某政務網站性能優化__最佳實踐_性能測試-阿裏雲
門戶類網站性能測試分析及調優
1 背景
前段時間,性能測試團隊經曆了一個規模較大的門戶網站的性能優化工作,該網站的開發和合作涉及多個組織和部門,而且網站的重要性不言而喻,同時上線時間非常緊迫,關注度也很高,所以對於整個團隊的壓力也非常大。
在此,把整個經曆過程給大家分享一下,包括了主要包括了如何使用性能測試的壓測工具,壓測前的性能問題評估,以及壓測執行後的性能問題分析、瓶頸定位。
該門戶網站的服務器是放在華通和阿裏雲的平台上的,所以對華通和阿裏共建的雲平台安全及應急措施方麵要求非常高,需要團隊給予全力的保障和配合。
性能測試(Performance Testing)是集測試機管理、測試腳本管理、測試場景管理、測試任務管理、測試結果管理為一體的性能雲測試平台,可以幫助您全方位的評估雲上係統性能。
本次優化主要是使用了該測試平台服務對客戶搭建在ECS上的服務器進行多種類型(性能測試、負載測試、壓力測試、穩定性測試、混合場景測試、異常測試等)的性能壓測、調試和分析,最終達到滿足期望預估的性能目標值,且上線後在高峰期滿足實際的性能和穩定要求。
2 術語定義
在介紹項目經曆之前,再明確一下測試當中用到的專業指標術語定義,包括但不僅限於以下:
PV: 即PageView, 即頁麵瀏覽量或點擊量,用戶每次刷新即被計算一次。我們可以認為,用戶的一次刷新,給服務器造成了一次請求。
UV: 即UniqueVisitor,訪問您網站的一台電腦客戶端為一個訪客。00:00-24:00內相同的客戶端隻被計算一次。
TPS:TPS(Transaction Per Second)每秒鍾係統能夠處理的交易或事務的數量,它是衡量係統處理能力的重要指標。
響應時間: 響應時間是指從客戶端發一個請求開始計時,到客戶端接收到從服務器端返回的響應結果結束所經曆的時間,響應時間由請求發送時間、網絡傳輸時間和服務器處理時間三部分組成。
VU: Virtual user,模擬真實業務邏輯步驟的虛擬用戶,虛擬用戶模擬的操作步驟都被記錄在虛擬用戶腳本裏。一般性能測試過程中,通俗稱之為並發用戶數。
TPS波動: 係統性能依賴於特定的硬件、軟件代碼、應用服務、網絡資源等,所以在性能場景執行期間,TPS可能會表現為穩定,或者波動,抑或遵循一定的上升或下降趨勢。我們用TPS波動係數來記錄這個指標值。
CPU: CPU資源是指性能測試場景運行的這個時間段內,應用服務係統的CPU資源占用率。CPU資源是判斷係統處理能力以及應用運行是否穩定的重要參數。
Load: 係統正在幹活的多少的度量,隊列長度。係統平均負載,被定義為在特定時間間隔(1m,5m,15m)內運行隊列中的平均進程數
。
I/O: I/O可分為磁盤IO和網卡IO。
JVM: 即java虛擬機,它擁有自己的處理器、堆棧、寄存器等,還有自己相應的指令係統。Java應用運行在JVM上麵。
GC: GC是一種自動內存管理程序,它主要的職責是分配內存、保證被引用的對象始終在內存中、把不被應用的對象從內存中釋放。FGC會引起JVM掛起。
網速: 網絡中的數據傳輸速率,一般以Byte/s為單位。通過ping延時來反映網速。
