![]() 169
169
![]()
![]() 人物
人物
開源兼容MapReduce__概要_MapReduce_大數據計算服務-阿裏雲
MaxCompute(原ODPS)有一套原生的MapReduce編程模型和接口,簡單說來,這套接口的輸入輸出都是MaxCompute中的Table,處理的數據是以Record為組織形式的,它可以很好地描述Table中的數據處理過程,然而與社區的Hadoop相比,編程接口差異較大。Hadoop用戶如果要將原來的Hadoop MR作業遷移到MaxCompute的MR執行,需要重寫MR的代碼,使用MaxCompute的接口進行編譯和調試,運行正常後再打成一個Jar包才能放到MaxCompute的平台來運行。這個過程十分繁瑣,需要耗費很多的開發和測試人力。如果能夠完全不改或者少量地修改原來的Hadoop MapReduce代碼就能在MaxCompute平台上跑起來,將是一個比較理想的方式。
現在MaxCompute平台提供了一個Hadoop MapReduce到MaxCompute MR的適配工具,已經在一定程度上實現了Hadoop MapReduce作業的二進製級別的兼容,即用戶可以在不改代碼的情況下通過指定一些配置,就能將原來在Hadoop上運行的MapReduce jar包拿過來直接跑在MaxCompute上。用戶可通過這裏下載開發插件。目前該插件處於測試階段,暫時還不能支持用戶自定義comparator和自定義key類型,下麵將以WordCount程序為例,介紹一下這個插件的基本使用方式。
提示:
- 開源版本SDK下載地址,請點擊這裏。
- 更多開源兼容性的整理請參考開源版本SDK兼容性。
- 更多Hadoop MapReduce SDK介紹請參考MapReduce官方文檔
下載HadoopMR的插件
通過這裏下載插件,包名為hadoop2openmr-1.0.jar。
注意,這個jar裏麵已經包含hadoop-2.7.2版本的相關依賴,在作業的jar包中請不要攜帶hadoop的依賴,避免版本衝突。
準備好HadoopMR的程序jar包
編譯導出WordCount的jar包:wordcount_test.jar ,wordcount程序的源碼如下:
package com.aliyun.odps.mapred.example.hadoop;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.Mapper;import org.apache.hadoop.mapreduce.Reducer;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;import java.util.StringTokenizer;public class WordCount {public static class TokenizerMapperextends Mapper<Object, Text, Text, IntWritable>{private final static IntWritable one = new IntWritable(1);private Text word = new Text();public void map(Object key, Text value, Context context) throws IOException, InterruptedException {StringTokenizer itr = new StringTokenizer(value.toString());while (itr.hasMoreTokens()) {word.set(itr.nextToken());context.write(word, one);}}}public static class IntSumReducerextends Reducer<Text,IntWritable,Text,IntWritable> {private IntWritable result = new IntWritable();public void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException {int sum = 0;for (IntWritable val : values) {sum += val.get();}result.set(sum);context.write(key, result);}}public static void main(String[] args) throws Exception {Configuration conf = new Configuration();Job job = Job.getInstance(conf, "word count");job.setJarByClass(WordCount.class);job.setMapperClass(TokenizerMapper.class);job.setCombinerClass(IntSumReducer.class);job.setReducerClass(IntSumReducer.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);FileInputFormat.addInputPath(job, new Path(args[0]));FileOutputFormat.setOutputPath(job, new Path(args[1]));System.exit(job.waitForCompletion(true) ? 0 : 1);}}
測試數據準備
- 創建輸入表和輸出表
create table if not exists wc_in(line string);create table if not exists wc_out(key string, cnt bigint);
- 通過tunnel將數據導入輸入表中
待導入文本文件data.txt的數據內容如下:
hello maxcomputehello mapreduce
例如可以通過MaxCompute客戶端的Tunnel命令將data.txt的數據導入wc_in中,
tunnel upload data.txt wc_in;
準備好表與HDFS文件路徑的映射關係配置
配置文件命名為:wordcount-table-res.conf
{"file:/foo": {"resolver": {"resolver": "com.aliyun.odps.mapred.hadoop2openmr.resolver.TextFileResolver","properties": {"text.resolver.columns.combine.enable": "true","text.resolver.seperator": "t"}},"tableInfos": [{"tblName": "wc_in","partSpec": {},"label": "__default__"}],"matchMode": "exact"},"file:/bar": {"resolver": {"resolver": "com.aliyun.odps.mapred.hadoop2openmr.resolver.BinaryFileResolver","properties": {"binary.resolver.input.key.class" : "org.apache.hadoop.io.Text","binary.resolver.input.value.class" : "org.apache.hadoop.io.LongWritable"}},"tableInfos": [{"tblName": "wc_out","partSpec": {},"label": "__default__"}],"matchMode": "fuzzy"}}
配置項說明:
整個配置是一個json文件,描述HDFS上文件與maxcompute上表之間的映射關係,一般要配置輸入和輸出兩部分,一個HDFS路徑對應一個resolver配置,tableInfos配置以及matchMode配置。
- resolver: 用於配置如何對待文件中的數據,目前有com.aliyun.odps.mapred.hadoop2openmr.resolver.TextFileResolver和com.aliyun.odps.mapred.hadoop2openmr.resolver.BinaryFileResolver兩個內置的resolver可以選用。除了指定好resolver的名字,還需要為相應的resolver配置一些properties指導它正確的進行數據解析。
