SQL優化三板斧:精簡之道、驅動為王、集合為本
作者介紹
黃浩,現任職於中國惠普,從業十年,始終專注於SQL。在華為做項目的兩年多,做過大大小小的SQL多達1500個。閑暇之餘,喜歡將部分案例寫成博客發表在華為內部數據庫官方社區,反響強烈,已連續四個月蟬聯該社區最佳博主。目前已開設專欄“優哉悠齋”,成為首個受邀社區“專家訪談”的外協人員。
公元2016年8月1日晚上,朋友圈流行著這樣一個段子:特想摸清台風“妮妲”的威力有多大,一專業人士說:隻須一句話就能讓你深刻理解。遂追問,答曰:“就連華為都通知放假了?”感謝“妮妲”,讓深圳這座高速運轉的城市在星期二這天暫停了;感謝華為,讓我這個來深10年,為生活奔波勞頓的人也能倚在窗前,眼觀疾風驟雨之變,心遊驚濤駭浪之中。
妮妲走了,SQL來了
8月3日,一同事轉來一個SQL,我打開文件,發現整個代碼多達347行。




在DB中執行,時耗達到了4分多鍾,再往下鑽取,如同蝸牛一般,根本鑽不動,14分鍾過去了,還隻鑽取到了800行。

由此該SQL的性能表現為“兩慢”:首條返回慢、下鑽提取慢。大多數情況,我們隻會遇其一,要麼快速返回出現性能瓶頸,要麼全部提取出現性能瓶頸。這回好了,都齊全了。透過窗戶,望著被“妮妲”肆意狂虐後葉顫枝亂的樹木,心裏不禁在想:服務器也被“妮妲”肆虐了?
此時,台風“妮妲”瘋狂過後的溫馨涼意,也沒能讓我心如止水,畢竟這個優化任務看起來有些棘手。
人生若隻如初見
因為來者不善,而時間寬限,我也計劃打持久戰。在展開分析前,我對SQL中的表對象和數據量做了初步統計。如下:

人生若隻如初見,初見往往是美妙的,讓人心曠神怡的。而與該SQL的初次交流,畫麵卻是暗潮湧動殺機四伏:
-
動輒千萬上億的數據量,近40次對象訪問,還不包括VIEW中的表對象。
-
從SQL代碼上看,出現了聚合函數,因此可以斷定是批量數據處理。
以上兩點,按經驗,能2分鍾跑出來就不錯了,現在是要求2~3S,看起來是一個不可完成的任務。
第一板斧:大刀闊斧
在初步分析中,ORDER_RELEASE和ORDER_RELEASE_REFNUM兩個表是最搶眼的,數據量分別是千萬級和億級,訪問次數更是驚人的達到了10次以上。好奇心我決定以這兩個表為切入口,探究下是如何被訪問的?
借助於NOTEPAD++編輯神器,很快定位到了這兩個表的訪問情況:

初步一看:
-
這兩個表的訪問基本上都是在子查詢中,而且都是成對出現
-
仔細對比了子查詢後,發現這些子查詢可分A、B兩類
-
A類子查詢共有5個的代碼都是完全一樣的,如下:

4、B類子查詢共有3個的代碼都是完全一樣的,如下:

深入子查詢內部,無論是A類子查詢還是B類子查詢,ORDER_RELEASE R和ORDER_RELEASE_REFNUM O_REF的關聯方式都是一樣的,關聯字段是ORDER_RELEASE_GID。此時,結合兩個表的命名,按多年的經驗,我猜想:
-
ORDER_RELEASE_GID為ORDER_RELEASE表的主鍵字段
-
ORDER_RELEASE_REFNUM與ORDER_RELEASE表存在主外鍵約束,字段就是ORDER_RELEASE_GID
為了驗證我的假設,我VIEW了ORDER_RELEASE_REFNUM的表結構,如下:

果真如此。那麼問題來了,即便如此,我們又能做什麼呢?答案很簡單,這兩類子查詢中,ORDER_RELEASE表可以被“砍掉”。等價的SQL如下:
A類:

B類:

再看看這個子查詢的數據量:

隻有8千多條,相對於千萬上億,已經是非常少的數據量了。
結合上述分析結果,我對SQL做了如下調整:
-
將A、B類子查詢用兩個with子查詢代替,這樣就能減少大表的訪問次數;
-
在A、B類子查詢中,將ORDER_RELEASE表“砍掉”,減少表關聯帶來的IO開銷;
-
由於子查詢的數據量非常小,將之前的IN子查詢改寫為INNER JOIN,這樣就可以形成小結果集驅動大表的效果。
調整後的代碼如下:



對於這次的優化,我並沒有抱什麼希望,因為這僅僅是常規性的精簡,還沒有深入到代碼內部。或者說,這還僅僅是規範性改寫。
果真,執行仍然需要耗時4分多鍾,但是,這次的精簡並不是沒有任何收益。因為當往下鑽取時,速度非常快,鑽取完6625條記錄不到10S。

不知不覺中,已到了下班時間。台風過後,殘陽西下,不再燥熱,難違暖意,別有一番韻味。
第二板斧:披荊斬棘
第二天一上班,就開始接著昨天的節奏繼續優化。
SQL的精簡並沒有為快速返回帶來任何收益,我決定看下執行計劃,嚐試著從執行計劃中得到更多的信息。果真,F5後看到的執行計劃中,一個VIEW的COST猶如“鶴立雞群”,特別的紮眼:

從執行計劃看,Oracle對這個視圖做了傳統的處理,沒有合並,也沒有謂詞推入。所以視圖中的表基本上都是table access full。此時,突然想起在當時統計表對象的時候,記得隻有一個視圖,而在昨天在精簡B類子查詢的時候,也出現過一個視圖。那這兩個視圖應該是同一個了。而昨天B類子查詢的速度是非常快的。
我趕緊將執行計劃定位到了B類子查詢,如下:
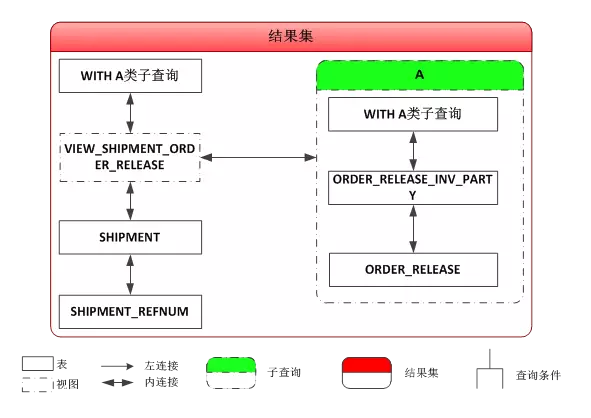
原來如此,在B類子查詢中,該視圖被merge了。
受此啟發,我也計劃將主查詢中的VIEW通過HINT進行MERGE,但是HINT似乎並不生效,始終都無法改變現有的執行計劃。無奈之際,隻有深入SQL,實地窺探這個VIEW到底“何德何能”,會讓ORACLE優化器如此“死心塌地”的“維持原判”。

從上圖中可以看出,該視圖與A類子查詢進行了關聯,而事實上,B類子查詢就是該視圖與A類子查詢關聯的結果呀。怎麼在這裏又要臨時關聯呢?難道昨天做精簡的時候還存在漏網之魚?
再看代碼:

原來這裏需要獲取該視圖的兩個字段,而在B類子查詢中,我們隻獲取了SHIPMENT_GID一個字段。那是否可以直接在B類子查詢中加一個字段呢?
我們再來看看B類子查詢的代碼邏輯:

在這裏,我們獲取了SHIPMENT_GID字段,並對該字段通過DISTINCT去除了重複值。這樣做的目的在於,在後麵調用該子查詢時,以該子查詢為驅動表,驅動關聯其他表對象。因為子查詢的結果集很小,而被關聯的表對象都是千萬上億級別的。
很顯然,如果我們在B類子查詢中增加ORDER_RELEASE_GID字段,就會影響到SHIPMENT_GID的唯一性,這樣,在後續的關聯查詢中,就不能直接用B類子查詢驅動關聯。這會直接破壞掉已經建立好的驅動關係。
既然增加字段之路行不通,那就嚐試著再增加一個WITH子查詢,代碼如下:

與此同時,對訪問該視圖的代碼也進行了適應性的修改,修改後的腳本如下:




再次執行,耗時2:28,雖然與秒級的性能要求相距甚遠,但是至少性能提升了近50%,其意義並在於提升的效果,而在於證明了優化方向是正確的,即在大表林立群狼環視虎視眈眈的環境中,要快速準確的定位出驅動表,需要明確將驅動表數據準備好。
第三板斧:神工鬼斧
性能尚未達標,優化仍需繼續。
先看看執行計劃:

從COST列,並沒有看到成本特別高的操作。所以,我放棄了繼續在執行計劃上做文章,轉而深入分析SQL代碼邏輯。
經過一番抽絲剝繭起承轉合後,SQL的整體代碼邏輯也唿之欲出,發現頂層的邏輯設計非常簡單明了,就是三個子查詢的結果集內連接,如下圖所示:

接下來,我做了一件被人“鄙視”的小兒科的事,就是分別執行了這三個子查詢。原本想著總會有一個慢的,我就重點優化慢的那個子查詢。而結果卻出人意表,三個子查詢都是在2S左右就能完成執行,而且數據量都在1萬以內。那為何三個子查詢關聯在一起,性能會如此受影響呢?要知道,如果是三個1萬以內的表關聯,即便是無任何索引,那也是秒出呀。
那麼問題出在哪裏呢?沒的說,肯定是執行計劃並沒有按我們預想的去執行這個SQL。此時,我也沒有心思去仔細分析執行計劃,而是直接祭出了第三板斧通過with子查詢的方式將ORDER_REL、SHP、REL三個子查詢封裝成結果集,改寫後的SQL如下:





再看執行計劃:

看起來與我們預期的效果一致了,而關鍵還是要看執行的效率。

3.5S,再往下鑽取,也不到10s皇天不負有心人,終於可以畫“句號”了。此時,已經是第三天上午,距離拿到原始SQL將近2天的時間了。台風“妮妲”早已銷聲匿跡,來也匆匆去也匆匆。你方唱罷我登場,立秋前的燒烤模式再次以勝利者的姿態,歇斯底裏的“蒸烤”著這片大地。而躲在空調房的人類,也在盡情的透支著地球賜予的有限資源,最終會如同這個SQL一樣,終有一天會引發災難;而再去治理,再去挽救,需要花費更多的資源與精力。
後記
從4分鍾到3.5S,從鑽取卡頓到一瀉千裏,整整經曆了近2天時間,耗時之長在以往的優化案例中實屬少見。事實上,當一開始拿到這個SQL時,尤其是在了解到這個SQL及背後的數據環境時,我心裏麵是直打鼓的。可以說,是硬著頭皮拿下了這個SQL,現在回想起來仍然後怕。然而,除了後怕,更多的是該案例優化過程中所體現出的SQL(優化)精髓:精簡之道、驅動為王、集合為本。
精簡之道
大道至簡、簡單即高效、複雜的事情簡單化等等這些我們喜聞樂見的生活常識,同樣適用於SQL(優化)。記得SQL優化大師曾說過:不要讓ORACLE做多餘的事。而對於ORACLE而言,多餘的事情是什麼呢?多餘的表關聯、重複的表訪問、冗餘的關聯(過濾)條件、不必要的DISTINCT\ORDER BY\GROUP BY、曲折的訪問路徑。雖然ORACLE優化器引擎也在努力識別並消除這些“多餘的事 ”(可參見博客,然而,在麵對複雜的SQL時,ORACLE也往往束手無策。因此,SQL優化的首要之事就是精簡SQL。
驅動為王
有這樣一句話:一頭獅子領著一群羊,要勝過一頭羊領著一群獅子。這就道出了“領頭”的重要性,在ORACLE優化器中,就是“驅動表”。驅動表的意義有如木楔子,隻有薄如紙片銳如刀刃的楔子,才能輕而易舉的插入堅硬木樁中。如果給你一個圓頭的木頭,任憑你力氣再大,也不能插入。這就要求驅動表的數據量要足夠的少。盡管ORACLE優化器也在努力尋找合適的“領頭”,而有的時候,ORACLE優化器會被腰裏別了杆槍的老鼠給騙了。比如本案例中的A類子查詢,起初是通過IN子查詢進行過濾的,這就存在很大的性能風險。關於驅動表的優化案例有很多,後續會專題分享。
集合為本
集合操作是二維關係數據庫引擎在數據處理時的根本,單表是一個集合,多表關聯後的結果也是一個集合,視圖、子查詢的返回結果還是一個集合,整個SQL執行完後的結果仍然是一個集合。
因此,一個高效的SQL一定有一個合理的集合運算結構。根據業務需求,結合代碼邏輯,有的時候需要將代碼片通過子查詢封裝;而有的時候又需要將子查詢合並到主查詢中;有的時候需要將大集合根據業務邏輯切片成多個小的集合;有的時候又需要將若幹個小的集合預先合並成大集合。總之,在進行SQL(優化)時,一定要有集合的概念,用集合的思維指導SQL(優化)。
原文發布時間為:2016-11-16
本文來自雲棲社區合作夥伴DBAplus
最後更新:2017-05-13 08:47:00