流量: 性能測試中,一般指單位時間內流經網卡的總流量。分為inbound和outbound,一般以KB為單位。
3 評估
本次性能測試過程的參與人包括了阿裏雲應急保障小組等多部門人員,網站為外部供應商開發,阿裏雲提供雲主機和技術支持。
該網站之前前期也由其他部門做了驗收工作,進行了完整的性能測試,報告顯示,性能較差,第一次測試,網站並發數沒有超過35個,第二次測試,網站上做了優化後,靜態頁麵縮小後,並發用戶數100內 5s ,200內 90%響應在15s以上,隨著並發用戶數的增加,頁麵響應最高可到20多秒,而且訪問明顯感覺較慢,所以聯係了阿裏雲的技術支持,希望能夠幫助診斷性能問題,給出優化建議。
| 測試業務 | 並發用戶數 | 平均響應時間(秒) | 90%響應時間(秒) |
|---|---|---|---|
| 首頁瀏覽 | 100 | 12.082 | 15.289 |
| 200 | 23.949 | 29.092 | |
| 分頁瀏覽 | 100 | 8.973 | 12.343 |
| 200 | 18.846 | 24.106 |
經過會議討論後,評估出最終的測試目標:帶頁麵的所有靜態資源一起,響應時間必須小於5秒,同時並發訪問用戶數最低500,TPS根據實際的結果來得出。
4 性能測試目標
- 並發用戶數:>=500
- 業務響應時間:<5秒
5 分析
通過性能測試前端分析工具(未開放)分析,頁麵的響應時間88%左右都是消耗在前端資源加載上,服務器端消耗隻占到了頁麵響應的12%左右;
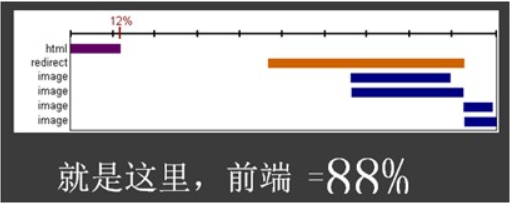
一個網站的響應一般由四部分時間組成,前端、網絡、服務器和數據庫,前端主要是減小頁麵大小,減小頁麵請求數,優化頁麵js等,網絡主要是使用CDN,優化連接數等,服務器主要是優化Apache,優化Tomcat,優化java代碼等,數據庫是優化sql語句,優化索引,優化數據存儲等。<rb>

6 測試和優化
6.1 頁麵前端分析及優化
我們對頁麵的優化仍然從前端開始,首先通過性能測試的前端測試工具(未開放)進行掃描,我們發現以下問題並優化:
- Js較大,無壓縮,同時存在重複請求,最多一個js加載4次,已做壓縮和減少。
- Js位置不合理,阻礙頁麵加載。
- 外部css 考慮本地實現,減少調用
- Banner 背景圖片較多,無壓縮,建議合並
- 頁麵1的後台.do有4個,減少為3個
- 頁麵2的後台do有 2個,減少為1個
- 存在加載失敗鏈接,404失敗,同時次數非常多,更換為cnzz
- 頁麵加載外部資源失敗 (qq等),且不穩定
- 分享功能比較慢
- 外部資源建議異步實現,目前全部是jquery渲染,iframe嵌套,時間資源限製,後期優化
- 盡量減少或者不使用iframe
- 頁麵請求數太多,主要是js和css重複加載問題和圖片較小導致的。 經過以上修改及配置服務器靜態資源緩存後,性能提高25%,首頁響應從1.5秒提高到1.1秒,並且前端優化持續進行。
6.2 服務端優化
一般核心頁麵都要求在300毫秒以下,非核心頁麵要求在500毫秒以下,同時重點關注並發時的負載和穩定,服務器端代碼和響應的快速穩定是整個頁麵性能的重點。
