![]() 899
899
![]()
![]() 群英
群英
数据导入(CDP)__快速入门_云数据库 PetaData-阿里云
用户可以通过数据集成(Data Integration,原产品名CDP)(https://www.aliyun.com/product/cdp)向PetaData中进行数据的全量导入或带过滤条件的导入。
准备工作
- PetaData中待迁入数据的目标数据库和表,都需要在进行数据导入之前,通过PetaData的管理控制台先创建好。
- 当待迁出数据的源数据库为阿里云RDS时,请通过RDS的管理控制台进行IP白名单设置,详见数据集成文档《如何添加RDS IP白名单》。
创建Pipeline
打开CDP的管理控制台,选择“创建普通Pileline”
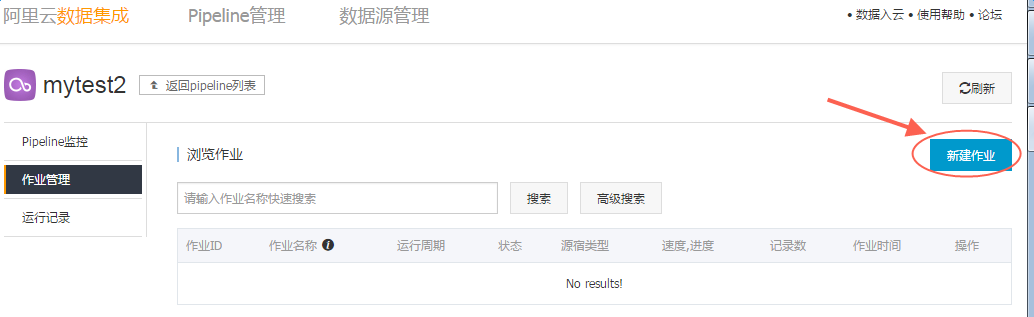
在新创建的Pipeline列表中点击“管理”—“作业管理”—“新建作业”:
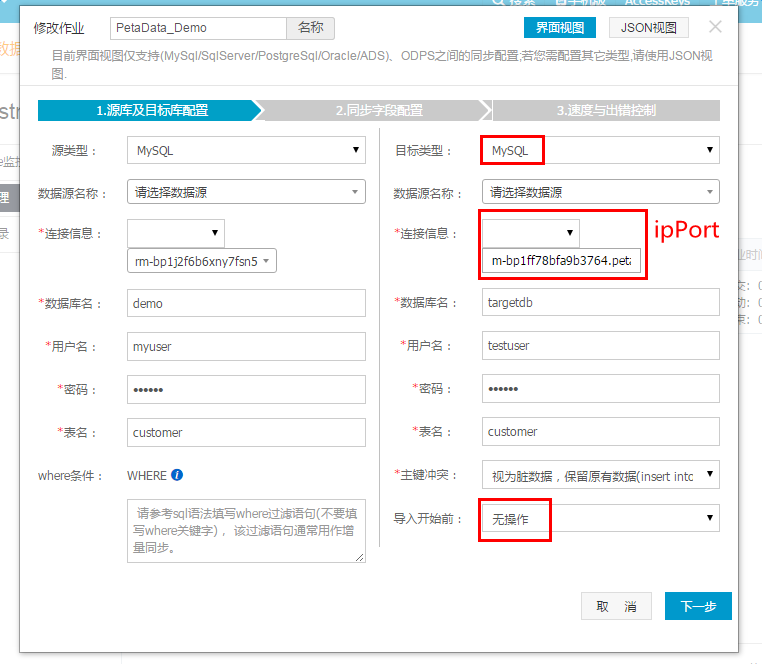
在创建作业的第一步,配置源库及目标库(如下图)。几点说明:
源库可以是RDS实例,也可以是自建MySQL库,或者ODPS。本例中选择从RDS实例中导入数据;源库中“where条件”可按用户实际需要,若全量导入数据则不用填写,若按条件过滤/增量同步,则填写对应的过滤语句;目标库中“目标类型”选择MySQL(PetaData兼容MySQL协议);目标库中“数据源名称”可不输入;目标库中“连接信息”选择ipPort,之后输入PetaData实例的连接信息(可在PetaData的管理控制台(https://petadata.console.aliyun.com)上获取);目标库中数据库名、用户名、密码、表名按实际情况填写;目标库中“导入开始前”选择“无操作”;
创建作业第二步,同步字段配置,通常可以直接跳过。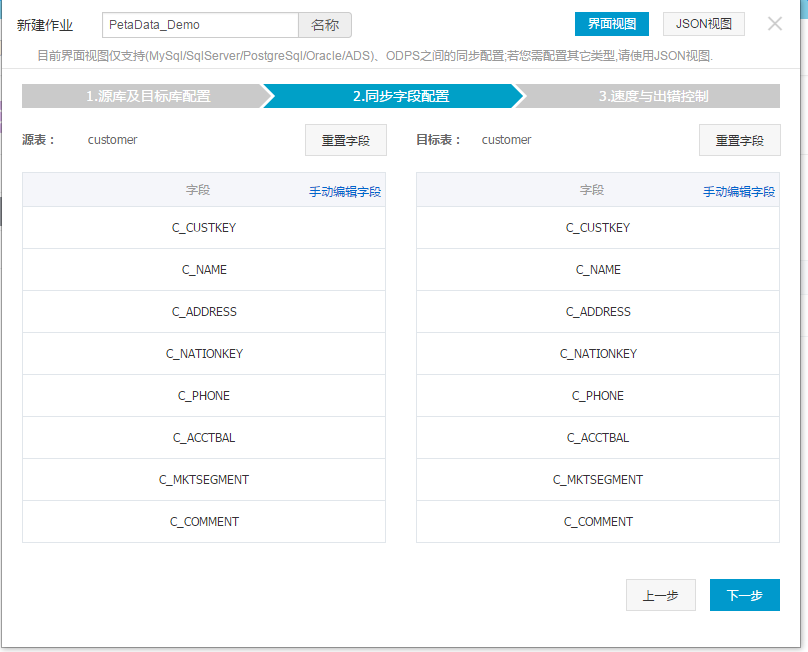
创建作业第三步,通常可以直接跳过。
开始数据导入
