![]() 450
450
![]()
![]() 微信
微信
文本分析__使用手冊(new)_機器學習-阿裏雲
文本分析
目錄
詞頻統計
功能介紹
- 在對文章進行分詞的基礎上,按行保序輸出對應文章ID列(docId)對應文章的詞,統計指定文章ID列(docId)對應文章內容(docContent)的詞頻。
參數設置
輸入參數:經過分詞組件生成兩列—文檔ID列和分詞後的文檔內容列
兩個輸出參數:
第一個輸出端:輸出表包含三個字段—id,word,count,如下圖:
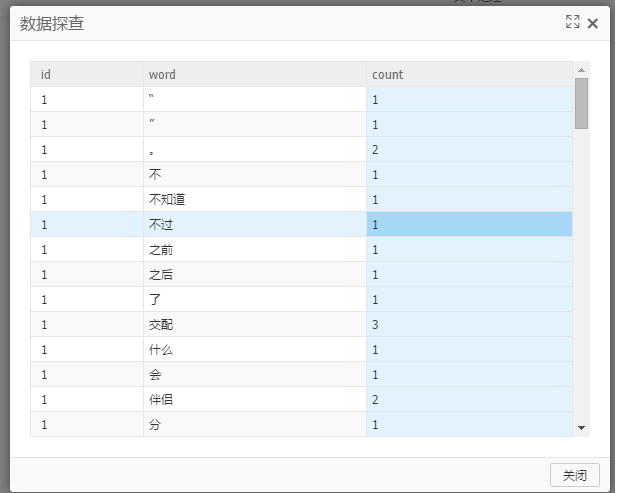
count—統計每個文檔中,對應word詞匯出現的次數
第二個輸出端:輸出包含兩個字段—id,word,如下圖:
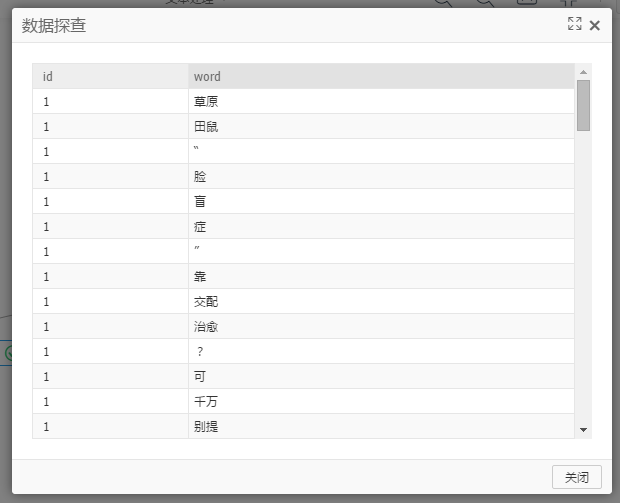
本端口輸出表按詞語在文章中出現的順序依次輸出,沒有統計詞語的出現次數,因此同一文檔中某個詞匯可能出現多條記錄。 包輸出表格式主要用於兼容Word2Vec組件使用。
實例
采用阿裏分詞實例數據中,將分別將輸出表的兩個列作為詞頻統計的輸入參數:選擇文檔ID列 — id ; 選擇文檔內容列 — text經過詞頻統計運算後,生成的結果 見本組件中第一個輸出參數展示圖。
pai命令示例
pai -name doc_word_stat-project algo_public-DinputTableName=doc_test_split_word-DdocId=id-DdocContent=content-DoutputTableNameMulti=doc_test_stat_multi-DoutputTableNameTriple=doc_test_stat_triple-DinputTablePartitions="region=cctv_news"
算法參數
| 參數key名稱 | 參數描述 | 參數value可選項 | 默認值 |
|---|---|---|---|
| inputTableName | 輸入表名 | - | - |
| docId | 標識文章id的列名 | 僅可指定一列 | - |
| docContent | 標識文章內容的列名 | 僅可指定一列 | - |
| outputTableNameMulti | 輸出保序詞語表名 | - | - |
| outputTableNameTriple | 輸出詞頻統計表名 | - | - |
| inputTablePartitions | 輸入表中指定參與分詞的分區名, 格式為: partition_name=value。如果是多級格式為name1=value1/name2=value2;如果是指定多個分區,中間用’,’分開 | - | 輸入表的所有partition |
備注:其中參數outputTableNameMulti指定的表是docId列及docId列對應的文章內容(docContent)完成分詞後,按各個詞語在文章中出現的順序依次輸出。參數outputTableNameTriple指定的表輸出docId列及docId列對應的文章內容(docContent)完成分詞後,統計得到的各個詞語及其在文章中出現的次數。
TF-IDF
- TF-IDF(term frequency–inverse document frequency)是一種用於資訊檢索與文本挖掘的常用加權技術。TF-IDF是一種統計方法,用以評估一字詞對於一個文件集或一個語料庫中的其中一份文件的重要程度。字詞的重要性隨著它在文件中出現的次數成正比增加,但同時會隨著它在語料庫中出現的頻率成反比下降。TF-IDF加權的各種形式常被搜索引擎應用,作為文件與用戶查詢之間相關程度的度量或評級。
- 詳細介紹,請參考:[維基百科tf-idf]
- 本組件是詞頻統計輸出的基礎上,計算各個word對於各個文章的tfidf值
參數設置(略)
實例
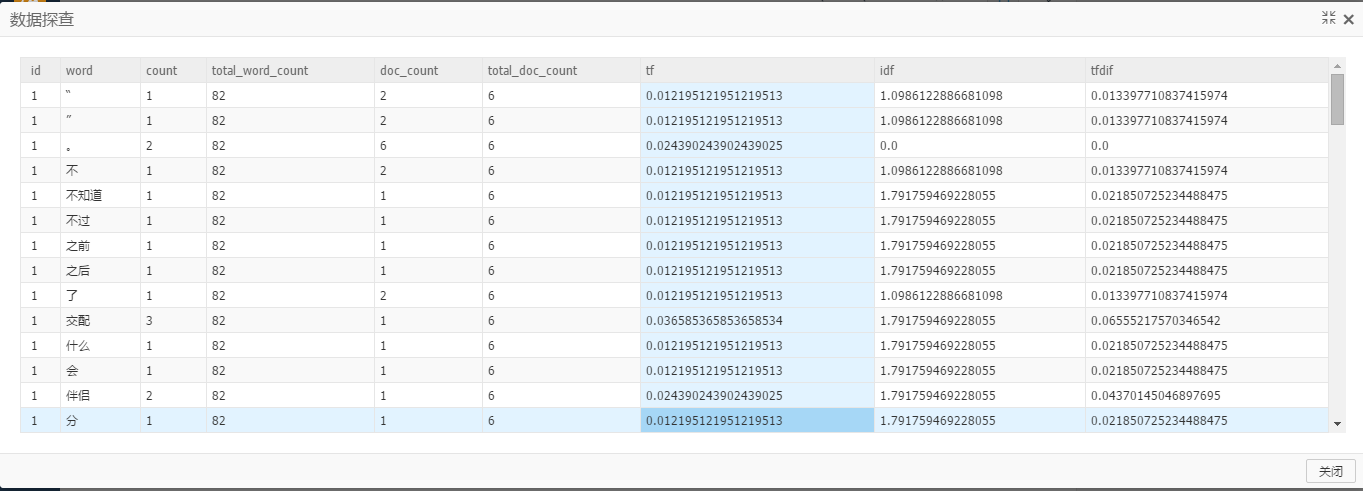
以詞頻統計組件實例中的輸出表作為TF-IDF組件的輸入表,對應的參數設置如下:選擇文檔ID列: id選擇單詞列:word選擇單詞計數列:count
輸出表有9列:docid,word,word_count(當前word在當前doc中出現次數),total_word_count(當前doc中總word數), doc_count(包含當前word的總doc數), total_doc_count(全部doc數), tf, idf, tfidf結果如下:
pai命令示例
pai -name tfidf-project algo_public-DinputTableName=rgdoc_split_triple_out-DdocIdCol=id-DwordCol=word-DcountCol=count-DoutputTableName=rg_tfidf_out;
算法參數
| 參數key名稱 | 參數描述 | 必/選填 | 默認值 |
|---|---|---|---|
| inputTableName | 輸入表名 | 必填 | - |
| inputTablePartitions | 輸入表分區 | 選填 | 輸入表的所有partition |