6.2.1 腳本編寫及場景構造
根據前期需求評估的內容,客戶是一個門戶網站,主要由不同功能頁麵組成的,各個功能頁麵當中又包含了靜態內容和異步動態請求,所以,性能測試的腳本的編寫主要涵蓋了各頁麵的請求和相關靜態資源的請求,這裏存在一個串行和並行的概念:
串行:請求的頁麵和頁麵當中的靜態資源、異步動態請求組成一個同步請求,每一個內容都作為一個事務(也可以共同組成一個事務,分開事務的好處是可以統計各部分的響應時間),這樣壓測任務執行時,線程就會根據事物的順序分布調用執行,相當於一個頁麵的順序加載,弊端是無法模擬實際IE的小範圍並發,但這樣測試的結果是最嚴格的。
並行:各個頁麵之前可以使用不同的任務,采用並行的混合場景執行,同時設置一定的比例(並發用戶數),保證服務器承受的壓力與實際用戶訪問相似。
場景並發用戶數:經常會遇到“設置多大並發用戶數合適?”的問題,因為在沒有任何思考時間的時候,我們有一個簡單的公式:
VU(並發壓測用戶數) = TPS(每秒執行事務數) × RT(響應時間)
所以,在尋找合適的並發用戶數上,建議使用性能測試的“梯度模式”,逐漸增加並發用戶數,這個時候壓力也會越來越大,當TPS的增長率小於響應時間的增長率時,這就是性能的拐點,也就是最合理的並發用戶數;當TPS不再增長或者下降時,這個時候的壓力就是最大的壓力,所使用的並發用戶數就是最大的並發用戶數。如果此時的TPS不滿足你的要求,那麼就需要尋找瓶頸來優化。如下圖演示的一個性能曲線: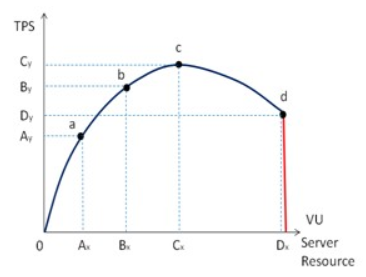
- a點:性能期望值
- b點:高於期望,係統安全
- c點:高於期望,拐點
- d點:超過負載,係統崩潰
注意:使用外網地址壓測可能會造成瞬時流量較大,造成流量計費,從而產生費用,建議可以使用內網地址壓測,避免損失。
6.2.2 第一階段
在按照客戶提供的4個URL請求構造場景壓測以後,同時根據實際情況和客戶要求,使用性能測試,構造相應的場景和腳本後,模擬用戶實際訪問情況,並且腳本中加上了img、js、css等各一個的最大靜態資源:
- 條件:5台ECS機器,200並發用戶數,一個後台頁麵加3個靜態頁麵(共150K)
- 結果:靜態4000TPS,動態1500TPS,服務器資源:CPU 98%
分析和優化:
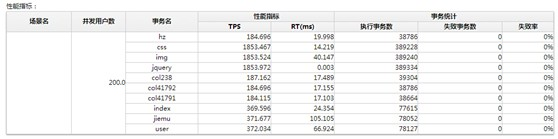
服務器資源消耗較高,超過75%,存在瓶頸,分析平台顯示:
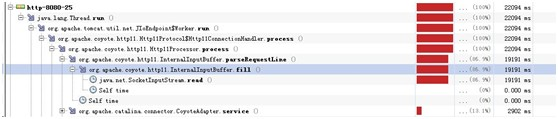
分析發現原來是apache到tomcat的連接等待導致,現象是100個並發壓測,就有100個tomcat的java線程,而且全部是runnable的狀態,輪詢很耗時間。
同時發現用戶使用的是http協議,非ajp協議,不過這個改動較大,需要使用mod_jk模塊,時間原因, 暫緩。
