![]() 534
534
![]()
![]() 火車采集器
火車采集器
火車頭數據采集平台1.6增加的Http正文提取,Ocr識別和中文分詞功能
火車頭數據采集平台1.6增加的Http正文提取,Ocr識別和中文分詞功能
作者:小文 發布於:2012-9-14 17:31 Friday 分類:開發計劃
9.12號發布的新版采集器平台增加了Http正文提取和Ocr識別功能,使用企業版本的用戶都可以使用。用戶可以通過調用http,完成正文識別或是ocr等功能,使用戶的平台和采集器整合更加方便。以下是具體的使用方法,注意,請先啟動http服務器。
1、正文提取功能
a.用戶需要輸入要提取的網址或是內容。如果是單純的網址識別,注意要訪問的網頁不需要登錄。
示例網址:https://127.0.0.1:800/api?model=text&pageurl=https://news.qq.com/a/20120914/001770.htm
b.如果是要提取某個網頁的內容。請填寫完整的html源碼和pageurl.注意請求時對發送的內容進行utf8格式的urlencode.如果隻填寫了pageurl而沒有html,則服務器會去訪問pageurl請求html代碼。
示例: https://127.0.0.1:800/api?model=text&html=編碼後的完整的html代碼&pageurl=https://news.qq.com/a/20120914/001770.htm
c.提取方式分為標準模式,完全模式,純淨模式,需要加一個returntype參數,其值為raw(標準模式),pure(純淨模式).默認為標準模式。
d.結構形式默認為普通文章,如果需要多層評論形式,請添加pagetype=bbs
最後返回的結果是xml格式的,如下
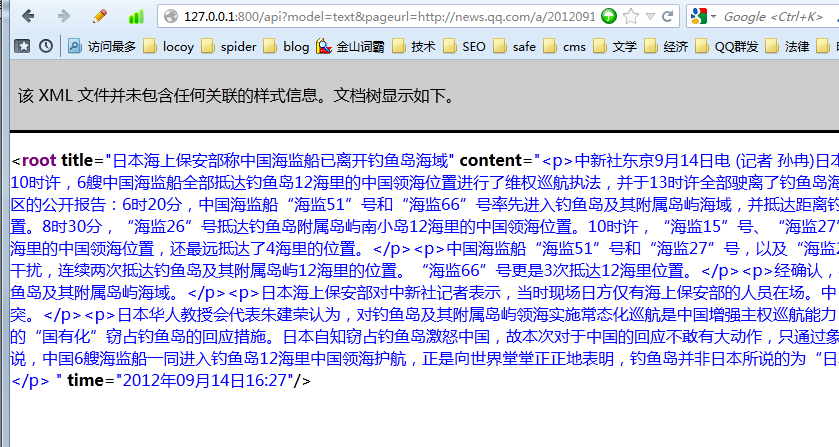
2.ocr識別
ocr識別支持直接傳入圖片地址和base64編碼的圖片。用戶需要指定一個ocr配置文件名。ocr配置文件要保存在Configuration/ocr/目錄下。請求的格式如下
a.直接的圖片地址
https://127.0.0.1:888/api?model=ocr&ocrfile=baixing&imgurl=http%3A%2F%2Fstatic.baixing.net%2Fpages%2Fmobile%2FXTJ7aQPIUYmLpzNNsitnwA%253D%253D%2F2.jpg
返回的結果如下:

3.中文分詞
中文分詞支持一個或多個正文文本的識別,默認的是分詞5個,分隔符,號。如果要修改,請傳入參數splitnum和splitsep。識別文本的字段名要以wordsegtxt開頭,整個字段名隻能包含數字或字母。程序處理完後,會返回xml格式數據,以原字段名命令標簽名。
https://127.0.0.1:888/api?model=wordseg&wordsegtxt1=%E7%81%AB%E8%BD%A6%E9%87%87%E9%9B%86%E5%99%A8(%E8%BD%AF%E8%91%97%E7%99%BB%E5%AD%970144474%E5%8F%B7%EF%BC%8C2009SR017475)%E6%98%AF%E4%B8%80%E6%AC%BE%E4%B8%93%E4%B8%9A%E7%9A%84%E7%BD%91%E7%BB%9C%E6%95%B0%E6%8D%AE%E9%87%87%E9%9B%86%2F%E4%BF%A1%E6%81%AF%E6%8C%96%E6%8E%98%E5%A4%84%E7%90%86%E8%BD%AF%E4%BB%B6