| docIdCol | 標識文章id的列名,僅可指定一列 | 必填 | - |
| wordCol | word列名,僅可指定一列 | 必填 | - |
| countCol | count列名,僅可指定一列 | 必填 | - |
| outputTableName | 輸出表名 | 必填 | - |
| lifecycle | 輸出表生命周期(單位:天) | 選填 | 無生命周期限製 |
| coreNum | 核心數,需和memSizePerCore同時設置才起作用 | 選填 | 自動計算 |
| memSizePerCore | 內存數,需和coreNum同時設置才起作用 | 選填 | 自動計算 |
PLDA
- 主題模型,返回文檔對應的主題
- LDA(Latent Dirichlet allocation),是一種主題模型,它可以將文檔集中每篇文檔的主題按照概率分布的形式給出。同時它是一種無監督學習算法,在訓練時不需要手工標注的訓練集,需要的僅僅是文檔集以及指定主題的數量k即可。LDA首先由David M. Blei、Andrew Y. Ng和Michael I. Jordan於2003年提出,目前在文本挖掘領域包括文本主題識別、文本分類以及文本相似度計算方麵都有應用。
參數設置
主題個數: 設置LDA的輸出的主題個數Alpha:P(z/d)的先驗狄利克雷分布的參數beta: P(w/z)的先驗狄利克雷分布的參數burn In:burn in 迭代次數,必須小於總迭代次數,默認值:100總迭代次數: 正整數 | 非必選,默認值:150注:z是主題, w是詞, d是文檔
輸入輸出設置
輸入:數據必須為稀疏矩陣的格式(格式見數據格式說明章節)。目前需要用戶自己寫一個MR,實現數據的轉換輸入格式如下:

第一列:docid; 第二列:單詞及詞頻的kv數據
輸出依次為:
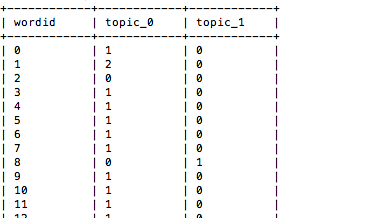
·topic-word頻率貢獻表·單詞|主題輸出表·主題|單詞輸出表·文檔|主題輸出表·主題|文檔輸出表·主題輸出表
topic-word頻率貢獻表的輸出格式如下:
pai命令示例
pai -name PLDA-project algo_public-DinputTableName=lda_input–DtopicNum=10-topicWordTableName=lda_output;
算法參數
| 參數key名稱 | 參數描述 | 取值範圍 | 是否必選,默認值/行為 |
|---|---|---|---|
| inputTableName | 輸入表名 | 表名 | 必選 |
| inputTablePartitions | 輸入表中指定參與分詞的分區名 | 格式為: partition_name=value。如果是多級格式為name1=value1/name2=value2;如果是指定多個分區,中間用’,’分開 | 非必選,默認值:輸入表的所有partition |
| selectedColNames | 輸入表中用於LDA的列名 | 列名,逗號分隔 | 非必選,默認值:輸入表中所有的列名 |
| topicNum | topic的數量 | [2, 500] | 必選 |
| kvDelimiter | key和value間的分分隔符 | 空格、逗號、冒號 | 非必選,默認值:冒號 |
| itemDelimiter | key和key間的分隔符 | 空格、逗號、冒號 | 非必選,默認值:空格 |
| alpha | P(z/d)的先驗狄利克雷分布的參數 | (0, ∞) | 非必選,默認值:0.1 |
| beta | P(w/z)的先驗狄利克雷分布的參數 | (0, ∞) | 非必選,默認值:0.01 |
| topicWordTableName | topic-word頻率貢獻表 | 表名 | 必選 |
| pwzTableName | P(w/z)輸出表 | 表名 | 非必選,默認行為:不輸出P(w/z)表 |
| pzwTableName | P(z/w)輸出表 | 表名 | 非必選,默認行為:不輸出P(z/w)表 |
| pdzTableName | P(d/z)輸出表 | 表名 | 非必選,默認行為:不輸出P(d/z)表 |
| pzdTableName | P(z/d)輸出表 | 表名 | 非必選,默認行為:不輸出P(z/d)表 |
| pzTableName | P(z)輸出表 | 表名 | 非必選,默認行為:不輸出P(z)表 |
| burnInIterations | burn in 迭代次數 | 正整數 | 非必選,必須小於totalIterations,默認值:100 |
| totalIterations | 迭代次數 | 正整數 | 非必選,默認值:150 |
注:z是主題, w是詞, d是文檔
word2vec
功能介紹
- Word2Vec是Google在2013年開源的一個將詞表轉為向量的算法,其利用神經網絡,可以通過訓練,將詞映射到K維度空間向量,甚至對於表示詞的向量進行操作還能和語義相對應,由於其簡單和高效引起了很多人的關注。