解決方法:修改了Apache和tomcat的連接協議 為nio協議,同時去除ssl 協議。Tomcat連接數據庫池由30初始調整為300,減少開銷<Connectorport="8080" protocol="org.apache.coyote.http11.Http11NioProtocol" connectionTimeout="20000" redirectPort="8443" />
性能對比:
- 再進行1輪壓測含動態含靜態文件,TPS能夠從1w達到2.7W,性能提高將近3倍,並且tomcat的線程從原來的200跑滿,降到100附近並且線程沒有持續跑滿,2.6W TPS時候CPU在80%附近
發現機器的核數都是2核,8G內存,對於CPU達到98%的情況,CPU是瓶頸,而對於應用來說比較浪費,所以將2核統一升級為4核。
擴展機器資源,從目前的4台擴到6台,同時準備4台備份,以應對訪問量較大的情況。
思考和風險:
- 異步請求處理:客戶所提供的url都是html靜態,雖然頁麵當中含動態數據,但分析後發現動態數據都是通過jquery執行然後iframe嵌套的,所以不會隨著html文件的加載而自動加載,需要分析所有的動態頁麵,同時壓測,這是頁麵存在異步請求需要關注的地方。
- Iframe:Iframe嵌套頁麵的方式優點是靜態資源調用方便、頁麵和程序可以分離,但是它的缺點也顯而易見,包括樣式、腳本額外注入,增加請求等等;還有搜索引擎搜素不到內容;iframe創建比其他元素慢1~2個數量級;資源重複加載;iframe會阻塞頁麵加載,阻塞onload事件;占用主頁連接池;html5不再支持。所以建議盡量不要使用或者少使用。
- [font='Times New Roman']: 腳本錄製和模擬實際用戶訪問。當用戶的圖片、javascript、CSS等靜態資源和後端代碼在同一台服務器上時,需要模擬用戶的實際訪問請求,壓測腳本涵蓋所有鏈接和資源。那麼使用腳本錄製功能就可以采集更全更完整的腳本。
6.2.3 第二階段
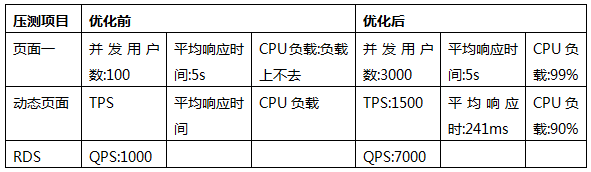
找到幾個頁麵的所有動態資源後,整合成為一個事務,串行訪問,同時並發壓測,從而對純服務器端進行壓測,測試結果如下圖:
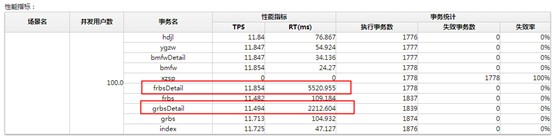
性能分析:頁麵一和頁麵二的響應時間分別達到了5秒和2秒,性能較差,整體TPS隻有11
- 性能分析:
分析發現響應時間高的原因主要在RDS數據庫上,數據庫此時的CPU已經達到100%,處理較慢,懷疑跟sql有關,分析慢sql。 - 優化方法:
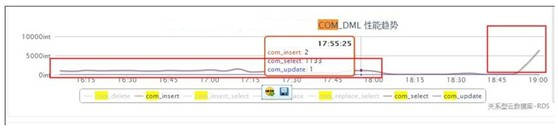
數據庫第一批優化完畢,優化了6條sql語句之前5s左右,優化後在150ms左右,數據庫的QPS 從1k上升到6k。 - RDS優化內容包括:
優化點主要是調整慢sql的索引,部分sql需要調整表結構和sql寫法,需要應用配合才能完成優化,優化前QPS在1000左右,優化後QPS到達6000
前端響應時間從5秒降低到150毫秒,前台TPS由150提升到1500.總的TPS可以達到2000。
6.2.4 第三階段
通過性能測試模擬用戶實際訪問情況,包括所有靜態資源,評估出當響應時間小於5秒的時候,最大支撐的並發用戶數。
