《KAFKA官方文檔》入門指南(三)
從控製台寫入數據和寫回控製台是一個很方便入門的例子,但你可能想用Kafka使用其他來源的數據或導出Kafka的數據到其他係統。相對於許多係統需要編寫定製集成的代碼,您可以使用Kafka連接到係統去導入或導出數據。
Kafka Connect是包括在Kafka中一個工具,用來導入導出數據到Kafka。它是connectors的一個可擴展工具,其執行定製邏輯,用於與外部係統交互。在這個快速入門,我們將看到如何使用Kafka Connect做一些簡單的連接器從一個文件導入數據到Kafka的主題,和將主題數據導出到一個文件。
首先,我們需要創建一些原始數據來開始測試:
> echo -e "foo\nbar" > test.txt
接下來,我們將啟動兩個運行在獨立模式的連接器,這意味著他們在一個單一的,局部的,專用的進程中運行。我們提供三個配置文件作為參數。第一始終是Kafka連接過程中的公共配置,如要連接到的Kafka的代理服務器的配置和數據的序列化格式的配置。剩餘的每個配置文件用來創建指定的連接器。這些文件包括一個唯一的連接器名稱,需要實例化的連接器類,還有創建該連接器所需的其他配置。
> bin/connect-standalone.sh config/connect-standalone.properties config/connect-file-source.properties config/connect-file-sink.properties
用這些Kafka的示例配置文件,使用前麵已經啟動的本地群集的默認配置,建立兩個連接器:第一是一個源連接器,其從輸入文件中讀取每行的內容,發布到的Kafka主題和第二個是一個sink連接器負責從Kafka主題讀取消息,生產出的消息按行輸出到文件。
在啟動過程中,你會看到一些日誌信息,包括一些表明該連接器被實例化的信息。一旦Kafka Connect進程已經開始,源連接器應該開始從test.txt讀取每行的消息,並將其生產發布到主題connect-test,而sink連接器應該從主題connect-test讀取消息,並將其寫入文件test.sink.txt。我們可以通過檢查輸出文件的內容來驗證數據都已通過整個管道輸送:
> cat test.sink.txt foo bar
請注意,數據被存儲在Kafka主題的connect-test中,所以我們也可以運行控製台消費者消費主題中的數據(或使用定製的消費者代碼來處理它):
> bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic connect-test --from-beginning
{"schema":{"type":"string","optional":false},"payload":"foo"}
{"schema":{"type":"string","optional":false},"payload":"bar"}
...
連接器不停的處理數據,因此我們可以將數據添加到該文件,並能看到數據通過管道移動:
> echo "Another line" >> test.txt
您應該看到一行消息出現在控製台消費者的控製台和sink文件中。
Kafka Streams 是Kafka的客戶端庫, 用來做實時流處理和分析存儲在Kafka代理服務器的數據。該快速入門例子將演示如何運行這個流應用庫。這裏是要點WordCountDemo的示例代碼(轉換為方便閱讀的Java 8 lambda表達式)。
// Serializers/deserializers (serde) for String and Long types
final Serde<String> stringSerde = Serdes.String();
final Serde<Long> longSerde = Serdes.Long();
// Construct a `KStream` from the input topic ""streams-file-input", where message values
// represent lines of text (for the sake of this example, we ignore whatever may be stored
// in the message keys).
KStream<String, String> textLines = builder.stream(stringSerde, stringSerde, "streams-file-input");
KTable<String, Long> wordCounts = textLines
// Split each text line, by whitespace, into words.
.flatMapValues(value -> Arrays.asList(value.toLowerCase().split("\\W+")))
// Group the text words as message keys
.groupBy((key, value) -> value)
// Count the occurrences of each word (message key).