- Google Word2Vec的工具包相關鏈接:https://code.google.com/p/word2vec/
參數設置
算法參數:單詞的特征維度:建議 0-1000向下采樣閾值 建議值為1e-3-1e-5
輸入:單詞列和詞匯表輸出:輸出詞向量表和詞匯表
pai命令示例
pai -name Word2Vec-project algo_public-DinputTableName=w2v_input–DwordColName=word-DoutputTableName=w2v_output;
算法參數
| 參數key名稱 | 參數描述 | 取值範圍 | 是否必選,默認值/行為 |
|---|---|---|---|
| inputTableName | 輸入表名 | 表名 | 必選 |
| inputTablePartitions | 輸入表中指定參與分詞的分區名 | 格式為: partition_name=value。如果是多級格式為name1=value1/name2=value2;如果是指定多個分區,中間用’,’分開 | 非必選,默認值:輸入表的所有partition |
| wordColName | 單詞列名,單詞列中每行為一個單詞,語料中換行符用</s>表示 | 列名 | 必選 |
| inVocabularyTableName | 輸入詞表,該表為inputTableName的 wordcount輸出 | 表名 | 非必選,默認行為:程序內部會對輸出表做wordcount |
| inVocabularyPartitions | 輸入詞表分區 | 分區名 | 非必選,默認值:inVocabularyTableName對應表的所有分區 |
| layerSize | 單詞的特征維度 | 0-1000 | 非必選,默認值:100 |
| cbow | 語言模型 | 值為1:表示cbow模型,值為0:skip-gram模型 | 非必選,默認值:0 |
| window | 單詞窗口大小 | 正整數 | 非必選,默認值:5 |
| minCount | 截斷的最小詞頻 | 正整數 | 非必選:默認值:5 |
| hs | 是否采用HIERARCHICAL SOFTMAX | 值為1:表示采用,值為0:不采用 | 非必選,默認值:1 |
| negative | NEGATIVE SAMPLING | 值為0不可用,建議值5-10 | 非必選,默認值:0 |
| sample | 向下采樣閾值 | 值為小於等於0:不采用,建議值為1e-3-1e-5 | 非必選,默認值:0 |
| alpha | 開始學習速率 | 大於0 | 非必選,默認值:0.025 |
| iterTrain | 訓練的迭代次數 | 大於等於1 | 非必選,默認值:1 |
| randomWindow | window是否隨機 | 值為1,表示大小在1~5間隨機;值為0,表示不隨機,其值由window參數指定 | 非必選,默認值:1 |
| outVocabularyTableName | 輸出詞表 | 表名 | 非必選,默認行為:不輸出‘輸出詞表’ |
| outVocabularyPartition | 輸出詞表分區 | 分區名 | 非必選,默認行為:輸出詞表為非分區表 |
| outputTableName | 輸出表 | 表名 | 必選 |
| outputPartition | 輸出表分區信息 | 分區名 | 非必選,默認行為:輸出表為非分區 |
SplitWord
- 基於AliWS(Alibaba Word Segmenter的簡稱)詞法分析係統,對指定列對應的文章內容進行分詞,分詞後的各個詞語間以空格作為分隔符,若用戶指定了詞性標注或語義標注相關參數,則會將分詞結果、詞性標注結果和語義標注結果一同輸出,其中詞性標注分隔符為”/“,語義標注分隔符為”|”。目前僅支持中文淘寶分詞和互聯網分詞。
功能介紹
字段設置(略)
參數設置:
分詞算法:CRF,UNIGRAM識別選項:分詞中,是否識別特殊意義的名詞;合並選項:將具有特殊領域的名詞作為整體,不進行切分操作字符串切分長度:>=0,數字串按指定長度進行截斷作為檢索單元;默認為0,不對數字串進行長度切分使用詞頻糾錯:是否使用糾錯詞典;標注詞性:輸出結果中,標注詞性
實例介紹
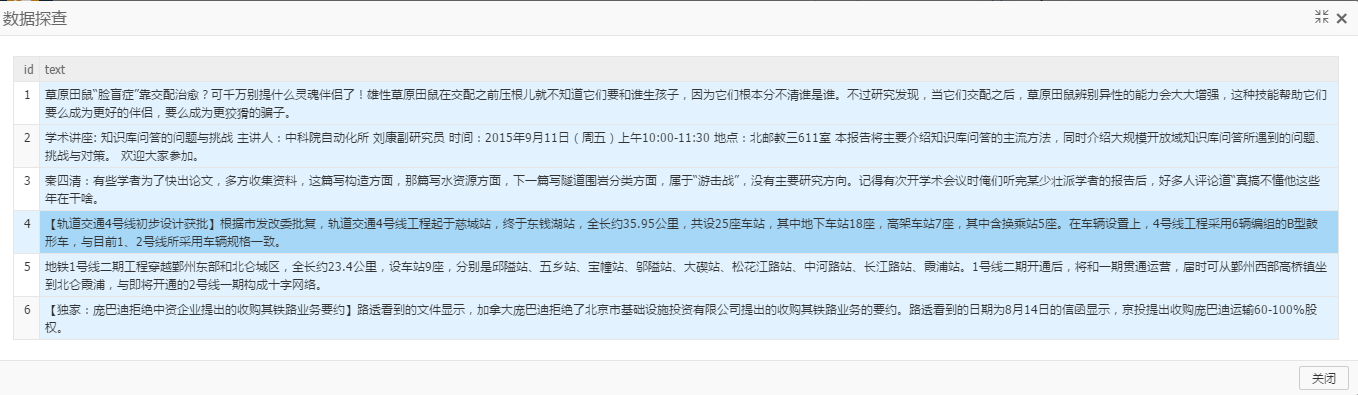
輸入包含兩列的表,第一列是文檔id,第二列是文檔內容text,如下:
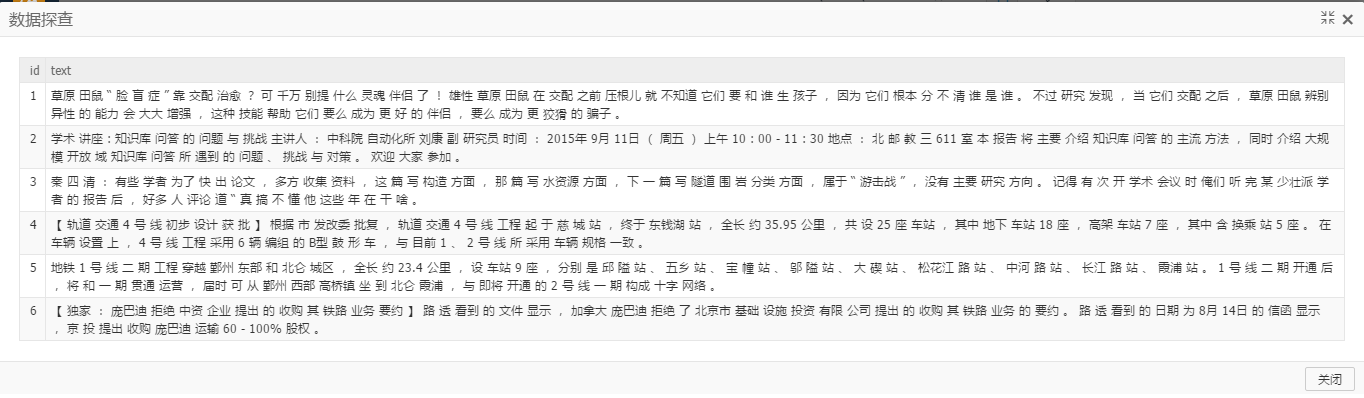
輸出結果如下:
pai命令示例
