![]() 341
341
![]()
![]() 人物
人物
運行SQL__快速開始_大數據計算服務-阿裏雲
大多數用戶對SQL的語法並不陌生,簡單地說,MaxCompute SQL就是用於查詢和分析MaxCompute中的大規模數據。目前SQL的主要功能可以概括如下:
- 支持各類運算符
- 通過DDL語句對表、分區以及視圖進行管理。
- 通過Select語句查詢表中的記錄,通過Where字句過濾表中的記錄。
- 通過Insert語句插入數據、更新數據。
- 通過等值連接Join操作,支持兩張表的關聯。支持多張小表的mapjoin。
- 支持通過內置函數和自定義函數來進行計算。
- 支持正則表達式。
這裏我們隻簡要介紹MaxCompute SQL使用中需要注意的問題。不再做操作示例。
注意:
- 需要注意的是,MaxCompute SQL不支持事務、索引及Update/Delete等操作,同時MaxCompute的SQL語法與Oracle,MySQL有一定差別,用戶無法將其他數據庫中得SQL語句無縫遷移到 MaxCompute 上來。此外,在使用方式上,MaxCompute 無法滿足實時查詢,查詢計算時間在分鍾級別,無法在秒、乃至毫秒級別返回用戶結果。
- 關於SQL的操作詳細示例,請參考SQL。
DDL語句
簡單的DDL操作包括創建表,添加分區,查看表和分區信息,修改表,刪除表和分區。關於這部分的介紹,請參考創建刪除表。
Select 語句
- group by 語句的key可以是輸入表的列名,也可以是由輸入表的列構成的表達式,不可以是select語句的輸出列。
select substr(col2, 2) from tbl group by substr(col2, 2); -- 可以,group by的key可以是輸入表的列構成的表達式;select col2 from tbl group by substr(col2, 2); -- 不可以,group by的key不在select語句的列中;select substr(col2, 2) as c from tbl group by c; -- 不可以,group by的key 不可以是列的別名,即select語句的輸出列;
有這樣的限製是因為,在通常的SQL解析中,group by的操作是先於select操作的,因此group by隻能接受輸入表的列或表達式為key。
- order by必須與limit 聯用;
- sort by前必須加distribute by;
- order by/sort by/distribute by的key必須是select語句的輸出列,即列的別名:
select col2 as c from tbl order by col2 limit 100 -- 不可以,order by的key不是select語句的輸出列,即列的別名select col2 from tbl order by col2 limit 100; -- 可以,當select語句的輸出列沒有別名時,使用列名作為別名。
有這樣的限製是因為,在通常的SQL解析中, order by/sort by/distribute by是後於select操作的,因此它們隻能接受select語句的輸出列為key。
Insert語句
- 向某個分區插入數據時,分區列不可以出現在select列表中:
insert overwrite table sale_detail_insert partition (sale_date='2013', region='china')select shop_name, customer_id, total_price, sale_date, region from sale_detail;-- 報錯返回,sale_date, region為分區列,不可以出現在靜態分區的 insert 語句中。
- 動態分區插入時,動態分區列必須在select列表中:
insert overwrite table sale_detail_dypart partition (sale_date='2013', region)select shop_name,customer_id,total_price from sale_detail;--失敗返回,動態分區插入時,動態分區列必須在select列表中
Join操作
- MaxCompute SQL支持的Join操作類型包括:{LEFT OUTER|RIGHT OUTER|FULL OUTER|INNER} JOIN;
- 目前最多支持16個並發Join操作;
- 在mapjoin中,最多支持6張小表的mapjoin;
Union All
