
使用測試數據評估模型是否精確。如果不夠精確則根據學習策略繼續學習。如果足夠精確,我們就認為機器學習結束了。
-
最後我們可以得到模型和參數,這就是我們學到的結果,也就是那個用來預測的函數。
這裏我們也要注意,上述步驟的前提是我們的模型是可以收斂的,如果模型本身就是發散的,那麼我們就永遠得不到我們的結果了。
機器學習與實時處理係統
傳統的機器學習是一種批處理式的方法,在這種方法下,我們需要預先準備好所有的訓練數據,對訓練數據進行精心組織和篩選,很多情況下還需要對數據進行標記(監督式學習),而訓練數據的組織會對最後的訓練結果產生相當大的影響。
在這種算法中我們要處理完所有數據後才能更新權重和模型。
但現在出現了許多在線學習算法,這種算法可以對實時輸入的數據進行計算,馬上完成權重和模型更新。
一方麵我們可以用於監督式學習(完成數據標記後馬上加入訓練),也可以用於大量數據的非監督式學習。
而在這種情況下,實時處理係統就可以大展身手了。在線係統和實時處理係統可以確保實時完成對數據的學習,利用實時新係統。
實現思路如下圖所示:

這裏我們可以看到,係統接收來自其他係統的實時輸入,然後實時處理係統中使用在線算法快速處理數據,實時地更新模型權重信息。
純粹的在線算法可能並不適合許多情景,但是如果將部分在線算法和傳統的批處理式算法結合,將會起到非常好的效果。而且許多數據分析工作確實可以通過這種方式完成一部分處理,至少是預處理。
目前機器學習的趨勢就是對精度和速度的要求越來越高,方法越來越複雜,而數據越來越多,計算量越來越大,如果沒有足夠的計算結果,不一定能夠在有限時間內完成足夠的學習,因此現在類似於Tensorflow之類的機器學習解決方案都會提供針對分布式的支持。而大數據場景下的機器學習也變得越來越重要,這也對我們的分布式計算與存儲方案提出了嚴峻的挑戰。
二、分布式計算拓撲搭建
現在我們來看一個現實工程中常常會遇到的問題。
我們在開發實際係統時常常會收集大量的用戶體驗信息,而我們常常需要對這些體驗信息進行篩選、處理和分析。那麼我們應該如何搭建一個用於實時處理體驗信息的分布式係統呢?
我們先來看一下整體流程:

-
收集體驗信息
業務係統調用體驗信息接口,將體驗信息信息異步寫入到特定的文件當中。使用永不停息的體驗信息檢測程序不斷將新生成的體驗信息發送到數據處理服務器。 -
處理體驗信息
首先數據處理服務器的體驗信息接收負責將體驗信息寫入本地的Redis數據庫中。然後我們使用消息源從Redis中讀取數據,再將數據發送到之後的消息處理單元,由不同的數據處理單元對體驗信息進行不同處理。
-
存儲結果
消息處理單元完成體驗信息處理之後,將體驗信息處理結果寫入到Cassandra數據庫中,並將體驗信息數據寫入到Elasticsearch數據庫中。
其中關鍵的部分就是圖中用長方形框出來的部分,該部分的作用是完成對數據的篩選、處理和基本分析。這部分我們將其稱作計算拓撲,也就是用於完成實際計算的部分。
我們接下來闡述一下每一步具體如何做。
收集體驗信息

收集體驗信息分為以下幾步:
-
程序通過體驗信息接口將體驗信息寫入體驗信息文件中。我們假設程序會使用非阻塞的異步寫入接口,體驗信息接口的調用方隻是將體驗信息送入某個隊列中,然後繼續向下執行。
-
接著體驗信息寫入線程從消息隊列中讀取數據,並將體驗信息數據寫入到真正的體驗信息文件中。
-
寫入後,某一個體驗信息代理程序會不斷監視體驗信息文件的改動,並將用戶新寫入的體驗信息信息發送到體驗信息處理服務器的體驗信息收集服務接口上。
-
體驗信息收集服務接口是整個服務的對外接口,負責將其他節點發送的體驗信息信息送入集群內部的Redis節點,並將體驗信息數據寫入到Redis的列表中。至此為止,體驗信息收集過程就完成了。
處理體驗信息