pai -name split_word-project algo_public-DinputTableName=doc_test-DselectedColNames=content1,content2-DoutputTableName=doc_test_split_word-DinputTablePartitions="region=cctv_news"-DoutputTablePartition="region=news"-Dtokenizer=TAOBAO_CHN-DenableDfa=true-DenablePersonNameTagger=false-DenableOrgnizationTagger=false-DenablePosTagger=false-DenableTelephoneRetrievalUnit=true-DenableTimeRetrievalUnit=true-DenableDateRetrievalUnit=true-DenableNumberLetterRetrievalUnit=true-DenableChnNumMerge=false-DenableNumMerge=true-DenableChnTimeMerge=false-DenableChnDateMerge=false-DenableSemanticTagger=true
算法參數
| 參數key名稱 | 參數描述 | 參數value可選項 | 默認值 |
|---|---|---|---|
| inputTableName | 輸入表名 | - | - |
| selectedColNames | 輸入表中用於分詞的列名 | 可指定多列,列名間用逗號(,)間隔 | - |
| outputTableName | 輸出表名 | - | - |
| inputTablePartitions | 輸入表中指定參與分詞的分區名, 格式為: partition_name=value。如果是多級格式為name1=value1/name2=value2;如果是指定多個分區,中間用’,’分開 | - | 輸入表的所有partition |
| outputTablePartition | 指定輸出表的分區 | - | 輸出表不進行分區 |
| tokenizer | 分類器類型 | TAOBAO_CHN,INTERNET_CHN | 默認為TAOBAO_CHN,淘寶中文分詞;INTERNET_CHN,互聯網中文分詞 |
| enableDfa | 簡單實體識別 | true,false | true |
| enablePersonNameTagger | 人名識別 | true,false | false |
| enableOrgnizationTagger | 機構名識別 | true,false | false |
| enablePosTagger | 是否詞性標注 | true,false | false |
| enableTelephoneRetrievalUnit | 檢索單元配置-電話號碼識別 | true,false | true |
| enableTimeRetrievalUnit | 檢索單元配置-時間號碼識別 | true,false | true |
| enableDateRetrievalUnit | 檢索單元配置-日期號碼識別 | true,false | true |
| enableNumberLetterRetrievalUnit | 檢索單元配置-數字字母識別 | true,false | true |
| enableChnNumMerge | 中文數字合並為一個檢索單元 | true,false | false |
| enableNumMerge | 普通數字合並為一個檢索單元 | true,false | true |
| enableChnTimeMerge | 中文時間合並為一個語意單元 | true,false | false |
| enableChnDateMerge | 中文日期合並為一個語意單元 | true,false | false |
| enableSemanticTagger | 是否語義標準 | true,false | false |
三元組轉kv
功能介紹
- 給定三元組(row,col,value)類型為XXD 或 XXL, X表示任意類型, D表示Double, L表示bigint,轉成kv格式(row,[col_id:value]),其中row和value類型和原始輸入數據一致,col_id類型是bigint,並給出col的索引表映射到col_id
- 輸入表形式如下
| id | word | count |
|---|---|---|
| 01 | a | 10 |
| 01 | b | 20 |
| 01 | c | 30 |
- 輸出kv表如下,kv分隔符可以自定義
| id | key_value |
|---|---|
| 01 | 1:10;2:20;3:30 |
- 輸出word的索引表如下
| key | key_id |
|---|---|
| a | 1 |
| b | 2 |
| c | 3 |
PAI命令示例
PAI -name triple_to_kv-project algo_public-DinputTableName=test_data-DoutputTableName=test_kv_out-DindexOutputTableName=test_index_out-DidColName=id-DkeyColName=word-DvalueColName=count-DinputTablePartitions=ds=test1-DindexInputTableName=test_index_input-DindexInputKeyColName=word-DindexInputKeyIdColName=word_id-DkvDelimiter=:-DpairDelimiter=;-Dlifecycle=3
