![]() 462
462
![]()
![]() 微信
微信
处理非结构化数据__快速开始_大数据计算服务-阿里云
重要提示:目前MaxCompute处理非结构化数据功能仍属于公测范畴。我们不建议您将该功能用于生产实践。有意愿申请试用非结构化处理的用户可通过扫描MaxCompute产品详情页的钉钉群二维码提交试用申请。
MaxCompute作为阿里云大数据平台的核心计算组件,拥有强大的计算能力,能够调度大量的节点做并行计算。而MaxCompute SQL能在简明的语义上实现各种数据处理逻辑,在阿里巴巴集团内外更是广为应用,在其上实现与各种数据源的互通,对于打通整个阿里云的数据生态具有重要意义。基于这一点,最近MaxCompute团队依托MaxCompute2.0系统架构,引入了非结构化数据处理框架:通过外部表,为各种数据在MaxCompute上的计算处理提供了入口。这里以MaxCompute处理存储在OSS上的数据为例,介绍这些新功能。
本文介绍了一种外部表的功能,支持旨在提供处理除了MaxCompute现有表格以外的其他数据的能力。在这个框架中,通过一条简单的创建表语句,即可在MaxCompute上创建一张外部表,建立MaxCompute表与外部数据源的关联,提供各种数据的接入和输出能力。创建好的外部表可以像普通的MaxCompute表一样使用(大部分场景),充分利用MaxCompute SQL的强大计算功能。
这里的各种数据涵盖两个维度:
- 多样的数据存储介质
- 插件式的框架可以对接多种数据存储介质,比如OSS、Table Store。
- 多样的数据格式:MaxCompute表是结构化的数据,而外部表可以不限于结构化数据
- 完全无结构数据,比如图像,音频,视频文件等;
- 半结构化数据,比如CSV,TSV等隐含一定schema的文本文件;
- 除MaxCompute表结构外的结构化数据; 比如Table Store数据;
下面通过一个简单例子,来演示如何在MaxCompute上轻松访问OSS上的数据。
1. 系统内置方式读取OSS数据
重要提示:未开通MaxCompute 2.0版本的用户将无法使用此示例。有意愿申请试用非结构化处理的用户可通过扫描MaxCompute产品详情页的钉钉群二维码提交试用申请。
访问外部数据源时,需要用户自定义不同的Extractor。同时您同样可以使用MaxCompute内置的 Extractor,来读取按照约定格式存储的OSS数据。我们只需要创建一个外部表,就能以这张表为源表做查询。假设有一份CSV数据存在OSS上,endpoint为oss-cn-shanghai-internal.aliyuncs.com,bucket为oss-odps-test,数据文件放在/demo/vehicle.csv。
1.1 授予权限
首先需要在RAM中授权MaxCompute访问OSS的权限。登录RAM控制台,通过控制台中的角色管理创建角色AliyunODPSDefaultRole:
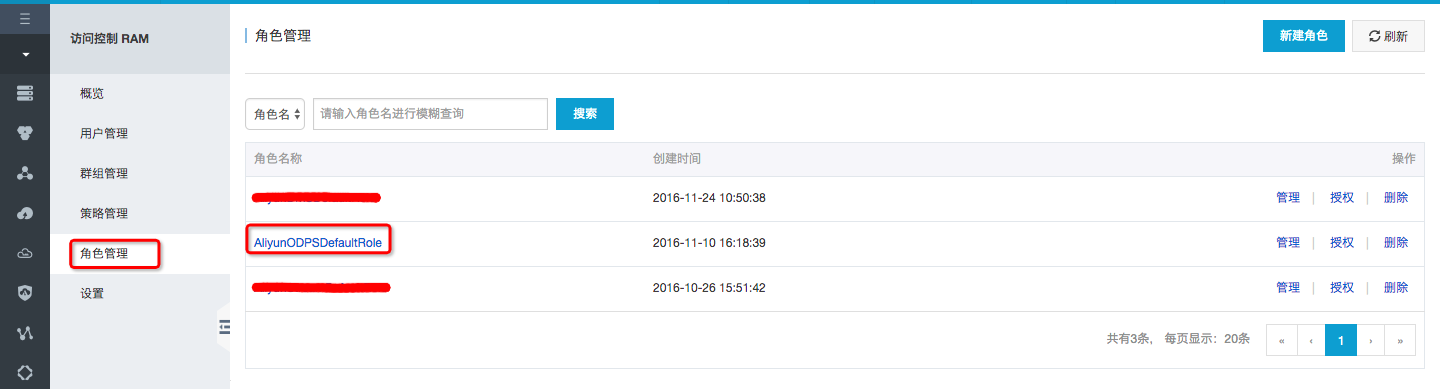
并将策略内容设置为:
{"Statement": [{"Action": "sts:AssumeRole","Effect": "Allow","Principal": {"Service": ["odps.aliyuncs.com"]}}],"Version": "1"}
然后编辑该角色的授权策略,将权限AliyunODPSRolePolicy授权给该角色。如果觉得这些步骤太麻烦,可以点击此处完成一键授权。
1.2 创建外部表
执行一条DDL语句,创建外部表
set odps.task.major.version=2dot0_demo_flighting;set odps.sql.planner.mode=lot;set odps.sql.ddl.odps2=true;set odps.sql.preparse.odps2=lot; -- (1)CREATE EXTERNAL TABLE IF NOT EXISTS ambulance_data_csv_external(vehicleId int,recordId int,patientId int,calls int,locationLatitute double,locationLongtitue double,recordTime string,direction string)STORED BY 'com.aliyun.odps.CsvStorageHandler' -- (2)WITH SERDEPROPERTIES ('odps.properties.rolearn'='acs:ram::1811270634786818:role/aliyunodpsdefaultrole') -- (3)LOCATION 'oss://oss-cn-shanghai-internal.aliyuncs.com/oss-odps-test/Demo/'; -- (4)(5)
说明:
- 上述四个
set命令是必须与创建表语句一并执行的。否则创建表语句将会报错; com.aliyun.odps.CsvStorageHandler是内置的处理CSV格式文件的StorageHandler,它定义了如何读写CSV文件。我们只需要指明这个名字,相关逻辑已经由系统实现。odps.properties.rolearn中的信息是RAM中AliyunODPSDefaultRole的Arn信息。您可以通过RAM控制台中的角色详情获取到。LOCATION必须指定一个OSS目录,默认系统会读取这个目录下所有的文件。