- 測試結果:
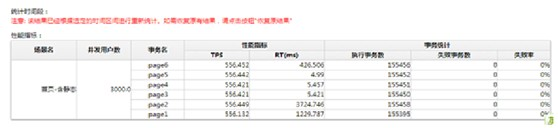
可以看到,所有的事務RT加起來小於5秒的情況下,並發用戶數可以達到3000(6個事務,6個腳本,每個腳本500),遠遠滿足項目500個並發用戶的目標。
- 總結:
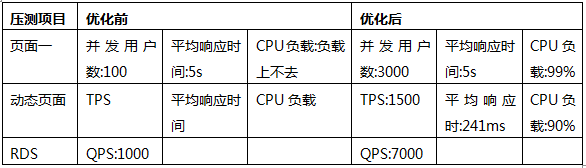
6.2.5 第四階段
評估其他非主站應用的性能以及含靜態頁麵的其他5個頁麵內容,包括:
- 搜索壓測
- 操作壓測
- 登錄壓測
- 證書登入
- 針對5個常用場景進行混合壓測
測試結果:
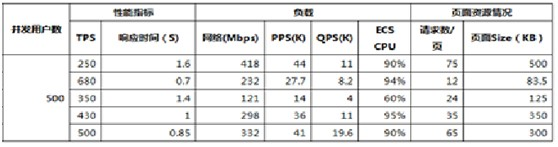
發現的風險和問題:
- 測試發現,流量存在非常明顯的波動,不經過某模塊就無此問題,發現有大量的reset連接,會診後總結:端口複用導致的問題。FULL NAT模式和LVS存在兼容性問題。最終結果: 由於存在兼容性問題,影響到網站的穩定性和性能,暫時加載該模塊,待問題解決後再加。先使用另外一個模塊代替
- .淩晨2點,針對單點用戶登入進行了壓測,發現100並發,該業務接口已宕機,分析結果:Cache緩存設置太小,1G內存容量導致內存溢出,已建議修改為4G。使用http協議性能不佳,早上4點30進行少量代碼優化後,業務直接不可用,環境出現宕機無法修複,我們快速進行快照恢複,5分鍾內恢複3台業務機,雲產品的優勢盡顯。用戶log日誌撐滿係統盤,並且一直不知這台雲主機還有數據盤,產品上我們要做反思。幫助用戶已進行掛盤及日誌遷移至數據盤,減少單盤的IO壓力。
- Web服務器數據同步,發現服務器io和cpu壓力過大。加入inotify機製,由文件增量同步,變更為文件係統的變化通知機製。將冷備及4台備用web機器使用該方式同步,目前,查看內容分發主機IO和CPU使用率已回複正常範圍同步推送時間,根據服務器的負載,進行調整同步時間。今天已修改為2分鍾。 由於備份量大,晚上進行全量同步。新增4台備用機,已關閉apache 端口 自動從slb去除,作為冷備
- 由於目前單點用戶登入入口存在架構單點宕機風險,進行登入和未登入風險驗證,確認,如用戶已登入後,登入業務係統出現宕機,進行簡單的頁麵點擊切換,不受影響
- 內存優化
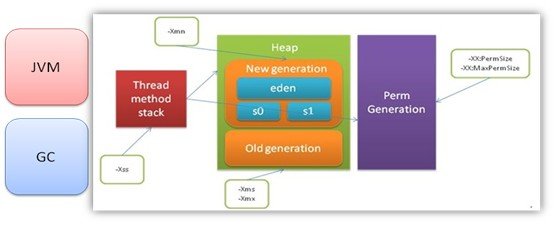

按照JVM內存管理模式,調整係統啟動參數,如果一台ECS部署一台服務器,建議不要選擇默認的JVM配置,應該設置內存為物理內存的一半,同時設置相應的YTC和FGC策略,觀察Old區變化,避免大量Full GC,建議Full GC頻率大於1小時,同時GC時間小於1秒鍾。
6.3 架構優化
- 單點登錄服務修改為SLB
- 檢索 修改為 SLB
- 內容管理雲平台雲服務器實現行文件差異同步,同時冷備
- 新增4台web機器
7 總結
備注:服務器的CPU達到100% 這其實是一個好的現象,說明我們的邏輯全部已經走到了資源消耗上,而不是由外部其他邏輯限製或blocked,這種現象帶來的好處就是,首先我們可以集中精力從減少代碼的資源消耗上解決問題,帶來性能的改善,其次,實在無法優化我們也可以增加機器台數,橫向擴展來讓性能成倍的提高,這也是用成本換性能的方法。當然,前提是架構上支持負載均衡的分布式架構。
