![]() 333
333
![]()
![]() 手機大全
手機大全
spark-submit 參數設置說明__Spark_開發人員指南_E-MapReduce-阿裏雲
本章節將介紹如何在 E-MapReduce 場景下設置 spark-submit 的參數。
集群配置
軟件配置
E-MapReduce 產品版本 1.1.0
Hadoop 2.6.0
Spark 1.6.0
硬件配置
Master 節點
8 核 16G 500G 高效雲盤
1 台
Worker 節點 x 10 台
8 核 16G 500G 高效雲盤
10 台
總資源:8 核 16G(Worker)x 10 + 8 核 16G(Master)
注意:由於作業提交的時候資源隻計算 CPU 和內存,所以這裏磁盤的大小並未計算到總資源中。
Yarn 可分配總資源:12 核 12.8G(worker)x 10
注意:默認情況下,yarn 可分配核 = 機器核 x 1.5,yarn 可分配內存 = 機器內存 x 0.8。
提交作業
創建集群後,您可以提交作業。首先,您需要在 E-MapReduce 中創建一個作業,配置如下:
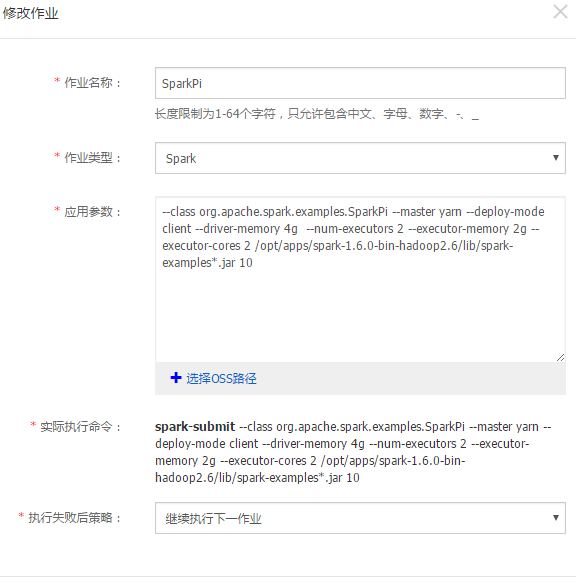
上圖所示的作業,直接使用了 Spark 官方的 example 包,所以不需要自己上傳 jar 包。
參數列表如下所示:
--class org.apache.spark.examples.SparkPi --master yarn --deploy-mode client --driver-memory 4g –num-executors 2 --executor-memory 2g --executor-cores 2 /opt/apps/spark-1.6.0-bin-hadoop2.6/lib/spark-examples*.jar 10
參數說明如下所示:
| 參數 | 參考值 | 說明 |
|---|---|---|
| class | org.apache.spark.examples.SparkPi | 作業的主類。 |
| master | yarn | 因為 E-MapReduce 使用 Yarn 的模式,所以這裏隻能是 yarn 模式。 |
| yarn-client | 等同於 –-master yarn —deploy-mode client, 此時不需要指定deploy-mode。 | |
| yarn-cluster | 等同於 –-master yarn —deploy-mode cluster, 此時不需要指定deploy-mode。 | |
| deploy-mode | client | client 模式表示作業的 AM 會放在 Master 節點上運行。要注意的是,如果設置這個參數,那麼需要同時指定上麵 master 為 yarn。 |
| cluster | cluster 模式表示 AM 會隨機的在 worker 節點中的任意一台上啟動運行。要注意的是,如果設置這個參數,那麼需要同時指定上麵 master 為yarn。 | |
| driver-memory | 4g | driver 使用的內存,不可超過單機的 core 總數。 |
| num-executors | 2 | 創建多少個 executor。 |
| executor-memory | 2g | 各個 executor 使用的最大內存,不可超過單機的最大可使用內存。 |
| executor-cores | 2 | 各個 executor 使用的並發線程數目,也即每個 executor 最大可並發執行的 Task 數目。 |
資源計算
在不同模式、不同的設置下運行時,作業使用的資源情況如下表所示:
yarn-client 模式的資源計算
| 節點 | 資源類型 | 資源量(結果使用上麵的例子計算得到) |
|---|---|---|
| master | core | 1 |
| mem | driver-memroy = 4G | |
| worker | core | num-executors * executor-cores = 4 |
| mem | num-executors * executor-memory = 4G |
作業主程序(Driver 程序)會在 master 節點上執行。按照作業配置將分配 4G(由 —driver-memroy 指定)的內存給它(當然實際上可能沒有用到)。
會在 worker 節點上起 2 個(由 —num-executors 指定)executor,每一個 executor 最大能分配 2G(由 —executor-memory 指定)的內存,並最大支持 2 個(由- -executor-cores 指定)task 的並發執行。
yarn-cluster 模式的資源計算
| 節點 | 資源類型 | 資源量(結果使用上麵的例子計算得到) |
|---|---|---|
| master | 一個很小的 client 程序,負責同步 job 信息,占用很小。 | |
| worker | core | num-executors * executor-cores+spark.driver.cores = 5 |
| mem | num-executors * executor-memory + driver-memroy = 8g |
