電商那些年,我摸爬打滾出的高並發架構實戰精髓(續)
一、分層,分割,分布式
大型網站要很好地支撐高並發,需要長期的規劃設計。在初期,需要把係統進行分層,在發展過程中把核心業務進行拆分成模塊單元,根據需求進行分布式部署,可以進行獨立團隊維護開發。
分層:
-
將係統在橫向維度上切分成幾個部分,每個部門負責一部分相對簡單並比較單一的職責,然後通過上層對下層的依賴和調度組成一個完整的係統。
-
比如把電商係統分成:應用層,服務層,數據層。(具體分多少個層次根據自己的業務場景)
-
應用層:網站首頁,用戶中心,商品中心,購物車,紅包業務,活動中心等,負責具體業務和視圖展示。
-
服務層:訂單服務、用戶管理服務、紅包服務、商品服務等,為應用層提供服務支持。
-
數據層:關係數據庫、NoSQL數據庫等,提供數據存儲查詢服務。
-
分層架構是邏輯上的,在物理部署上可以部署在同一台物理機器上,但是隨著網站業務的發展,必然需要對已經分層的模塊分離部署,分別部署在不同的服務器上,使網站可以支撐更多用戶訪問。
分割:
-
在縱向方麵對業務進行切分,將一塊相對複雜的業務分割成不同的模塊單元。
-
包裝成高內聚低耦合的模塊不僅有助於軟件的開發維護,也便於不同模塊的分布式部署,提高網站的並發處理能力和功能擴展。
-
比如用戶中心可以分割成:賬戶信息模塊、訂單模塊、充值模塊、提現模塊、優惠券模塊等。
分布式:
-
分布式應用和服務,將分層或者分割後的業務分布式部署,獨立的應用服務器、數據庫、緩存服務器。
-
當業務達到一定用戶量時,再進行服務器均衡負載、數據庫、緩存主從集群。
-
分布式靜態資源,比如:靜態資源上傳CDN。
-
分布式計算,比如:使用Hadoop進行大數據的分布式計算。
-
分布式數據和存儲,比如:各分布節點根據哈希算法或其他算法分散存儲數據。

(網站分層-來自網絡)
二、集群
對於用戶訪問集中的業務獨立部署服務器、應用服務器、數據庫、NoSQL數據庫,核心業務基本上需要搭建集群,即多台服務器部署相同的應用構成一個集群,通過負載均衡設備共同對外提供服務, 服務器集群能夠為相同的服務提供更多的並發支持,因此當有更多的用戶訪問時,隻需要向集群中加入新的機器即可,另外可以實現當其中的某台服務器發生故障時,可通過負載均衡的失效轉移機製將請求轉移至集群中其他的服務器上,因而提高係統的可用性。
應用服務器集群:
-
Nginx 反向代理
-
SLB
-
… …
(關係/NoSQL)數據庫集群:
-
主從分離,從庫集群