接下來是處理體驗信息,處理體驗信息主要在計算拓撲中完成。分為四步:
-
體驗信息處理消息源:負責監視Redis列表的改變,從Redis列表中讀取體驗信息規則,並將體驗信息規則文本轉換成計算拓撲的內部數據格式,傳送到下一個體驗信息處理單元。
-
體驗信息規則引擎:使用體驗信息規則引擎對體驗信息進行處理和過濾。這一步是可選的,也就是用戶可以加入自己的消息處理單元對收集的體驗信息進行處理。這將會影響到發送到後續的消息處理單元(索引器和計數器)中的體驗信息消息。這一步我們就不做處理了,如果讀者感興趣可以自己加入一個或者多個消息處理單元對體驗信息進行處理。
-
索引:這一步必不可少,用於將體驗信息規則引擎輸出的體驗信息寫入到ElasticSearch中,並便於用戶日後檢索這些體驗信息。這裏涉及到一步——將體驗信息規則元組轉換成JSON,並將JSON寫入ElasticSearch。
-
統計:這一步也非常重要,用於對體驗信息進行計數,這一步會將體驗信息計數結果寫入Cassandra的對應表中。便於用戶獲取統計信息。
存儲結果

最後就是對計算結果的存儲,我們需要使用存儲模塊將數據寫入到不同的數據庫中:
-
ElasticSearch:該數據庫用於存儲被轉換成JSON的原始體驗信息信息。用戶可以在ElasticSerach中檢索體驗信息。
-
Cassandra:該數據庫用於存儲體驗信息的統計計算結果。因為Cassandra支持原子計數列,因此可以非常勝任這個工作。
我們可以發現,在上麵幾步中,其他都可以使用現成的係統來完成任務,最關鍵的部分就是計算拓撲,計算拓撲需要高實時性地完成體驗信息處理分析任務,這樣才能應付大型係統中以極快速度產生的大量體驗信息。
這裏我們可以使用一個獨立的計算集群來完成這個事情。每個計算節點負責完成一個計算任務,完成之後將數據傳送給下一個計算節點完成後續的計算任務。每個計算節點都有一個消息隊列用於接收來自上一級的消息,然後處理消息並繼續將結果發送給下一級的計算節點。
這裏我們通常關心三個問題:
-
如何確保所有數據都得到了處理。
-
如何組織消息(數據)的傳遞,為整個集群高效計算提供一個良好的I/O支持。
-
如何搭建這個計算拓撲並盡量高效地進行完成計算。
三、消息算法調優
1、如何確保所有數據都得到了處理
我們先來看一下如何解決解決數據的完全處理問題。
我們這裏講每一個需要處理的數據(一條體驗信息記錄)組織成一個Tuple,也就是元組。每個計算節點都以Tuple為單位進行數據處理。每個元組都會有一個ack方法,用於告知上一級計算節點該Tuple已經處理完成。
我們以下麵的方式處理Tuple,保證所有數據都會被完全處理:
-
首先給每個Tuple一個id(偽隨機的64位id)。
-
由消息源發出的Tuple會有一個Acker,構造Tuple的時候會把新的Tuple加入這個Acker(就是包含這個Acker)。
-
每個節點處理完一個元組調用元組的ack方法,改變Acker內部的記錄值,表示當前Tuple已經完成處理。
-
如果某個Acker中的所有Tuple都已經處理完成,那麼這個Spout Tuple就已經處理完成。表明該消息源發出的Tuple被完全處理。
-
由於我們無法在Acker中記錄下Tuple樹,因此比較好的方式是實現一個基於異或的優化算法,該算法在Storm中得到了應用。其具體實現是:在Acker中設置一個ack id,每創建一個Tuple,將id與其異或,每ack一個Tuple時,將其與id做異或運算。這樣當所有Tuple處理完成後,ack id為0,就可以知道所有元組處理完成。
-
如果消息源檢測到某個其發出的Tuple沒有在特定時間內得到處理,就會重發該元組。後續的計算節點重新開始處理。為了實現一個同時符合CAP的分布式係統,我們這裏後續的計算節點並不會緩存計算結果,而是會重新開始計算上一級節點重發的元組,具體為什麼這樣做請參見How to beat the CAP theorem。
2、數據流量控製問題
我們可以設想一下,如果網絡狀況不好,在特定時間內有許多元組都沒有得到處理,那麼數據源節點就會重發許多Tuple,然後後續節點繼續進行處理,產生更多的Tuple,加上我們需要正常處理的Tuple,使得集群中的Tuple越來越多。而由於網絡狀況不好,節點計算速度優先,會導致集群中積累的過多數據拖慢整個集群的計算速度,進一步導致更多的Tuple可能計算失敗。
為了解決這個問題,我們必須想方設法控製集群中的流量。