算法參數
| 參數名稱 | 參數描述 | 參數值可選項 | 默認值 | 備注 |
|---|---|---|---|---|
| inputTableName | 必選,輸入表名 | - | - | 不能為空表 |
| idColName | 必選,轉成kv表時保持不變的列名 | - | - | - |
| keyColName | 必選,kv中的key | - | - | - |
| valueColName | 必選,kv中的value | - | - | - |
| outputTableName | 必選,輸出kv表名 | - | - | - |
| indexOutputTableName | 必選,輸出key的索引表 | - | - | - |
| indexInputTableName | 可選,輸入已有的索引表 | - | “” | 不能是空表,可以隻有部分key的索引 |
| indexInputKeyColName | 可選,輸入索引表key的列名 | - | “” | 輸入indexInputTableName時必選此項 |
| indexInputKeyIdColName | 可選,輸入索引表key索引號的列名 | - | “” | 輸入indexInputTableName時必選此項 |
| inputTablePartitions | 可選,輸入表的分區 | - | “” | 隻能輸入單個分區 |
| kvDelimiter | 可選,key和value之間分隔符 | - | : | - |
| pairDelimiter | 可選,kv對之間分隔符 | - | ; | - |
| lifecycle | 可選,輸出結果表的生命周期 | - | 不設生命周期 | - |
| coreNum | 可選,指定instance的總數 | - | -1 | 默認會根據輸入數據大小計算 |
| memSizePerCore | 可選,指定memory大小,範圍在100~64*1024之間 | - | -1 | 默認會根據輸入數據大小計算 |
實例
測試數據
新建數據SQL
drop table if exists triple2kv_test_input;create table triple2kv_test_input asselect*from(select '01' as id, 'a' as word, 10 as count from dualunion allselect '01' as id, 'b' as word, 20 as count from dualunion allselect '01' as id, 'c' as word, 30 as count from dualunion allselect '02' as id, 'a' as word, 100 as count from dualunion allselect '02' as id, 'd' as word, 200 as count from dualunion allselect '02' as id, 'e' as word, 300 as count from dual) tmp;
運行命令
PAI -name triple_to_kv-project algo_public-DinputTableName=triple2kv_test_input-DoutputTableName=triple2kv_test_input_out-DindexOutputTableName=triple2kv_test_input_index_out-DidColName=id-DkeyColName=word-DvalueColName=count-Dlifecycle=1;
運行結果triple2kv_test_input_out
+------------+------------+| id | key_value |+------------+------------+| 02 | 1:100;4:200;5:300 || 01 | 1:10;2:20;3:30 |+------------+------------+
triple2kv_test_input_index_out
+------------+------------+| key | key_id |+------------+------------+| a | 1 || b | 2 || c | 3 || d | 4 || e | 5 |+------------+------------+
字符串相似度
功能介紹
計算字符串相似度在機器學習領域是一個非常基本的操作,主要用在信息檢索,自然語言處理,生物信息學等領域。本算法支持Levenshtein Distance,Longest Common SubString,String Subsequence Kernel,Cosine,simhash_hamming五種相似度計算方式。支持兩兩計算和top n計算兩種輸入方式。
