分布式實時數據處理實戰:從選型、應用到優化
本文根據DBAplus社群第94期線上分享整理而成。
講師介紹

盧譽聲
Autodesk資深係統研發工程師
-
《分布式實時處理係統:原理、架構與實現》作者。
-
Hurricane實時處理係統主要貢獻者。
-
多部C++領域譯作。
分享大綱:
1. 海量數據處理的挑戰
2. 基礎處理架構選型
3. 分布式係統結構設計
4. 性能調優和數據存儲(MongoDB)
一、海量數據處理的挑戰
隨著互聯網與計算機的普及,我們可以通過傳統途徑或互聯網收集到大量的數據,而在日常工作中對這麼大量的數據處理需求也與日俱增。日常遇到的數據種類非常多,從結構化的表格數據、到半結構化非結構化的文本圖像,我們需要掌握更多的技能與工具來學會如何處理這些數據。尤其在機器學習越來越熱的今天,更加有必要學會這個技術。
近兩年最火的恐怕就是深度學習,而深度學習又非常依賴數據量,很多時候不管網絡再怎麼精心設計,再怎麼使用技巧,也不如數據量來得實在。比如在我們這裏,就經常需要為此處理大量的文本和圖像數據。但在這個過程中,我們發現總是在做很多重複的工作。
總結一下,日常的工作模式抽象出來基本就是這麼幾件事:
-
將需要處理的數據輸出到一個列表文件(或者存到數據庫裏),每一項就是一個任務。
-
處理程序中開啟多個Worker線程,並為每個線程分配任務,線程執行自己的任務,並將結果輸出出來。
-
處理程序還需要記錄處理了哪些數據,哪些是成功的,哪些是異常的。
-
需要將這麼多個處理程序連接在一起完成數據處理任務。
二、基礎處理架構選型
日常工作模式:
-
為需要處理的數據建立列表
-
啟動程序,開啟多個Worker線程處理列表中的數據
-
將處理完的項目輸出到另一個列表中
-
啟動下一個程序,繼續開啟多個Worker線程處理列表中的數據
-
……
可以發現,這個需求其實就是一個簡單的生產者-消費者模式。我們其實是在建立一個任務隊列,然後讓Worker來取任務並執行任務。為了簡化這項工作,我自己寫了一個簡單的消息隊列以及生產者消費者的抽象,讓程序專注於數據處理的邏輯。
用戶隻需要建立一個MessageQueue(消息隊列),一個Feeder(消息源),一個Consumer(消息處理單元),並且實現Feeder和Consumer的具體邏輯(可以使用函數對象或者lambda表達式)。這樣就可以簡化日常的任務,但是經過長時間的工作後,發現這樣還是遠遠不夠,還需要經常處理以下問題:
-
如何分配任務?
-
任務失敗了怎麼辦?
-
如何保存任務狀態?
-
如何分布式計算?
我們來分別看一看:
1、如何分配任務?一開始我們采取的是按序號分配任務,每個任務執行連續一批任務。後來發現這樣會遇到很多問題,不如使用生產者消費者模式讓Worker自己領取任務。但由於缺乏統一的調度者,因此無法確保整體具有最高的計算效率。
2、如何處理任務失敗?我們一開始的方法是將成功任務和失敗任務分別放到兩個獨立列表裏,每次一個任務結束後都要重新處理失敗的任務,有非常多手動工作。
3、如何保存任務狀態?程序常常會因為各種原因在一半中斷(未完全測試的程序可能會內存泄漏、內存越界,即使程序沒有問題,也可能發生進程誤殺甚至是斷電等狗血的事情),因此我們需要保存任務狀態,下次啟動程序的時候可以自動跳過已經成功處理過的任務。
4、如何分布式計算?當數據過多時,需要手動分割數據放在幾個機器上執行,部署和手動管理成本很高。
後來我們發現Apache Storm的數據處理方式很適合解決這些問題。但是非常可惜,一方麵出於性能考慮,另一方麵為了更加容易地調用本地C++程序,這種基於Java的方式並不是那麼方便,每次還需要編寫JNI來接入我們的C++代碼。
於是,我們需要自己建立一套係統來解決這個問題。這套係統中包含這些東西:
-
使用NodeJS編寫的網絡爬蟲,因為NodeJS單線程異步非阻塞,簡化了高性能爬蟲的編寫工作。