- TextFileResolver: 對於純文本的數據,輸入輸出都會當成純文本對待。當作為輸入resolver配置時,需要配置的properties有text.resolver.columns.combine.enable和text.resolver.seperator,當text.resolver.columns.combine.enable配置為true時,會把輸入表的所有列按找text.resolver.seperator指定的分隔符組合成一個字符串作為輸入。否則,會把輸入表的前兩列分別作為key,value。
- BinaryFileResolver: 可以處理二進製的數據,自動將數據轉換為maxcompute可以支持的數據類型,如bigint, bool, double等。當作為輸出resolver配置時,需要配置的properties有binary.resolver.input.key.class和binary.resolver.input.value.class,分別代表中間結果的key和value類型。
- tableInfos:用戶配置HDFS對應的maxcompute的表,目前隻支持配置表的名字tblName,而partSpec和label請保持和示例一致。
- matchMode:路徑的匹配模式,可選項為exact和fuzzy,分別代表精確匹配和模煳匹配,如果設置為fuzzy,則可以通過正則來匹配HDFS的輸入路徑。
作業提交
使用MaxCompute命令行工具odpscmd提交作業。MaxCompute命令行工具的安裝和配置方法參考客戶端用戶手冊。在odpscmd下運行如下命令:
jar -DODPS_HADOOPMR_TABLE_RES_CONF=./wordcount-table-res.conf -classpath hadoop2openmr-1.0.jar,wordcount_test.jar com.aliyun.odps.mapred.example.hadoop.WordCount /foo /bar;
這裏假設我們已經將hadoop2openmr-1.0.jar和wordcount_test.jar以及wordcount-table-res.conf已經放置到odpscmd的當前目錄,否則在指定配置和-classpath的路徑時需要做相應的修改。
運行過程如下圖所示:
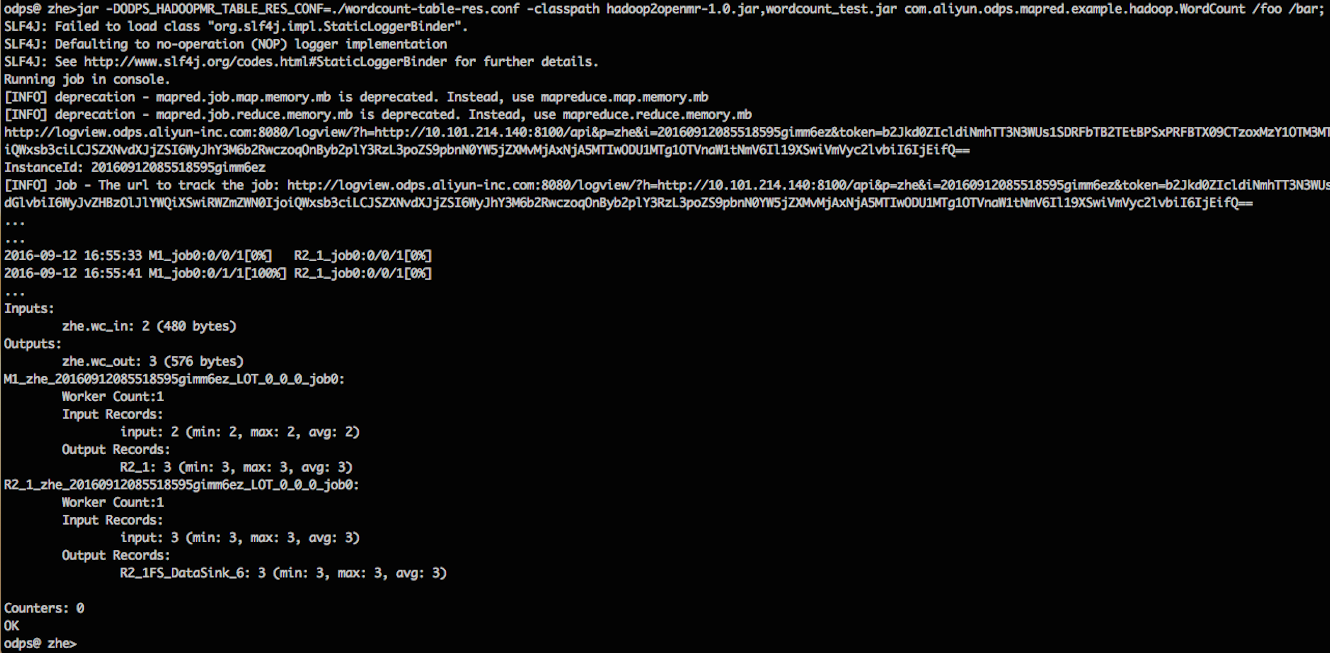
當作業運行完成後,可以查看結果表wc_out裏麵的內容,驗證作業成功結束,結果符合預期。

最後更新:2016-10-18 11:46:39
上一篇: 擴展MapReduce__概要_MapReduce_大數據計算服務-阿裏雲
擴展MapReduce__概要_MapReduce_大數據計算服務-阿裏雲
下一篇: 作業提交__功能介紹_MapReduce_大數據計算服務-阿裏雲
- API 數據源__準備數據源_用戶指南_業務實時監控服務 ARMS-阿裏雲
- 獲取 Region 列表__資源管理類 API_Open API 參考_企業級分布式應用服務 EDAS-阿裏雲
- OpenID Connect認證__使用手冊(開放API)_API 網關-阿裏雲
- 申請物理專線接入__高速通道相關接口_API 參考_雲服務器 ECS-阿裏雲
- 創建類似表__管理表_數據庫開發_用戶指南(RDBMS)_數據管理-阿裏雲
- 大數據體驗館服務協議__相關協議_平台介紹_數加平台介紹-阿裏雲
- 掛載文件係統__快速入門_文件存儲-阿裏雲
- Aggregator機製介紹__圖模型_大數據計算服務-阿裏雲
- RouteTableSetType__數據類型_API 參考_雲服務器 ECS-阿裏雲
- 報表製作-功能概述___製作報表_Quick BI-阿裏雲
相關內容
- 常見錯誤說明__附錄_大數據計算服務-阿裏雲
- 發送短信接口__API使用手冊_短信服務-阿裏雲
- 接口文檔__Android_安全組件教程_移動安全-阿裏雲
- 運營商錯誤碼(聯通)__常見問題_短信服務-阿裏雲
- 設置短信模板__使用手冊_短信服務-阿裏雲
- OSS 權限問題及排查__常見錯誤及排除_最佳實踐_對象存儲 OSS-阿裏雲
- 消息通知__操作指南_批量計算-阿裏雲
- 設備端快速接入(MQTT)__快速開始_阿裏雲物聯網套件-阿裏雲
- 查詢API調用流量數據__API管理相關接口_API_API 網關-阿裏雲
- 使用STS訪問__JavaScript-SDK_SDK 參考_對象存儲 OSS-阿裏雲