Levenshtein(Levenshtein Distance)支持距離和相似度兩個參數,相似度=1-距離,距離在參數中表示為levenshtein,相似度在參數中表示為levenshtein_sim。
lcs(Longest Common SubString)支持距離和相似度兩個參數,相似度=1-距離,距離在參數中表示為lcs,相似度在參數中表示為lcs_sim。
ssk(String Subsequence Kernel)支持相似度計算,在參數中表示為ssk。
參考:Lodhi, Huma; Saunders, Craig; Shawe-Taylor, John; Cristianini, Nello; Watkins, Chris (2002). “Text classification using string kernels”. Journal of Machine Learning Research: 419–444.
cosine(Cosine)支持相似度計算,在參數中表示為cosine。
參考:Leslie, C.; Eskin, E.; Noble, W.S. (2002), The spectrum kernel: A string kernel for SVM protein classification 7, pp. 566–575
simhash_hamming,其中SimHash算法是把原始的文本映射為64位的二進製指紋,HammingDistance則是計算二進製指紋在相同位置上不同的字符的個數,支持距離和相似度兩個參數,相似度=1-距離/64.0,距離在參數中表示為simhash_hamming,相似度在參數中表示為simhash_hamming_sim。
SimHash詳細介紹請見pdf;
HammingDistance詳細介紹請見維基百科鏈接wiki
兩兩計算
PAI命令
PAI -name string_similarity-project algo_public-DinputTableName="pai_test_string_similarity"-DoutputTableName="pai_test_string_similarity_output"-DinputSelectedColName1="col0"-DinputSelectedColName2="col1";
算法參數
| 參數名稱 | 參數描述 | 參數可選項 | 參數默認值 |
|---|---|---|---|
| inputTableName | 必選,輸入表的表名 | - | - |
| outputTableName | 必選,輸出表的表名 | - | - |
| inputSelectedColName1 | 可選,相似度計算中第一列的列名 | - | 表中第一個為類型為string的列名 |
| inputSelectedColName2 | 可選,相似度計算中第二列的列名 | - | 表中第二個為類型為string的列名 |
| inputAppendColNames | 可選,輸出表追加的列名 | - | 不追加 |
| inputTablePartitions | 可選,輸入表選中的分區 | - | 選擇全表 |
| outputColName | 可選,輸出表中相似度列的列名。列名中不能有特殊字符,隻能用英文的a-z,A-Z及數字和下劃線_,且以字母開頭,名稱的長度不超過128字節。 | - | output |
| method | 可選,相似度計算方法 | levenshtein, levenshtein_sim, lcs, lcs_sim, ssk, cosine, simhash_hamming, simhash_hamming_sim | levenshtein_sim |
| lambda | 可選,匹配字符串的權重,ssk中可用 | (0, 1) | 0.5 |
| k | 可選,子串的長度,ssk和cosine中可用 | (0, 100) | 2 |
| lifecycle | 可選,指定輸出表的生命周期 | 正整數 | 沒有生命周期 |
| coreNum | 可選,計算的核心數 | 正整數 | 係統自動分配 |
| memSizePerCore | 可選,每個核心的內存(單位為兆) | 正整數,範圍(0, 65536) | 係統自動分配 |
示例
測試數據
create table pai_ft_string_similarity_input as select * from(select 0 as id, "北京" as col0, "北京" as col1 from dualunion allselect 1 as id, "北京" as col0, "北京上海" as col1 from dualunion allselect 2 as id, "北京" as col0, "北京上海香港" as col1 from dual)tmp;
pai命令