-
使用MongoDB存儲數據,因為MongoDB是文檔型數據庫,而且可以無模式,處理圖像和網頁數據的時候非常方便。
-
使用Caffe來進行訓練和數據處理,由於我們的機器並不是特別多,這種情況下Caffe可以提供比Tensorflow更好的性能。
-
Hurricane實時處理係統( https://github.com/samblg/hurricane或https://hurricane-project.net),是Storm的計算模型在C++11中的實現,不過做了部分簡化和調整,以適應我們自己的工作。
三、分布式係統結構設計
這裏麵的關鍵就是Hurricane這個係統:

這張圖就是Hurricane的計算模型,Hurricane實時處理係統是一個基於流的分布式實時處理平台,其計算模型是Topology。每個Topology都是一個網絡,該網絡由計算任務和任務之間的數據流組成。
該模型中Spout負責產生新的元組,Bolt負責處理前一級任務傳遞的元組,並將處理過的元組發送給下一級。Spout是元組的生成器,而Bolt則是元組的處理單元。每個任務都會將數據封裝為元組傳遞給其他的任務。
在係統中任務被定義為Task。Task是對計算任務的統一抽象,規定了計算任務的統一接口。Spout和Bolt都是Task的特殊實現。為了處理這種分布式的計算模型,我們設計了自己的分布式係統架構,如下圖所示:

最上方的是President,這是整個集群的管理者,負責存儲集群的所有元數據,所有Manager都需要與之通信並受其控製。下方的是多個Manager,每個Manager中會包含多個Executor,每個Executor會執行一個任務,可能為Spout和Bolt。
從任務的抽象角度來講,每個Executor之間都會相互傳遞數據,隻不過都需要通過Manager完成數據的傳遞,Manager會幫助Executor將數據以元組的形式傳遞給其他的Executor。
Manager之間可以自己傳遞數據(如果分組策略是確定的),有些情況下還需要通過President來得知自己應該將數據發送到哪個節點中。
在這個基礎架構與計算模型之上,我們還設計了一套上層接口Squared:
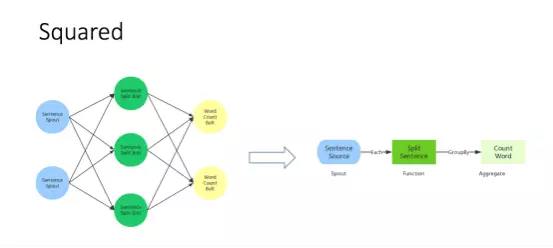
左側是Hurricane基本的計算模型,在該計算模型中,係統是一個計算任務組成的網絡。我們需要考慮每個節點的瑣屑實現。但如果在日常任務中,使用這種模型相對來說會顯得比較複雜,尤其當網絡非常複雜的時候。
為了解決這個問題,看一下右邊這個計算模型,這是對我們完成計算任務的再次抽象。
第一步是產生語句的數據源。然後每條語句需要使用名為SplitSentence的函數處理將句子劃分為單詞。接下來根據單詞分組,使用CountWord這個統計操作完成單詞的計數。
所以這個接口的本質是將網絡映射成了簡單的數據操作流程。解決問題和討論問題都會變得更為簡單直觀,現在我們來看看Hurricane的實際應用。
四、性能調優和數據存儲
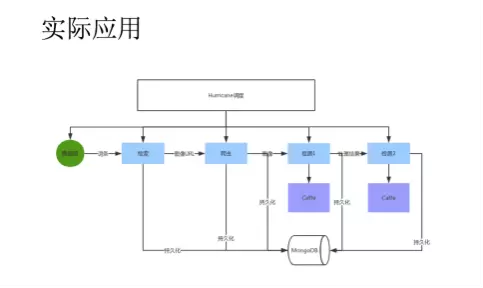
這是一個數據的預處理任務,我們需要從網絡上搜索一堆圖片,然後對圖片做初步處理(部分檢測任務),處理完成後將數據保存在數據庫中,作為日後的訓練數據使用。
使用Hurricane後這一切都變得非常簡單。我們使用一個Spout讀取數據庫中的任務,每一個任務是一個詞條,第一任務需要使用搜索引擎檢索這些詞條對應的圖像URL。
這個爬取工作會通過簡單的消息隊列傳給NodeJS,由NodeJS爬取並解析完網頁,抽取URL將結果返回給Spout。然後將圖像URL保存到數據庫中,並傳遞給下一個任務。
