![]() 668
668
![]()
![]() 技术社区[云栖]
技术社区[云栖]
MapReduce开发插件介绍__Eclipse开发插件_工具_大数据计算服务-阿里云
选择ODPS项目中的WordCount示例:
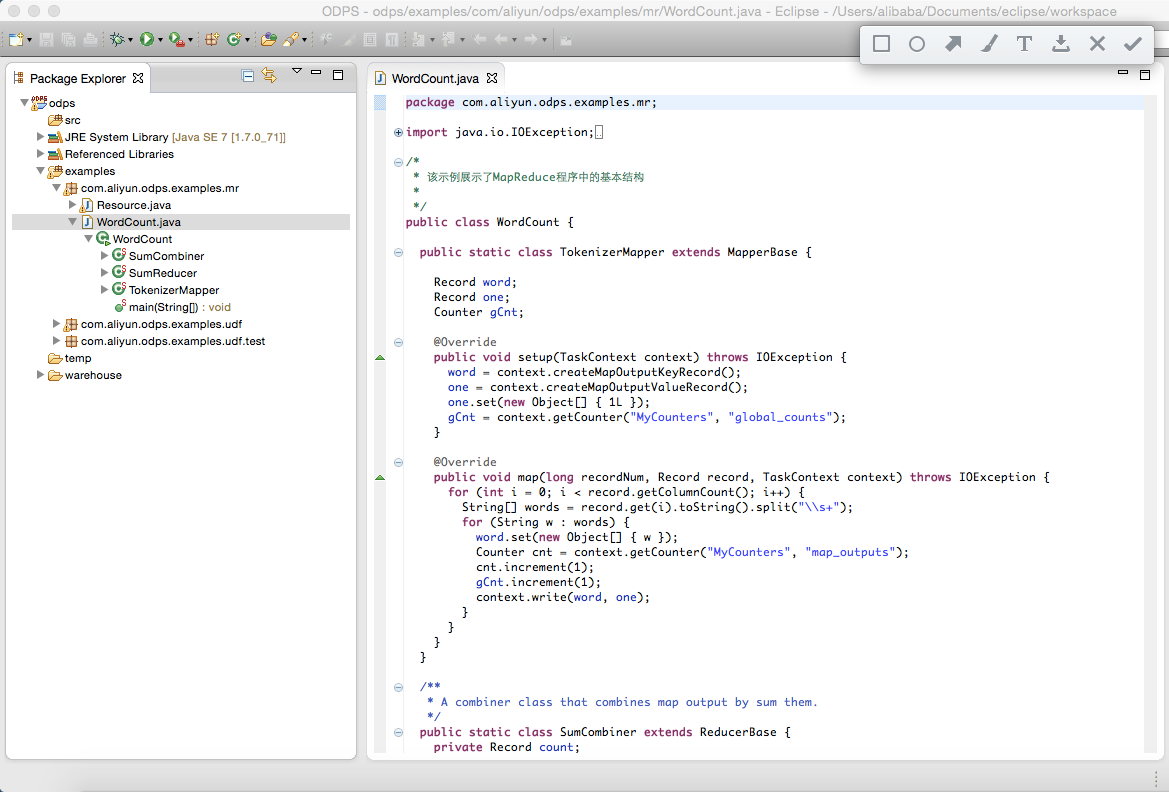
右键”WordCount.java”,依次点击”Run As”,”ODPS MapReduce”:

弹出对话框后,选择”example_project”,点击确认:
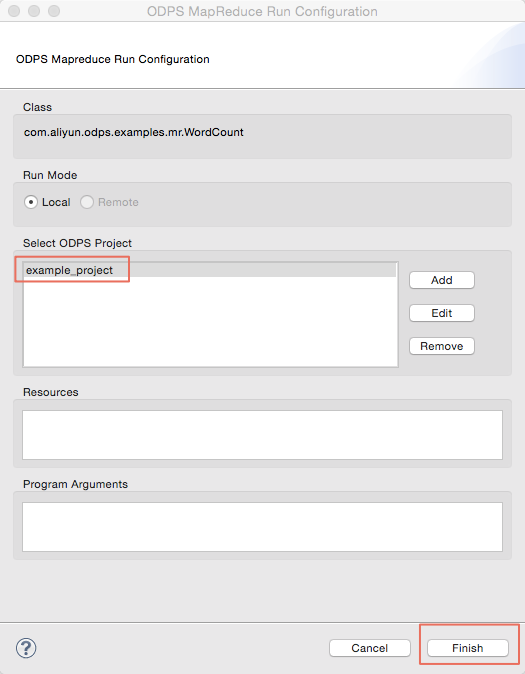
运行成功后,会出现以下结果提示:

运行自定义MapReduce程序
右键选择src目录,选择新建(New) -> Mapper:
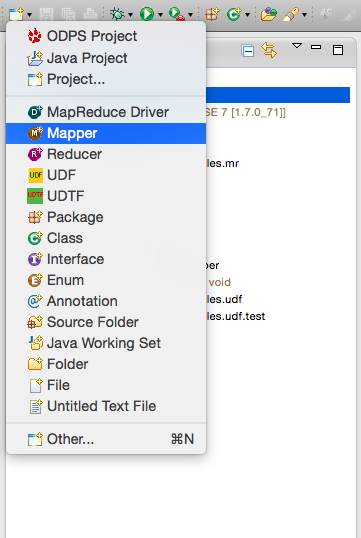
选择Mapper后出现下面的对话框。输入Mapper类的名字,并确认:

会看到在左侧包资源管理器(Package Explorer)中,src目录下生成文件UserMapper.java。该文件的内容即是一个Mapper类的模板:
package odps;import java.io.IOException;import com.aliyun.odps.data.Record;import com.aliyun.odps.mapred.MapperBase;public class UserMapper extends MapperBase {@Overridepublic void setup(TaskContext context) throws IOException {}@Overridepublic void map(long recordNum, Record record, TaskContext context)throws IOException {}@Overridepublic void cleanup(TaskContext context) throws IOException {}}
模板中,将package名称默认配置为”odps”,用户可以根据自己的需求进行修改。编写模板内容:
package odps;import java.io.IOException;import com.aliyun.odps.counter.Counter;import com.aliyun.odps.data.Record;import com.aliyun.odps.mapred.MapperBase;public class UserMapper extends MapperBase {Record word;Record one;Counter gCnt;@Overridepublic void setup(TaskContext context) throws IOException {word = context.createMapOutputKeyRecord();one = context.createMapOutputValueRecord();one.set(new Object[] { 1L });gCnt = context.getCounter("MyCounters", "global_counts");}@Overridepublic void map(long recordNum, Record record, TaskContext context)throws IOException {for (int i = 0; i < record.getColumnCount(); i++) {String[] words = record.get(i).toString().split("\s+");for (String w : words) {word.set(new Object[] { w });Counter cnt = context.getCounter("MyCounters", "map_outputs");cnt.increment(1);gCnt.increment(1);context.write(word, one);}}}@Overridepublic void cleanup(TaskContext context) throws IOException {}}
同理,右键选择src目录,选择新建(New)->Reduce:
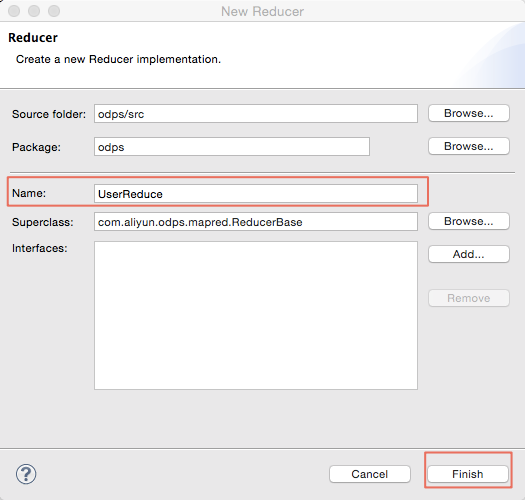
输入Reduce类的名字(本示例使用UserReduce):
同样在包资源管理器(Package Explorer)中,src目录下生成文件UserReduce.java。该文件的内容即是一个Reduce类的模板。编辑模板:
package odps;import java.io.IOException;import java.util.Iterator;import com.aliyun.odps.counter.Counter;import com.aliyun.odps.data.Record;import com.aliyun.odps.mapred.ReducerBase;public class UserReduce extends ReducerBase {private Record result;Counter gCnt;@Overridepublic void setup(TaskContext context) throws IOException {result = context.createOutputRecord();gCnt = context.getCounter("MyCounters", "global_counts");}@Overridepublic void reduce(Record key, Iterator<Record> values, TaskContext context)throws IOException {long count = 0;while (values.hasNext()) {Record val = values.next();count += (Long) val.get(0);}result.set(0, key.get(0));result.set(1, count);Counter cnt = context.getCounter("MyCounters", "reduce_outputs");cnt.increment(1);gCnt.increment(1);context.write(result);}@Overridepublic void cleanup(TaskContext context) throws IOException {}}