.count("Counts")
// Store the running counts as a changelog stream to the output topic.
wordCounts.to(stringSerde, longSerde, "streams-wordcount-output");
它實現了單詞計數算法,計算輸入文本中一個單詞的出現次數。然而,與其他單詞計數的算法不同,其他的算法一般都是對有界數據進行操作,該算法演示應用程序的表現略有不同,因為他可以被設計去操作無限的,無界的流數據。和操作有界數據的算法相似,它是一個有狀態的算法,可以跟蹤和更新單詞的計數。然而,因為它必須承擔潛在的無界輸入數據的處理,它會周期性地輸出其當前狀態和結果,同時繼續處理更多的數據,因為它無法知道他有沒有處理完“所有”的輸入數據。
作為第一步驟,我們將準備好輸入到Kafka主題的數據,隨後由Kafka Streams應用程序進行處理。
> echo -e "all streams lead to kafka\nhello kafka streams\njoin kafka summit" > file-input.txt
或在Windows上:
> echo all streams lead to kafka> file-input.txt > echo hello kafka streams>> file-input.txt > echo|set /p=join kafka summit>> file-input.txt
接下來,我們使用控製台生產者把輸入的數據發送到主題名streams-file-input 的主題上,其內容從STDIN一行一行的讀取,並一行一行的發布到主題,每一行的消息都有一個空鍵和編碼後的字符串(在實踐中,當應用程序將啟動並運行後,流數據很可能會持續流入Kafka):
> bin/kafka-topics.sh --create \
--zookeeper localhost:2181 \
--replication-factor 1 \
--partitions 1 \
--topic streams-file-input
> bin/kafka-console-producer.sh --broker-list localhost:9092 --topic streams-file-input < file-input.txt
現在,我們可以運行單詞計數應用程序來處理輸入數據:
> bin/kafka-run-class.sh org.apache.kafka.streams.examples.wordcount.WordCountDemo
演示應用程序將從輸入主題streams-file-input讀取數據,對讀取的消息的執行單詞計數算法,並且持續寫入其當前結果到輸出主題streams-wordcount-output。因此,除了寫回Kafka的日誌條目,不會有任何的STDOUT輸出。該演示將運行幾秒鍾,與典型的流處理應用不同,演示程序會自動終止。
現在,我們通過讀取輸出主題的輸出得到單詞計數演示程序的結果:
> bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 \