PAI -name string_similarity-project sre_mpi_algo_dev-DinputTableName=pai_ft_string_similarity_input-DoutputTableName=pai_ft_string_similarity_output-DinputSelectedColName1=col0-DinputSelectedColName2=col1-Dmethod=simhash_hamming-DinputAppendColNames=col0,col1;
輸出說明
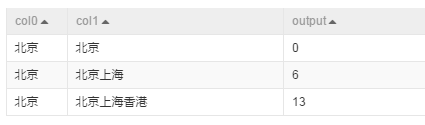
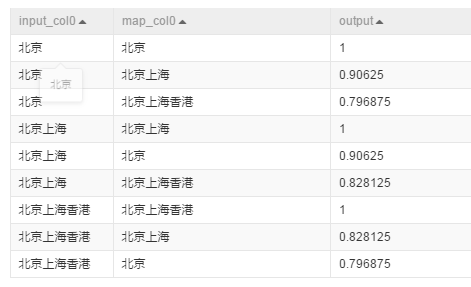
方法simhash_hamming輸出結果如下:
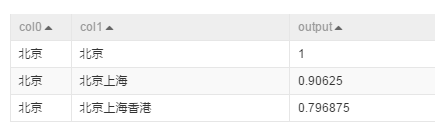
方法simhash_hamming_sim輸出結果如下:
字符串相似度-topN
PAI命令
PAI -name string_similarity_topn-project algo_public-DinputTableName="pai_test_string_similarity_topn"-DoutputTableName="pai_test_string_similarity_topn_output"-DmapTableName="pai_test_string_similarity_map_topn"-DinputSelectedColName="col0"-DmapSelectedColName="col1";
算法參數
| 參數名稱 | 參數描述 | 參數可選項 | 參數默認值 |
|---|---|---|---|
| inputTableName | 必選,輸入表的表名 | - | - |
| mapTableName | 必選,輸入的映射表名 | - | - |
| outputTableName | 必選,輸出表的表名 | - | - |
| inputSelectedColName | 可選,相似度計算中左表的列名 | - | 表中第一個為類型為string的列名 |
| mapSelectedColName | 可選,相似度計算中映射表的列名,左表中的每一行都會和映射表中所有的字符串計算出相似度,並最終已top n的方式給出結果 | - | 表中第一個為類型為string的列名 |
| inputAppendColNames | 可選,輸入表在輸出表追加的列名 | - | 不追加 |
| inputAppendRenameColNames | 可選,輸入表在輸出表追加的列名的別名,在inputAppendColNames不為空時有效 | - | 不使用別名 |
| mapAppendColNames | 可選,映射表在輸出表追加的列名 | - | 不追加 |
| mapAppendRenameColNames | 可選,映射表在輸出表追加的列名的別名 | - | 不使用別名 |
| inputTablePartitions | 可選,輸入表選中的分區 | - | 選擇全表 |
| mapTablePartitions | 可選,映射表中的分區 | - | 選擇全表 |
| outputColName | 可選,輸出表中相似度列的列名, 列名中不能有特殊字符,隻能用英文的a-z,A-Z及數字和下劃線_,且以字母開頭,名稱的長度不超過128字節。 | - | output |
| method | 可選,相似度計算方法 | levenshtein_sim, lcs_sim, ssk, cosine, simhash_hamming_sim | levenshtein_sim |
| lambda | 可選,匹配字符串的權重,ssk中可用 | (0, 1) | 0.5 |
| k | 可選,子串的長度,ssk和cosine中可用 | (0, 100) | 2 |
| topN | 可選,最終給出的相似度最大值的個數 | (0, +∞) | 10 |
| lifecycle | 可選,指定輸出表的生命周期 | 正整數 | 沒有生命周期 |
| coreNum | 可選,計算的核心數 | 正整數 | 係統自動分配 |
| memSizePerCore | 可選,每個核心的內存(單位為兆) | 正整數,範圍(0, 65536) | 係統自動分配 |
示例
測試數據
create table pai_ft_string_similarity_topn_input as select * from(select 0 as id, "北京" as col0 from dualunion allselect 1 as id, "北京上海" as col0 from dualunion allselect 2 as id, "北京上海香港" as col0 from dual)tmp;
pai命令