下一個任務會調度NodeJS將一批圖像都爬取並保存下來,這裏大家也可以自己使用C++編寫獲取數據與解析數據的程序,隻不過使用JS爬取數據和解析網頁比較方便,因此我們把這個任務交給JS完成了。
完成任務後將圖像數據傳遞給檢測器A,檢測器A完成檢測後將結果和圖像送給檢測器B,檢測器B完成最後檢測任務並將數據保存在數據中。最後處理完成的數據和圖像經過人工整理後將會作為日後訓練數據和測試數據的來源。
最後就是係統的優化問題了。
這裏很多是實際工程問題,比如在存儲大量數據時,由於MongoDB自身支持分布式存儲,所以處理起來非常方便。我們隻需要設定副本集,然後指定分片的字段就可以建立一個分布式集群,這裏比較講究的就是要根據實際情況選擇分片字段。
和傳統開源的MySQL方案相比還是比較簡單的,唯一不足就是MongoDB出現過宕機無法恢複的情況,所以日常額外的數據備份工作一定要進行。MongoDB不但自身支持分布式(副本和自動分片),而且還是本人使用過的檢索功能最強大的NoSQL數據庫之一,日常的許多業務任務都可以使用MongoDB處理。
日常使用NodeJS配合MongoDB可以快速構建足夠健壯的腳本與小型服務,MongoDB也支持對單個文檔的原子查找更新,合理設計後可以解決很多問題。
比如充當簡單的任務隊列,同時MongoDB中也可以建立全文索引,雖然沒有ElasticSearch那麼強大,但是已經可以滿足簡單的需求。最大的優點體現在處理半結構化數據、或者數據模型不確定的時候,比起需要反複修改表結構的關係型數據庫來說,MongoDB實在是方便。
當然MongoDB也存在很多問題:(拋磚引玉,個人感受,如有不當,望大家指正)
-
統計功能不夠強大,雖然有aggregate等功能,但比起關係型數據庫來說確實羸弱。
-
無法實現連表查詢,所以在設計數據模型時會和關係型數據庫方式不同,也無法完全替代關係型數據庫。
-
不支持事務,雖然MongoDB支持單文檔的原子操作,但是無法支持包含多個操作的事務,必須要自己處理這些問題,因此很多有事務要求的係統來說不一定適用。
當然這些隻是我在日常處理管理數據中的感受,也恰恰可以適應我們的工作。因為現在數據形式多種多樣,需求也多種多樣。隻不過在我們日常的數據處理過程中,Hurricane配合MongoDB等工具可以更好地流式處理半結構化與非結構化數據。
最後,一些其他特性:
-
保序
1)根據順序處理數據
2)使用Orderld和隊列實現保序
-
多語言支持
1)C
2)Java
3)Python
4)JavaScript
Q1:Hurricane係統開源嗎?
A1:hurricane real-time processing在Apache協議下開源,可以訪問
https://github.com/samblg/hurricane。歡迎想了解更多內容和感興趣的同學參與進來。
Q2:剛剛大神提到的mongo統計功能的aggregate,我們目前就遇到這問題,數據量並不大,十萬左右的數據吧,現在一個統計查詢要一秒多這個時間挺嚇人的,有沒有優化的辦法?
A2:aggregate並不是mongo的強項。在編寫aggregate語句的時候有許多要注意的,比如對設計到的字段盡可能建立索引,$match或者$sort之類的操作盡量放在整個操作流水線的前麵。提前用$match過濾數據,減少後麵數據的計算量,排序操作盡量在使用索引的字段上進行等等,如果MongoDB本身優化問題無法解決,那就隻能將計算壓力放在應用服務器上。盡量少地將數據分片取出到不同的應用服務器上,通過Hurricane這種實時分布式處理係統來完成統計工作,就能很好的解決這類問題---> Hurricane實時處理係統完全開源,不依賴任何第三方庫,易於維護和2次開發,相較其他係統,Hurricane 十分輕量級,可維護性高。
原文發布時間為:2017-03-07
本文來自雲棲社區合作夥伴DBAplus
最後更新:2017-05-16 10:31:36