(通過反向代理均衡負載-來自網絡)
三、異步
在高並發業務中如果涉及到數據庫操作,主要壓力都是在數據庫服務器上麵,雖然使用主從分離,但是數據庫操作都是在主庫上操作,單台數據庫服務器連接池允許的最大連接數量是有限的 。
當連接數量達到最大值時,其它需要連接數據操作的請求就需要等待有空閑的連接,這樣高並發的時候很多請求就會出現connection time out的情況 。
那麼,像這種高並發業務我們要如何設計開發方案可以降低數據庫服務器的壓力呢?
如:
-
自動彈窗簽到,雙11跨0點的時候並發請求簽到接口;
-
雙11搶紅包活動;
-
雙11訂單入庫;
-
……
設計考慮:
-
逆向思維,壓力在數據庫,那業務接口就不進行數據庫操作不就沒壓力了?
-
數據持久化是否允許延遲?
-
如何讓業務接口不直接操作DB,又可以讓數據持久化?
方案設計:
-
像這種涉及數據庫操作的高並發的業務,就要考慮使用異步了。
-
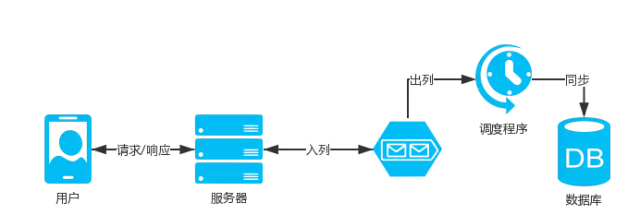
客戶端發起接口請求,服務端快速響應,客戶端展示結果給用戶,數據庫操作通過異步同步。
-
如何實現異步同步?
-
使用消息隊列,將入庫的內容enqueue到消息隊列中,業務接口快速響應給用戶結果(可以溫馨提示高峰期延遲到賬)。
-
然後再寫個獨立程序從消息隊列dequeue數據出來進行入庫操作,入庫成功後刷新用戶相關緩存,如果入庫失敗記錄日誌,方便反饋查詢和重新持久化。
-
這樣一來數據庫操作就隻有一個程序(多線程)來完成,不會給數據帶來壓力。
補充:
-
消息隊列除了可以用在高並發業務,其它隻要有相同需求的業務也是可以使用,如:短信發送中間件等。
-
高並發下異步持久化數據可能會影響用戶的體驗,可以通過可配置的方式,或者自動化監控資源消耗來切換時時或者使用異步,這樣在正常流量的情況下可以使用時操作數據庫來提高用戶體驗。
-
異步同時也可以指編程上的異步函數、異步線程,有的時候可以使用異步操作,把不需要等待結果的操作放到異步中,然後繼續後麵的操作,節省了等待的這部分操作的時間。
四、緩存
高並發業務接口多數都是進行業務數據的查詢,如:商品列表、商品信息
用戶信息、紅包信息等,這些數據都是不會經常變化,並且持久化在數據庫中。
高並發的情況下直接連接從庫做查詢操作,多台從庫服務器也抗不住這麼大量的連接請求數(前麵說過,單台數據庫服務器允許的最大連接數量是有限的),那麼在這種高並發的業務接口要如何設計呢?
設計考慮:
-
還是逆向思維,壓力在數據庫,那麼我們就不進行數據庫查詢?
-
數據不經常變化,我們為啥要一直查詢DB?
-
數據不變化客戶端為啥要向服務器請求返回一樣的數據?
方案設計:
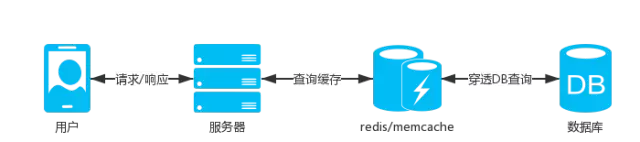
-
數據不經常變化,我們可以把數據進行緩存,緩存的方式有很多種,一般的:應用服務器直接Cache內存,主流的:存儲在memcache、Redis內存數據庫。
-
Cache是直接存儲在應用服務器中,讀取速度快,內存數據庫服務器允許連接數可以支撐到很大,而且數據存儲在內存,讀取速度快,再加上主從集群,可以支撐很大的並發查詢。
-
根據業務情景,使用配合客戶端本地存,如果我們數據內容不經常變化,為啥要一直請求服務器獲取相同數據,可以通過匹配數據版本號,如果版本號不一樣接口重新查詢緩存返回數據和版本號,如果一樣則不查詢數據直接響應。
-
這樣不僅可以提高接口響應速度,也可以節約服務器帶寬,雖然有些服務器帶寬是按流量計費,但是也不是絕對無限的,在高並發的時候服務器帶寬也可能導致請求響應慢的問題。
補充:
-
緩存同時也指靜態資源客戶端緩存;
-
CDN緩存,靜態資源通過上傳CDN,CDN節點緩存我們的靜態資源,減少服務器壓力;
-
Redis的使用技巧參考我的博文:
[大話Redis基礎]-https://blog.thankbabe.com/2016/04/01/redis/
[大話Redis進階]-https://blog.thankbabe.com/2016/08/05/redis-up/
五、麵向服務
-
SOA麵向服務架構設計
-
微服務更細粒度服務化,一係列的獨立的服務共同組成係統
使用服務化思維,將核心業務或者通用的業務功能抽離成服務獨立部署,對外提供接口的方式提供功能。
最理想化的設計是可以把一個複雜的係統抽離成多個服務,共同組成係統的業務,優點:鬆耦合、高可用性、高伸縮性、易維護。
通過麵向服務化設計,獨立服務器部署,均衡負載,數據庫集群,可以讓服務支撐更高的並發。
服務例子:用戶行為跟蹤記錄統計
說明:
通過上報應用模塊,操作事件,事件對象,等數據,記錄用戶的操作行為。
比如:記錄用戶在某個商品模塊,點擊了某一件商品,或者瀏覽了某一件商品
背景:
由於服務需要記錄用戶的各種操作行為,並且可以重複上報,準備接入服務的業務又是核心業務的用戶行為跟蹤,所以請求量很大,高峰期會產生大量並發請求。
架構:
-
nodejs WEB應用服務器均衡負載
-
Redis主從集群
-
MySQL主
-
nodejs+express+ejs+Redis+MySQL
-
服務端采用nodejs,nodejs是單進程(PM2根據cpu核數開啟多個工作進程),采用事件驅動機製,適合I/O密集型業務,處理高並發能力強
業務設計:
-
並發量大,所以不能直接入庫,采用:異步同步數據,消息隊列。
-
請求接口上報數據,接口將上報數據push到redis的list隊列中。
-
nodejs寫入庫腳本,循環pop redis list數據,將數據存儲入庫,並進行相關統計Update,無數據時sleep幾秒。
-
因為數據量會比較大,上報的數據表按天命名存儲。
接口:
-
上報數據接口
-
統計查詢接口
上線跟進:
-
服務業務基本正常
-
每天的上報表有上千萬的數據
六、冗餘,自動化
當高並發業務所在的服務器出現宕機時,需要有備用服務器進行快速的替代,在應用服務器壓力大的時候可以快速添加機器到集群中,所以我們就需要有備用機器可以隨時待命。
最理想的方式是可以通過自動化監控服務器資源消耗來進行報警,自動切換降級方案,自動地進行服務器替換和添加操作等,通過自動化可以減少人工的操作的成本,而且可以快速操作,避免人為操作上麵的失誤。
冗餘:
-
數據庫備份
-
備用服務器
自動化:
-
自動化監控
-
自動化報警
-
自動化降級
通過GitLab事件,我們應該反思,做了備份數據並不代表就萬無一失了,我們需要保證高可用性,首先備份是否正常進行,備份數據是否可用,需要我們進行定期的檢查,或者自動化監控, 還有包括如何避免人為上的操作失誤問題。(不過事件中Gitlab的開放性姿態,積極的處理方式還是值得學習的)
總結
高並發架構是一個不斷衍變的過程,冰洞三尺非一日之寒,長城築成非一日之功。打好基礎架構方便以後的拓展,這點很重要。

本文重新整理了高並發下的架構思路,並舉例了幾個實踐的例子,若你有更好的意見,歡迎留言。
相關閱讀:
原文發布時間為:2017-03-27
本文來自雲棲社區合作夥伴DBAplus
最後更新:2017-05-16 11:31:44