PAI -name string_similarity_topn-project sre_mpi_algo_dev-DinputTableName=pai_ft_string_similarity_topn_input-DmapTableName=pai_ft_string_similarity_topn_input-DoutputTableName=pai_ft_string_similarity_topn_output-DinputSelectedColName=col0-DmapSelectedColName=col0-DinputAppendColNames=col0-DinputAppendRenameColNames=input_col0-DmapAppendColNames=col0-DmapAppendRenameColNames=map_col0-Dmethod=simhash_hamming_sim;
輸出說明
停用詞過濾
功能介紹
停用詞過濾,是文本分析中一個預處理方法。它的功能是過濾分詞結果中的噪聲(例如:的、是、啊等)。
參數設置
組件說明

兩個輸入樁,從左到右依次為:
- 輸入表,即需要過濾的分詞結果表;對應的參數名為inputTableName
- 停用詞表,表的格式為一列,每行為一個停用詞;對應的參數名為noiseTableName
參數界麵說明
- 可以選擇需要過渡的列
執行調化說明
- 可以自己配置並發計算核心數目與內存,默認係統自動分配
PAI命令
PAI -name FilterNoise -project algo_public-DinputTableName=”test_input” -DnoiseTableName=”noise_input”-DoutputTableName=”test_output”-DselectedColNames=”words_seg1,words_seg2”-Dlifecycle=30
算法參數
| 參數名稱 | 參數描述 | 參數可選項 | 參數默認值 |
|---|---|---|---|
| inputTableName | 必選,輸入表的表名 | - | - |
| inputTablePartitions | 可選,輸入表中指定參與計算的分區 | - | 輸入表的所有partitions |
| noiseTableName | 必選,停用詞表 | 格式為一列,每一行一個詞 | - |
| noiseTablePartitions | 可選,停用詞表的分區 | 全表 | |
| outputTableName | 必選,輸出表 | - | - |
| selectedColNames | 必選,待過濾列,多列時以逗號為分隔 | - | - |
| lifecycle | 可選,指定輸出表的生命周期 | 正整數 | 沒有生命周期 |
| coreNum | 可選,計算的核心數 | 正整數 | 係統自動分配 |
| memSizePerCore | 可選,每個核心的內存(單位為兆) | 正整數,範圍(0, 65536) | 係統自動分配 |
示例
源數據
- 分詞的結果表 temp_word_seg_input
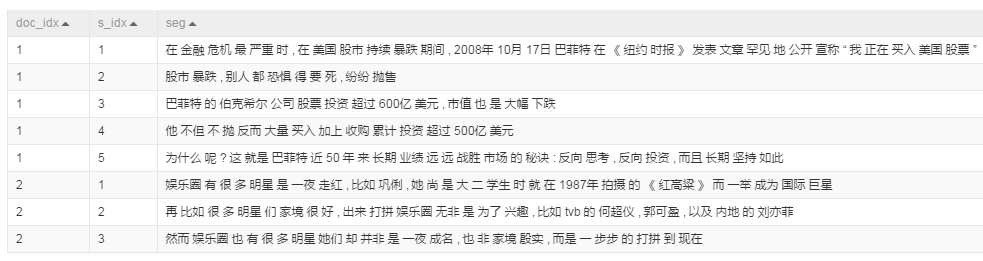
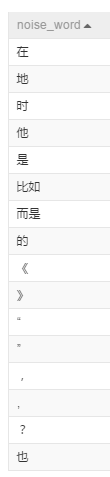
停用詞表 temp_word_noise_input
1 創建實驗
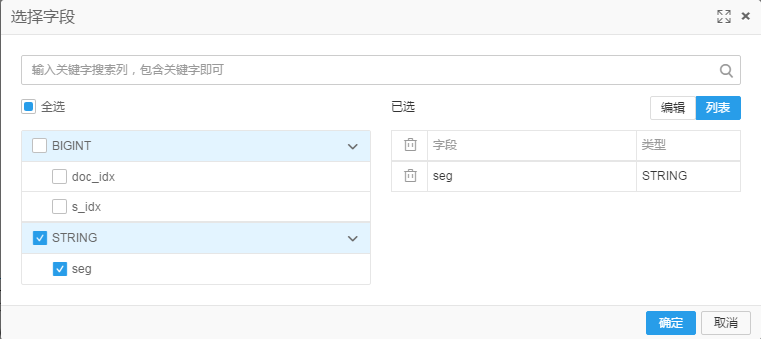
2 選擇待過濾列 seg
3 運行結果
最後更新:2016-09-09 09:58:16
上一篇: 統計分析__使用手冊(new)_機器學習-阿裏雲
統計分析__使用手冊(new)_機器學習-阿裏雲
下一篇: 網絡分析__使用手冊(new)_機器學習-阿裏雲
- RemoveTags__標簽相關API_API 參考_負載均衡-阿裏雲
- 處理非結構化數據__快速開始_大數據計算服務-阿裏雲
- 步驟2:https網站接入__快速入門(網站業務)_DDoS 高防IP-阿裏雲
- 阿裏雲ECS全球啟用秒級計費
- 多行數據操作__Java-SDK_SDK 參考_表格存儲-阿裏雲
- 查詢實例列表__實例相關接口_API 參考_雲服務器 ECS-阿裏雲
- 角色管理__用戶及授權管理_安全指南_大數據計算服務-阿裏雲
- 查詢字節緩存命中率__資源監控接口_API 手冊_CDN-阿裏雲
- ALIYUN::SLS::MachineGroup__資源列表_資源編排-阿裏雲
- 典型場景__產品簡介_業務實時監控服務 ARMS-阿裏雲
相關內容
- 常見錯誤說明__附錄_大數據計算服務-阿裏雲
- 發送短信接口__API使用手冊_短信服務-阿裏雲
- 接口文檔__Android_安全組件教程_移動安全-阿裏雲
- 運營商錯誤碼(聯通)__常見問題_短信服務-阿裏雲
- 設置短信模板__使用手冊_短信服務-阿裏雲
- OSS 權限問題及排查__常見錯誤及排除_最佳實踐_對象存儲 OSS-阿裏雲
- 消息通知__操作指南_批量計算-阿裏雲
- 設備端快速接入(MQTT)__快速開始_阿裏雲物聯網套件-阿裏雲
- 查詢API調用流量數據__API管理相關接口_API_API 網關-阿裏雲
- 使用STS訪問__JavaScript-SDK_SDK 參考_對象存儲 OSS-阿裏雲