创建main函数: 右键选择src目录,选择新建(New) -> MapReduce Driver。填写Driver Name(示例中是UserDriver),Mapper及Recduce类(示例中是UserMapper及UserReduce),并确认。同样会在src目录下看到MyDriver.java文件:

编辑driver内容:
package odps;import com.aliyun.odps.OdpsException;import com.aliyun.odps.data.TableInfo;import com.aliyun.odps.examples.mr.WordCount.SumCombiner;import com.aliyun.odps.examples.mr.WordCount.SumReducer;import com.aliyun.odps.examples.mr.WordCount.TokenizerMapper;import com.aliyun.odps.mapred.JobClient;import com.aliyun.odps.mapred.RunningJob;import com.aliyun.odps.mapred.conf.JobConf;import com.aliyun.odps.mapred.utils.InputUtils;import com.aliyun.odps.mapred.utils.OutputUtils;import com.aliyun.odps.mapred.utils.SchemaUtils;public class UserDriver {public static void main(String[] args) throws OdpsException {JobConf job = new JobConf();job.setMapperClass(TokenizerMapper.class);job.setCombinerClass(SumCombiner.class);job.setReducerClass(SumReducer.class);job.setMapOutputKeySchema(SchemaUtils.fromString("word:string"));job.setMapOutputValueSchema(SchemaUtils.fromString("count:bigint"));InputUtils.addTable(TableInfo.builder().tableName("wc_in1").cols(new String[] { "col2", "col3" }).build(), job);InputUtils.addTable(TableInfo.builder().tableName("wc_in2").partSpec("p1=2/p2=1").build(), job);OutputUtils.addTable(TableInfo.builder().tableName("wc_out").build(), job);RunningJob rj = JobClient.runJob(job);rj.waitForCompletion();}}