注意:這裏的 spark.driver.cores 默認是 1,也可以設置為更多。
資源使用的優化
yarn-client 模式
若您有了一個大作業,使用 yarn-client 模式,想要多用一些這個集群的資源,請參見如下配置:
注意:
- Spark 在分配內存時,會在用戶設定的內存值上溢出 375M 或 7%(取大值)。
- Yarn 分配 container 內存時,遵循向上取整的原則,這裏也就是需要滿足 1G 的整數倍。
--master yarn-client --driver-memory 5g –-num-executors 20 --executor-memory 4g --executor-cores 4
按照上述的資源計算公式,
master 的資源量為:
- core:1
- mem:6G (5G + 375M 向上取整為 6G)
workers 的資源量為:
- core: 20*4 = 80
- mem: 20*5G (4G + 375M 向上取整為 5G) = 100G
可以看到總的資源沒有超過集群的總資源,那麼遵循這個原則,您還可以有很多種配置,例如:
--master yarn-client --driver-memory 5g –num-executors 40 --executor-memory 1g --executor-cores 2
--master yarn-client --driver-memory 5g –num-executors 15 --executor-memory 4g --executor-cores 4
--master yarn-client --driver-memory 5g –num-executors 10 --executor-memory 9g --executor-cores 6
原則上,按照上述的公式計算出來的需要資源不超過集群的最大資源量就可以。但在實際場景中,因為係統,hdfs 以及 E-MapReduce 的服務會需要使用 core 和 mem 資源,如果把 core 和 mem 都占用完了,反而會導致性能的下降,甚至無法運行。
executor-cores 數一般也都會被設置成和集群的可使用核一致,因為如果設置的太多,CPU 會頻繁切換,性能並不會提高。
yarn-cluster 模式
當使用 yarn-cluster 模式後,Driver 程序會被放到 worker 節點上。資源會占用到 worker 的資源池子裏麵,這時若想要多用一些這個集群的資源,請參加如下配置:
--master yarn-cluster --driver-memory 5g –num-executors 15 --executor-memory 4g --executor-cores 4
配置建議
如果將內存設置的很大,要注意 gc 所產生的消耗。一般我們會推薦一個 executor 的內存 <= 64G。
如果是進行 HDFS 讀寫的作業,建議是每個 executor 中使用 <= 5個並發來讀寫。
如果是進行 OSS 讀寫的作業,我們建議是將 executor 分布在不同的 ECS 上,這樣可以將每一個 ECS 的帶寬都用上。比如有 10 台 ECS,那麼就可以配置 num-executors=10,並設置合理的內存和並發。
如果作業中使用了非線程安全的代碼,那麼在設置 executor-cores 的時候需要注意多並發是否會造成作業的不正常。如果會,那麼推薦就設置 executor-cores=1。
最後更新:2016-11-23 16:03:59
上一篇: Spark + HBase__Spark_開發人員指南_E-MapReduce-阿裏雲
Spark + HBase__Spark_開發人員指南_E-MapReduce-阿裏雲
下一篇: SDK-Release__Spark_開發人員指南_E-MapReduce-阿裏雲
- 查詢監控行為__監控管理_API 參考_雲數據庫 RDS 版-阿裏雲
- iOS SDK手冊__SDK手冊_HTTPDNS-阿裏雲
- 快速指引__DataHub實時數據通道_大數據計算服務-阿裏雲
- 阿裏雲也支持“秒”級計費了
- 編碼格式設置__腳本開發_Lite用戶使用手冊_性能測試-阿裏雲
- 跨域資源共享__Java-SDK_SDK 參考_對象存儲 OSS-阿裏雲
- 查詢表信息__管理表_數據庫開發_用戶指南(RDBMS)_數據管理-阿裏雲
- 列舉所有__SDK接口說明_Python版SDK_批量計算-阿裏雲
- E-MapReduce SDK 發布說明__開發人員指南_E-MapReduce-阿裏雲
- 步驟三:本地驗證__快速上線_Web 應用防火牆-阿裏雲
相關內容
- 常見錯誤說明__附錄_大數據計算服務-阿裏雲
- 發送短信接口__API使用手冊_短信服務-阿裏雲
- 接口文檔__Android_安全組件教程_移動安全-阿裏雲
- 運營商錯誤碼(聯通)__常見問題_短信服務-阿裏雲
- 設置短信模板__使用手冊_短信服務-阿裏雲
- OSS 權限問題及排查__常見錯誤及排除_最佳實踐_對象存儲 OSS-阿裏雲
- 消息通知__操作指南_批量計算-阿裏雲
- 設備端快速接入(MQTT)__快速開始_阿裏雲物聯網套件-阿裏雲
- 查詢API調用流量數據__API管理相關接口_API_API 網關-阿裏雲
- 使用STS訪問__JavaScript-SDK_SDK 參考_對象存儲 OSS-阿裏雲