這個時候我們就會采用一種流量背壓機製。該機製借鑒自Heron。
這個機製的思想其實很簡單,當每個計算節點處理 Tuple過慢,導致消息隊列中擠壓的Tuple過多時會向其他節點發送消息,那麼所有向該節點發送消息的節點都會降低其發送消息的速度。經過逐級傳播慢慢將整個集群的流量控製在比較合理的情況下。隻不過這個算法具體如何實現有待我們繼續研究。
3、如何搭建這個計算拓撲,盡量高效地進行完成計算
最後就是如何搭建這個拓撲,並盡量高效地完成計算了。
在分布式實時處理係統領域,目前最為成功的例子就是Apache Storm項目,而Apache Storm采用的就是一種流模型。而我們的Hurricane則借鑒了Storm的結構,並進行了簡化(主要在任務和線程模型上)。
這種流模型包括以下幾個概念:
-
拓撲結構:一個拓撲結構代表一個打包好的實時應用程序,相當於Hadoop中的一個MapReduce任務。但是和MapReduce最大的不同就是,MapReduce最後會停止,相當於任務處理結束,而拓撲結構則會持續執行,永不停息,除非你手動停止。因此任何時刻流入的數據流都會被拓撲結構迅速處理。
-
流:一個流是拓撲結構中由元組組成的無限的序列,通常是由一個元組經過不同的處理單元處理之後產生的。每一個流入拓撲結構中的數據都會產生一個流。
-
元組:元組是在流中傳輸的數據,數據源會將輸入的數據轉成元組輸入到拓撲結構中,而數據處理單元會處理上一級的元組並產生新的元組傳給下一級的數據處理單元。元組中支持存儲不同類型的數據。
-
消息源:消息源是拓撲結構中數據流的源頭。通常其任務是讀取外部數據源輸入,並產生元組輸入拓撲結構中。可靠的數據源可以確保消息完全得到處理,並在合適的時候重發元組。
-
數據處理單元:數據處理單元是拓撲結構中負責處理數據的部分,你可以在其中篩選數據,統計數據,拚接數據等等。
-
數據處理單元會接收來自上一級的元組,並經過處理得到下一級的元組。每個數據處理單元會向上一級確認其元組有沒有得到正確處理,如果數據源發現固定時間內並不是全部元組都被處理完了,就會重發元組。
為了支撐這套模型,我們設計了Hurricane的架構,該架構如下圖所示:
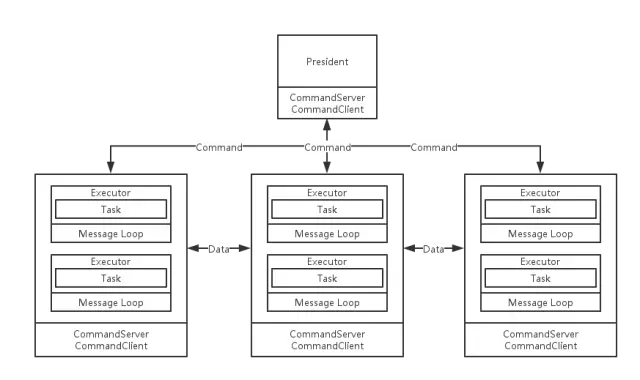
其中有以下幾個組件:
-
President:該組件是一個服務,是整個集群的核心,負責完成整個集群的調度和管理。當你需要啟動一個任務時,該節點會讀取整個進去的信息,並將任務合理分配給各個計算節點。
-
Mananger:每個計算節點都有一個Mananger服務。該服務負責接收來自President的消息,並將任務交給具體的Executor進行處理。當處理完成一個Tuple後會將Tuple發給下一個Manager進行處理(發送給那個Manager會在計算任務啟動時由President指定)。
-
Executor:每個Executor是一個線程,該線程會啟動一個消息循環,接收來自Manager的消息,每接收到一個消息,就會調用Executor內的Task完成處理。每個Executor會包含一個Task,也就是一個計算處理任務。
-
Task:計算處理任務,可能是產生Tuple的消息源,也可以能是對Tuple進行處理的消息處理單元,每個Executor都會包含一個Task。而Storm中,一個Executor中會包含多個Task,我們模仿JStorm改造了這個模型,主要可以簡化Task的管理和任務調度,而在JStorm中也證實這樣並不會降低集群的處理能力。
四、展望
目前我們已經基本實現了這個架構並且能保證處理簡單的計算任務。我們需要在之後的時間中繼續完善這個架構和機製,完善並優化我們的係統實現,比如完全實現高層抽象Squared和保序機製等,讓我們的係統能更接近切合實際的工程應用,而不是一個設想的空中樓閣。
除此以外,由於現在有許多計算任務需要使用基於向量和矩陣的浮點計算,因此我們計劃開發一個Hurricane的子項目——SewedBLAS。這是一個BLAS庫的高層抽象,我們希望整合大量的BLAS庫,比如使用CPU的MKL/OpenBLAS,使用GPU的CUDA和ACML,構建一個易於使用、跨平台的高性能線性代數庫,並與Hurricane進行深度整合,力求在分布式和科學計算、深度學習找到最好的切合點,並充分吸收整合其他現有的分布式機器學習框架,減少從科研到產品的轉換難度。
原文發布時間為:2016-11-28
本文來自雲棲社區合作夥伴DBAplus
最後更新:2017-05-11 13:31:01