点击确定,作业创建成功,此时任务还未运行。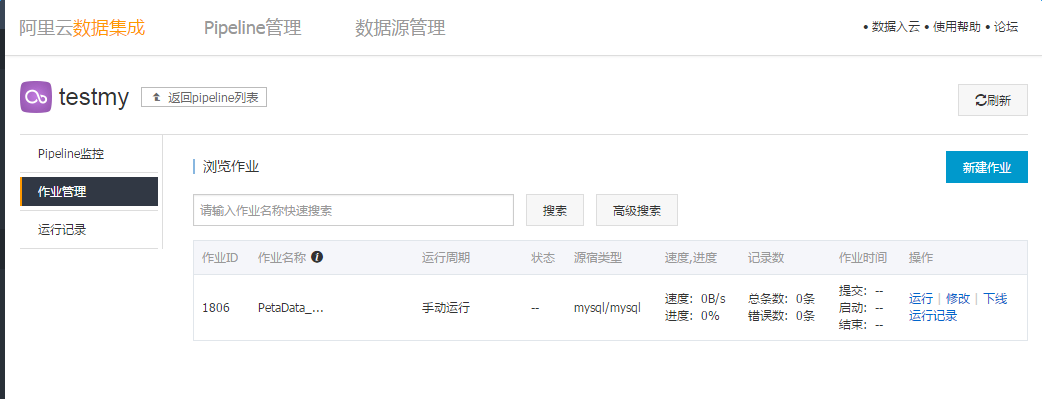
点击运行,开始数据导入,待任务完成后即可。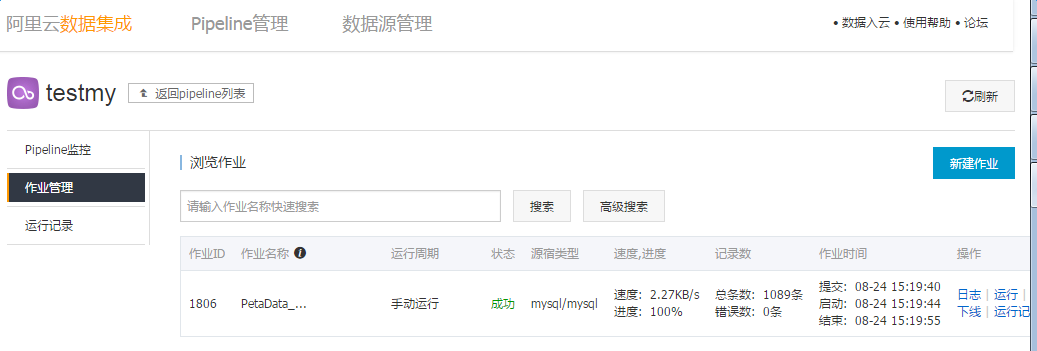
最后更新:2016-11-23 17:16:09
上一篇: 创建数据库与表__快速入门_云数据库 PetaData-阿里云
创建数据库与表__快速入门_云数据库 PetaData-阿里云
下一篇: 数据导入(DTS)__快速入门_云数据库 PetaData-阿里云
- 结束会话__会话管理_性能管理_用户指南(RDBMS)_数据管理-阿里云
- 使用发布线进行持续交付__用户手册_持续交付平台-阿里云
- 授权子账号访问IoT__子账号访问IoT_控制台使用手册_阿里云物联网套件-阿里云
- ReservedThroughput__DataType_API 参考_表格存储-阿里云
- 限制__标签_用户指南_云服务器 ECS-阿里云
- 目标模式__场景制定_使用手册_性能测试-阿里云
- 获取域名 Whois 信息__域名管理接口_API文档_云解析-阿里云
- 获取队列列表__队列使用帮助_控制台使用帮助_消息服务-阿里云
- 删除自定义转码模板__自定义转码模板接口_API使用手册_媒体转码-阿里云
- 免费项目说明__购买指南_消息队列 MQ-阿里云
相关内容
- 常见错误说明__附录_大数据计算服务-阿里云
- 发送短信接口__API使用手册_短信服务-阿里云
- 接口文档__Android_安全组件教程_移动安全-阿里云
- 运营商错误码(联通)__常见问题_短信服务-阿里云
- 设置短信模板__使用手册_短信服务-阿里云
- OSS 权限问题及排查__常见错误及排除_最佳实践_对象存储 OSS-阿里云
- 消息通知__操作指南_批量计算-阿里云
- 设备端快速接入(MQTT)__快速开始_阿里云物联网套件-阿里云
- 查询API调用流量数据__API管理相关接口_API_API 网关-阿里云
- 使用STS访问__JavaScript-SDK_SDK 参考_对象存储 OSS-阿里云