--topic streams-wordcount-output \
--from-beginning \
--formatter kafka.tools.DefaultMessageFormatter \
--property print.key=true \
--property print.value=true \
--property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer \
--property value.deserializer=org.apache.kafka.common.serialization.LongDeserializer
下麵的數據會被輸出到控製台:
all 1 lead 1 to 1 hello 1 streams 2 join 1 kafka 3 summit 1
這裏,第一列是java.lang.String類型的消息健,而第二列是java.lang.Long型消息值。注意,這裏的輸出其實是數據更新的連續流,每個數據記錄(上麵的例子裏的每行的輸出)都有一個單詞更新後的數目值,例如“Kafka”作為鍵的記錄。對於具有相同鍵的多個記錄,每個後麵的記錄都是前一個記錄的更新。
下麵的兩個圖說明什麼發生在幕後的過程。第一列顯示的當前狀態的變化,用KTable<String, Long>來統計單詞出現的數目。第二列顯示KTable狀態更新導致的發生變化的記錄,這個變化的記錄被發送到輸出Kafka主題streams-wordcount-output。
首先, “all streams lead to kafka”這樣一行文本正在被處理。當新的單詞被處理的時候,KTable會增加一個新的表項(以綠色背景高亮顯示),並有相應的變化記錄發送到下遊KStream。
當第二行“hello kafka streams”被處理的時候,我們觀察到,現有的KTable中的表項第一次被更新(這裏: 單詞 “kafka” 和 “streams”)。再次,改變的記錄被發送到輸出話題。
以此類推(我們跳過的第三行是如何被處理的插圖)。這就解釋了為什麼輸出主題有我們上麵例子顯示的內容,因為它包含了完整的更改記錄。
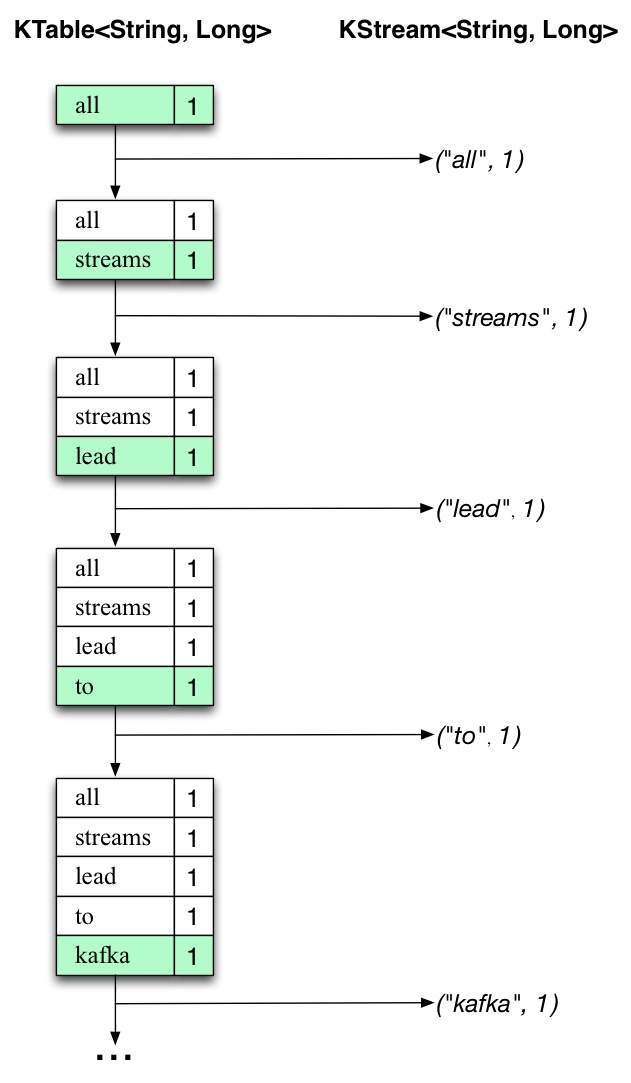
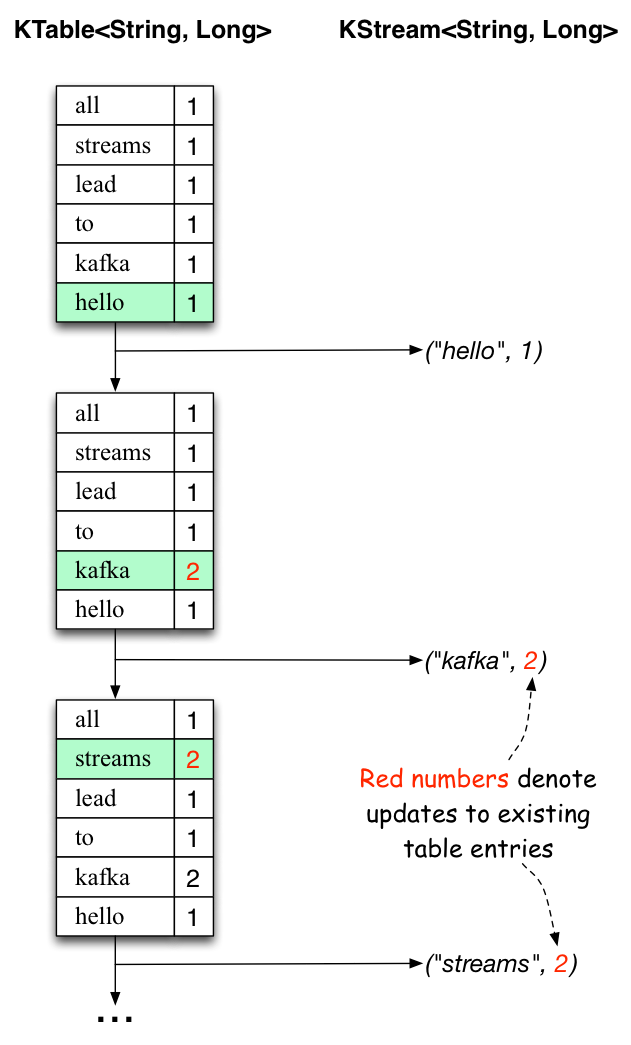
跳出這個具體的例子我們從整體去看, Kafka流利用表和日誌變化(changelog)流之間的二元性(here: 表= the KTable, 日誌變化流 = the downstream KStream):你可以發布的每一個表的變化去一個流,如果你從開始到結束消費了整個的日誌變化(changelog)流,你可以重建表的內容。
現在,你可以寫更多的輸入信息到streams-file-input主題,並觀察更多的信息加入到了 streams-wordcount-output主題,反映了更新後的單詞數目(例如,使用上述的控製台生產者和控製台消費者)。
您可以通過Ctrl-C 停止控製台消費者。
最後更新:2017-05-18 20:36:02