Union All可以把多個select操作返回的結果,聯合成一個數據集。它會返回所有的結果,但是不會執行去重。 MaxCompute 不支持直接對頂級的兩個查詢結果進行union操作,需要寫成子查詢的形式。
另外需要注意的是,union all連接的兩個select查詢語句,兩個select的列個數、列名稱、列類型必須嚴格一致。如果原名稱不一致,可以通過別名設置成相同的名稱。
其他
- ODPS SQL目前最多支持128個並發union操作;
- 最多支持128個並發insert overwrite/into操作;
SQL優化實例
Join語句中where條件的位置
當兩個表進行join操作的時候,主表的Where限製可以寫在最後,但從表分區限製條件不要寫在Where條件裏,建議寫在ON條件或者子查詢。主表的分區限製條件可以寫在WHERE條件裏(最好先用子查詢過濾)。
參考下麵幾個sql:
select * from A join (select * from B where dt=20150301)B on B.id=A.id where A.dt=20150301;select * from A join B on B.id=A.id where B.dt=20150301; --不允許select * from (select * from A where dt=20150301)A join (select * from B where dt=20150301)B on B.id=A.id;
第2個語句會先join,後進行分區裁剪,數據量變大,性能下降。在實際使用過程中,應該盡量避免第二種用法。
數據傾斜
產生數據傾斜的根本原因是:有少數Worker處理的數據量遠遠超過其他Worker處理的數據量,從而導致少數Worker的運行時長遠遠超過其他的平均運行時長,進而導致整個任務運行時間超長,造成任務延遲。
Join造成的數據傾斜
造成join數據傾斜的原因是join on 的 key分布不均勻。 假設還是上麵的例子,現在將大表A跟一張小表B進行join操作,運行如下語句:
select * from A join B on A.value= B.value;
此時我們拷貝logview的鏈接並打開webcosole頁麵,雙擊執行join操作的fuxi job可以看見此時在[Long-tails]區域有長尾,表示數據已經傾斜了。如下圖所示:
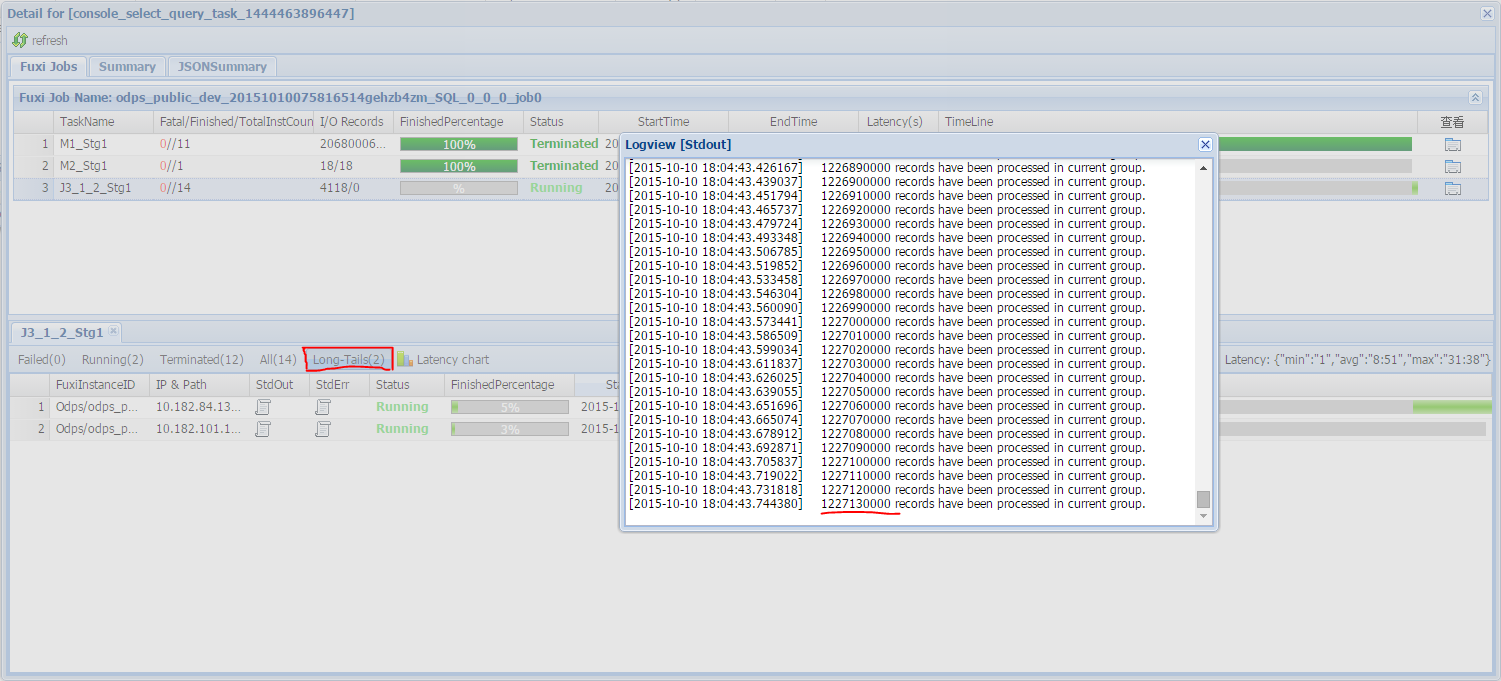
關於如何進行優化,此時我們可以通過如下辦法:
由於表B是個小表並且沒有超過512MB,我們將上麵的語句優化成mapjoin語句再執行,語句如下:
select /*+ MAPJOIN(B) */ * from A join B on A.value= B.value;
或者將傾斜的key用單獨的邏輯來處理,例如經常發生兩邊的key裏有大量null數據導致了傾斜。則需要在join前先過濾掉null的數據或者補上隨機數,然後再進行join。比如:
select * from A join Bon case when A.value is null then concat('value',rand() ) else A.value end = B.value;
在實際場景中,用戶往往知道數據傾斜了,但無法獲取導致數據傾斜的key信息。在此有個通用的方案可以查看數據傾斜的辦法:
例如:select * from a join b on a.key=b.key;產生數據傾斜。用戶可以執行:```sqlselect left.key, left.cnt * right.cnt from(select key, count(*) as cnt from a group by key) leftjoin(select key, count(*) as cnt from b group by key) righton left.key=right.key;
查看key的分布,可以判斷a join b時是否會有數據傾斜。
group by傾斜
造成group by傾斜的原因是group by的key分布不均勻。
假設表A內有兩個字段(key, value),表內的數據量足夠大,並且key的值分布不均,我們運行下麵一條簡單的語句:
select key,count(value) from A group by key;
當表中的數據足夠大的時候,我們一樣會在webcosole頁麵看見長尾。
如何解決這個問題,我們一般在執行SQL前設置防傾斜的參數: set odps.sql.groupby.skewindata=true。
錯誤使用動態分區造成的數據傾斜
動態分區的sql,在odps中會默認增加一個reduce,用來將相同分區的數據合並在一起。這樣做的好處有:
減少 MaxCompute 係統產生的小文件,使後續處理更快;
避免一個Worker輸出文件很多時占用內存過大。
但是也正是因為這個Reduce的引入導致分區數據如果有傾斜的話,會發生長尾。因為相同的數據最多隻會有10個 Worker 處理,所以數據量大,則會發生長尾。
例如:
insert overwrite table A2 partition(dt)selectsplit_part(value,'t',1) as field1,split_part(value,'t',2) as field2,dtfrom Awhere dt='20151010';
這種情況完全沒必要使用動態分區。原來的語句可以改成:
insert overwrite table A2 partition(dt='20151010')selectsplit_part(value,'t',1) as field1,split_part(value,'t',2) as field2from Awhere dt='20151010';
窗口函數的優化
如果我們的SQL中用到了窗口函數,一般情況下每個窗口函數會形成一個Reduce作業,如果窗口函數略多,那麼就會消耗資源。在某些特定場景下,窗口函數是有可優化空間的。首選,窗口函數“over”後麵要完全相同,相同的分組和排序條件;其次,多個窗口函數在同一層SQL執行。符合這兩個條件的窗口函數會合並為一個Reduce執行。(如下這種SQL):
selectrank()over(partition by A order by B desc) as rank,row_number()over(partition by A order by B desc) as row_numfrom MyTable;
子查詢改join
例如有一個子查詢如下:
SELECT * FROM table_a a WHERE a.col1 IN (SELECT col1 FROM table_b b WHERE xxx);
當此語句中table_b這個子查詢返回的col1的個數超過1000個,係統將會報錯如:records returned from subquery exceeded limit of 1000。此時可以使用Join語句來代替,如:
SELECT a.* FROM table_a a JOIN (SELECT DISTINCT col1 FROM table_b b WHERE xxx) c ON (a.col1 = c.col1)
注意:
- 如果沒用DISTINCT,而子查詢c返回的結果裏有相同的col1的值,可能會導致a表的結果數變多。
- 因為DISTINCT子句會導致查詢全落到一個worker裏,如果子查詢數據量比較大的話,可能會導致查詢比較慢。
- 如果已經從業務上控製了子查詢裏的col1不可能會重複,比如查的是主鍵字段,為了提高性能,可以把DISTINCT去掉。
最後更新:2016-09-21 10:34:51
上一篇: 導入導出數據__快速開始_大數據計算服務-阿裏雲
導入導出數據__快速開始_大數據計算服務-阿裏雲
下一篇: 編寫UDF__快速開始_大數據計算服務-阿裏雲
- 數據源概覽__準備數據源_用戶指南_業務實時監控服務 ARMS-阿裏雲
- 監控數據上報__自定義監控_用戶指南_雲監控-阿裏雲
- 查詢操作餘量__刷新預熱接口_API 手冊_CDN-阿裏雲
- EDAS 賬號合並計費說明___服務條款和價格說明_企業級分布式應用服務 EDAS-阿裏雲
- 應用類型__產品使用手冊_開放搜索-阿裏雲
- 檢測解析記錄是否生效__域名找回接口_API文檔_雲解析-阿裏雲
- 修改物理專線屬性__高速通道相關接口_API 參考_雲服務器 ECS-阿裏雲
- 查詢資源列表__資源相關接口_API 文檔_資源編排-阿裏雲
- 編輯標簽__標簽_用戶指南_雲服務器 ECS-阿裏雲
- 常規模式__場景製定_使用手冊_性能測試-阿裏雲
相關內容
- 常見錯誤說明__附錄_大數據計算服務-阿裏雲
- 發送短信接口__API使用手冊_短信服務-阿裏雲
- 接口文檔__Android_安全組件教程_移動安全-阿裏雲
- 運營商錯誤碼(聯通)__常見問題_短信服務-阿裏雲
- 設置短信模板__使用手冊_短信服務-阿裏雲
- OSS 權限問題及排查__常見錯誤及排除_最佳實踐_對象存儲 OSS-阿裏雲
- 消息通知__操作指南_批量計算-阿裏雲
- 設備端快速接入(MQTT)__快速開始_阿裏雲物聯網套件-阿裏雲
- 查詢API調用流量數據__API管理相關接口_API_API 網關-阿裏雲
- 使用STS訪問__JavaScript-SDK_SDK 參考_對象存儲 OSS-阿裏雲