%EF%BC%8C%E9%80%9A%E8%BF%87%E7%81%B5%E6%B4%BB%E7%9A%84%E9%85%8D%E7%BD%AE%EF%BC%8C%E5%8F%AF%E4%BB%A5%E5%BE%88%E8%BD%BB%E6%9D%BE%E8%BF%85%E9%80%9F%E5%9C%B0%E4%BB%8E%E7%BD%91%E9%A1%B5%E4%B8%8A%E6%8A%93%E5%8F%96%E7%BB%93%E6%9E%84%E5%8C%96%E7%9A%84%E6%96%87%E6%9C%AC%E3%80%81%E5%9B%BE%E7%89%87%E3%80%81%E6%96%87%E4%BB%B6%E7%AD%89%E8%B5%84%E6%BA%90%E4%BF%A1%E6%81%AF%EF%BC%8C%E5%8F%AF%E7%BC%96%E8%BE%91%E7%AD%9B%E9%80%89%E5%A4%84%E7%90%86%E5%90%8E%E9%80%89%E6%8B%A9%E5%8F%91%E5%B8%83%E5%88%B0%E7%BD%91%E7%AB%99%E5%90%8E%E5%8F%B0%EF%BC%8C%E5%90%84%E7%B1%BB%E6%96%87%E4%BB%B6%E6%88%96%E5%85%B6%E4%BB%96%E6%95%B0%E6%8D%AE%E5%BA%93%E7%B3%BB%E7%BB%9F%E4%B8%AD%E3%80%82%E8%A2%AB%E5%B9%BF%E6%B3%9B%E5%BA%94%E7%94%A8%E4%BA%8E%E6%95%B0%E6%8D%AE%E9%87%87%E9%9B%86%E6%8C%96%E6%8E%98%E3%80%81%E5%9E%82%E7%9B%B4%E6%90%9C%E7%B4%A2%E3%80%81%E4%BF%A1%E6%81%AF%E6%B1%87%E8%81%9A%E5%92%8C%E9%97%A8%E6%88%B7%E3%80%81%E4%BC%81%E4%B8%9A%E7%BD%91%E4%BF%A1%E6%81%AF%E6%B1%87%E8%81%9A%E3%80%81%E5%95%86%E4%B8%9A%E6%83%85%E6%8A%A5%E3%80%81%E8%AE%BA%E5%9D%9B%E6%88%96%E5%8D%9A%E5%AE%A2%E8%BF%81%E7%A7%BB%E3%80%81%E6%99%BA%E8%83%BD%E4%BF%A1%E6%81%AF%E4%BB%A3%E7%90%86%E3%80%81%E4%B8%AA%E4%BA%BA%E4%BF%A1%E6%81%AF%E6%A3%80%E7%B4%A2%E7%AD%89%E9%A2%86%E5%9F%9F%EF%BC%8C%E9%80%82%E7%94%A8%E4%BA%8E%E5%90%84%E7%B1%BB%E5%AF%B9%E6%95%B0%E6%8D%AE%E6%9C%89%E9%87%87%E9%9B%86%E6%8C%96%E6%8E%98%E9%9C%80%E6%B1%82%E7%9A%84%E7%BE%A4%E4%BD%93&wordsegtxt2=%E9%92%93%E9%B1%BC%E5%B2%9B%E6%98%AF%E5%8F%B0%E6%B9%BE%E7%9C%81%E4%B8%8D%E5%8F%AF%E5%88%86%E5%89%B2%E7%9A%84%E4%B8%80%E9%83%A8%E5%88%86

標簽: ocr
最後更新:2017-05-09 01:05:59