运行MapReduce程序,选中UserDriver.java,右键选择Run As -> ODPS MapReduce,点击确认。出现如下对话框:

选择ODPS Project为:example_project,点击Finish按钮开始本地运行MapReduce程序:
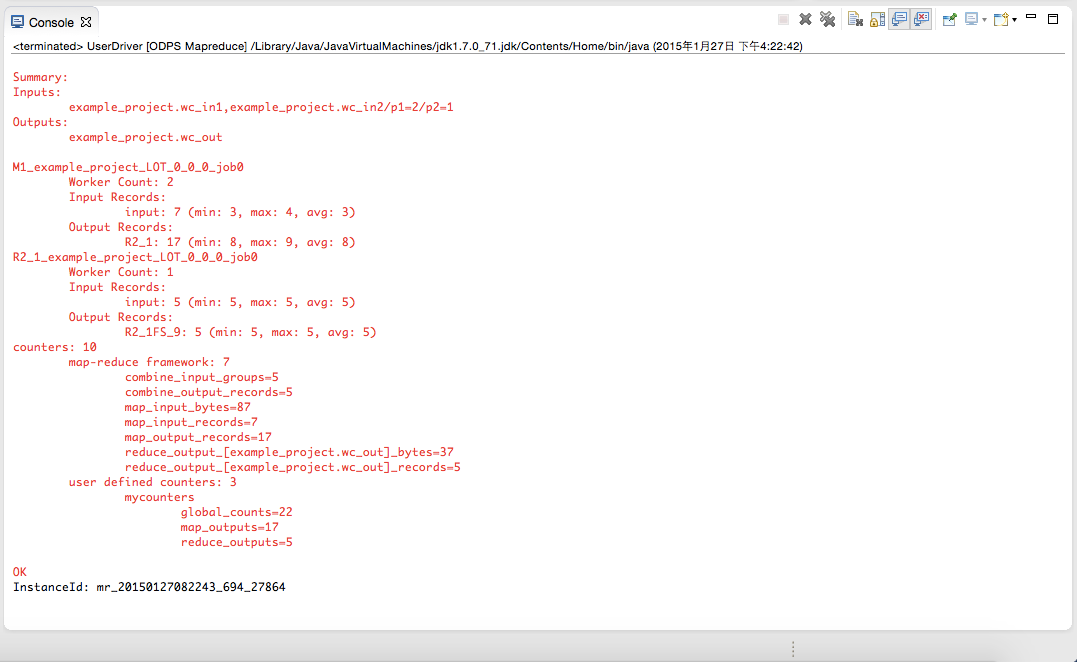
有如上输出信息,说明本地运行成功。运行的输出结果在warehouse目录下。关于warehouse的说明请参考 本地运行 。刷新ODPS工程:
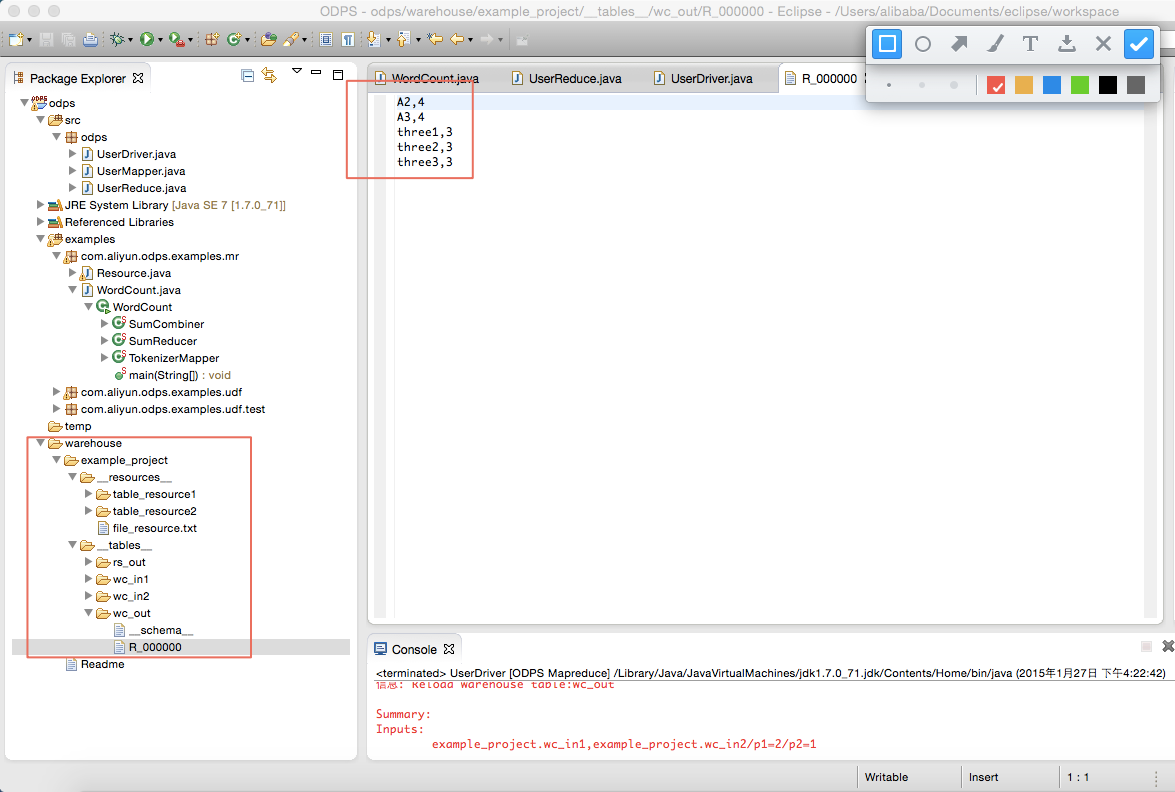
wc_out即是输出目录,R_000000即是结果文件。通过本地调试,确定输出结果正确后,可以通过Eclipse导出(Export)功能将MapReduce打包。打包后将jar包上传到ODPS中。在分布式环境下执行MapReduce,详情请参考 快速入门 。
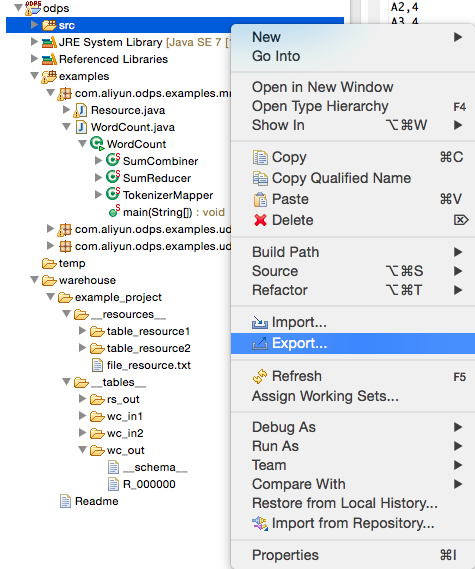
本地调试通过后,用户可以通过Eclipse的Export功能将代码打成jar包,供后续分布式环境使用。在本示例中,我们将程序包命名为mr-examples.jar。选择src目录,点击Export:
选择导出模式为Jar File:
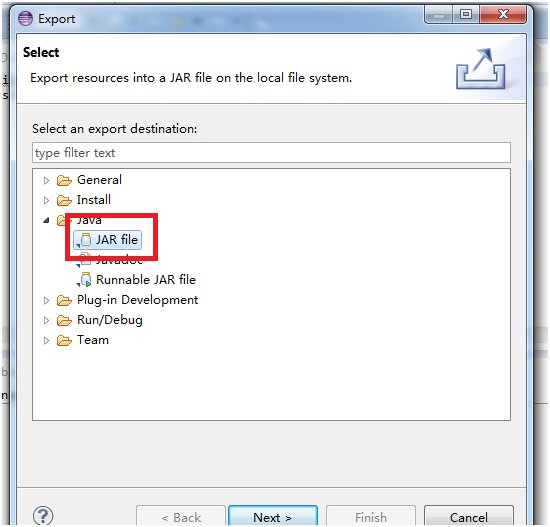
仅需要导出src目录下package(com.aliyun.odps.mapred.open.example),Jar File名称指定为”mr-examples.jar”:

确认后,导出成功。
如果用户想在本地模拟新建Project,可以在warehouse下面,创建一个新的子目录(与example_project平级的目录),目录层次结构为:
<warehouse>|____example_project(项目空间目录)|____ <__tables__>| |__table_name1(非分区表)| | |____ data(文件)| | || | |____ <__schema__> (文件)| || |__table_name2(分区表)| |____ partition_name=partition_value(分区目录)| | |____ data(文件)| || |____ <__schema__> (文件)||____ <__resources__>||___table_resource_name (表资源)| |____<__ref__>||___ file_resource_name(文件资源)
schema文件示例:
非分区表:project=project_nametable=table_namecolumns=col1:BIGINT,col2:DOUBLE,col3:BOOLEAN,col4:DATETIME,col5:STRING分区表:project=project_nametable=table_namecolumns=col1:BIGINT,col2:DOUBLE,col3:BOOLEAN,col4:DATETIME,col5:STRINGpartitions=col1:BIGINT,col2:DOUBLE,col3:BOOLEAN,col4:DATETIME,col5:STRING注:当前支持5种数据格式:bigint,double,boolean,datetime,string, 对应到java中的数据类型-long,double,boolean,java.util.Date,java.lang.String。
data文件示例:
1,1.1,true,2015-06-04 11:22:42 896,hello worldN,N,N,N,N注:时间格式精确到毫秒级别,所有类型用N表示null。
注解:
- 本地模式运行MapReduce程序,默认情况下先到warehouse下查找相应的数据表或资源,如果表或资源不存在会到服务器上下载相应的数据存入warehouse目录下,再以本地模式运行。
- 运行完MapReduce后,请刷新warehouse目录,才能看到生成的结果
最后更新:2016-11-23 17:16:04
上一篇: 创建ODPS工程__Eclipse开发插件_工具_大数据计算服务-阿里云
创建ODPS工程__Eclipse开发插件_工具_大数据计算服务-阿里云
下一篇: UDF开发插件介绍__Eclipse开发插件_工具_大数据计算服务-阿里云
- 更新水印模版__水印模板接口_API使用手册_媒体转码-阿里云
- 企业邮箱 在Foxmail 7.0上POP3/IMAP协议设置方法__客户端使用_邮箱常见问题_企业邮箱-阿里云
- DescribeHealthStatus__BackendServer相关API_API 参考_负载均衡-阿里云
- 相关限制__标签管理_用户指南_负载均衡-阿里云
- E-MapReduce监控__云服务监控_用户指南_云监控-阿里云
- 阿里云与芯讯通SIMCom——互联网生态与垂直行业的深度融合
- 专属账号申请流程?__充值介绍_账户资产_财务-阿里云
- 地域___产品简介_云服务器 ECS-阿里云
- Dashboard概览__Dashboard_用户指南_云监控-阿里云
- rolling_updates__服务编排文档_用户指南_容器服务-阿里云
相关内容
- 常见错误说明__附录_大数据计算服务-阿里云
- 发送短信接口__API使用手册_短信服务-阿里云
- 接口文档__Android_安全组件教程_移动安全-阿里云
- 运营商错误码(联通)__常见问题_短信服务-阿里云
- 设置短信模板__使用手册_短信服务-阿里云
- OSS 权限问题及排查__常见错误及排除_最佳实践_对象存储 OSS-阿里云
- 消息通知__操作指南_批量计算-阿里云
- 设备端快速接入(MQTT)__快速开始_阿里云物联网套件-阿里云
- 查询API调用流量数据__API管理相关接口_API_API 网关-阿里云
- 使用STS访问__JavaScript-SDK_SDK 参考_对象存储 OSS-阿里云