總的來說就是,這種情況要不選擇從縱向優化,或者選擇從橫向擴展,都可以增加。
8 遺留問題
- 時間原因,測試頁麵有限,有些頁麵沒有測試覆蓋到,比如後台頁麵。
- 登錄係統存在內存風險,由於用戶的緩存信息仍然存在單點問題,所以風險較大,同時係統壓力不滿足要求,並發較高存在crash風險,未來得及發現瓶頸所在。徹底解決必須使用OCS等緩存係統改造,同時優化數據庫。
- Iframe框架造成用戶體驗不好,需要改掉,換成異步js接口方式。
- 後台同步係統,對於資源消耗影響較大,需要持續優化。
- 平台應該提供開發和測試進行自主壓測、分析、評估,同時提供統一的測試報告,保證各部分模塊的性能,整合起來才能保障整個門戶網站的性能。
- CPU優化還需要繼續分析跟進,目前隻是增加機器資源降低風險,成本較高。
- 上線發布應該具備統一的回歸驗證機製,並且日常需要持續優化,避免由於後期代碼的改動導致性能下降。
最後更新:2016-05-06 10:44:37
上一篇: 腳本模塊使用說明__SDK使用手冊_性能測試-阿裏雲
腳本模塊使用說明__SDK使用手冊_性能測試-阿裏雲
下一篇: 大規模分布式壓測__最佳實踐_性能測試-阿裏雲
- 負載均衡路由__服務發現和負載均衡_用戶指南_容器服務-阿裏雲
- 文本分析__使用手冊(new)_機器學習-阿裏雲
- 8.4 使用阿裏雲數據傳輸實時同步RDS的數據__第八章 在生產中使用分析型數據庫_使用手冊_分析型數據庫-阿裏雲
- 創建事務__腳本開發_Lite用戶使用手冊_性能測試-阿裏雲
- DescribeLoadBalancerUDPListenerAttribute__Listener相關API_API 參考_負載均衡-阿裏雲
- OSSWriter__Writer插件_使用手冊_數據集成-阿裏雲
- 新建用戶__用戶管理_DMS for MongoDB_用戶指南(NoSQL)_數據管理-阿裏雲
- 後端ECS為何訪問不了負載均衡實例__後端 ECS 服務器常見問題_常見問題_負載均衡-阿裏雲
- 基本介紹__運維中心手冊_用戶操作指南_大數據開發套件-阿裏雲
- 已支持領域__語義表示協議_自然語言理解(NLU)_智能語音交互-阿裏雲
相關內容
- 常見錯誤說明__附錄_大數據計算服務-阿裏雲
- 發送短信接口__API使用手冊_短信服務-阿裏雲
- 接口文檔__Android_安全組件教程_移動安全-阿裏雲
- 運營商錯誤碼(聯通)__常見問題_短信服務-阿裏雲
- 設置短信模板__使用手冊_短信服務-阿裏雲
- OSS 權限問題及排查__常見錯誤及排除_最佳實踐_對象存儲 OSS-阿裏雲
- 消息通知__操作指南_批量計算-阿裏雲
- 設備端快速接入(MQTT)__快速開始_阿裏雲物聯網套件-阿裏雲
- 查詢API調用流量數據__API管理相關接口_API_API 網關-阿裏雲
- 使用STS訪問__JavaScript-SDK_SDK 參考_對象存儲 OSS-阿裏雲