- 强烈建议您使用OSS提供的内网域名,否则将产生OSS流量费用;
- 建议您将OSS数据上传至华东2(上海)区域;由于MaxCompute只有在上海部署,我们不承诺跨区域的数据连通性;
- 此外,请注意,OSS的连接格式为
oss://oss-cn-shanghai-internal.aliyuncs.com/Bucket名称/目录名称/。目录后不要加文件名称。如下的集中用法都是错误的:https://oss-odps-test.oss-cn-shanghai-internal.aliyuncs.com/Demo/ -- 不支持http连接https://oss-odps-test.oss-cn-shanghai-internal.aliyuncs.com/Demo/ -- 不支持https连接oss://oss-odps-test.oss-cn-shanghai-internal.aliyuncs.com/Demo -- 连接地址错误oss://oss://oss-cn-shanghai-internal.aliyuncs.com/oss-odps-test/Demo/vehicle.csv -- 不必指定文件名
外部表只是在系统中记录了与OSS目录的关联,当DROP这张表时,对应的
LOCATION数据不会被删除。
备注:更多有关外部表的说明请点击这里。
1.3 查询外部表
外部表创建成功后,我们可以像对普通表一样使用这个外部表。假设/demo/vehicle.csv数据为:
1,1,51,1,46.81006,-92.08174,9/14/2014 0:00,S1,2,13,1,46.81006,-92.08174,9/14/2014 0:00,NE1,3,48,1,46.81006,-92.08174,9/14/2014 0:00,NE1,4,30,1,46.81006,-92.08174,9/14/2014 0:00,W1,5,47,1,46.81006,-92.08174,9/14/2014 0:00,S1,6,9,1,46.81006,-92.08174,9/14/2014 0:00,S1,7,53,1,46.81006,-92.08174,9/14/2014 0:00,N1,8,63,1,46.81006,-92.08174,9/14/2014 0:00,SW1,9,4,1,46.81006,-92.08174,9/14/2014 0:00,NE1,10,31,1,46.81006,-92.08174,9/14/2014 0:00,N
建议您将OSS数据上传至华东2(上海)区域;由于MaxCompute只有在上海部署,我们不承诺跨区域的数据连通性;
执行如下SQL:
set odps.task.major.version=2dot0_demo_flighting;set odps.sql.planner.mode=lot;set odps.sql.ddl.odps2=true;set odps.sql.preparse.odps2=lot;select recordId, patientId, direction from ambulance_data_csv_external where patientId > 25;
这条语句会提交一个作业,调用内置csv extractor,从OSS读取数据进行处理。输出结果为:
+------------+------------+-----------+| recordId | patientId | direction |+------------+------------+-----------+| 1 | 51 | S || 3 | 48 | NE || 4 | 30 | W || 5 | 47 | S || 7 | 53 | N || 8 | 63 | SW || 10 | 31 | N |+------------+------------+-----------+
2. 自定义Extractor访问OSS
当OSS中数据格式比较复杂,内置的Extractor无法满足需求时,需要自定义Extractor来读取OSS文件中的数据。例如有一个txt数据文件,并不是CSV格式,记录之间的列通过|分割。/demo/SampleData/CustomTxt/AmbulanceData/vehicle.csv数据为:
1|1|51|1|46.81006|-92.08174|9/14/2014 0:00|S1|2|13|1|46.81006|-92.08174|9/14/2014 0:00|NE1|3|48|1|46.81006|-92.08174|9/14/2014 0:00|NE1|4|30|1|46.81006|-92.08174|9/14/2014 0:00|W1|5|47|1|46.81006|-92.08174|9/14/2014 0:00|S1|6|9|1|46.81006|-92.08174|9/14/2014 0:00|S1|7|53|1|46.81006|-92.08174|9/14/2014 0:00|N1|8|63|1|46.81006|-92.08174|9/14/2014 0:00|SW1|9|4|1|46.81006|-92.08174|9/14/2014 0:00|NE1|10|31|1|46.81006|-92.08174|9/14/2014 0:00|N
2.1 定义Extractor
可以写一个通用的Extractor,将分隔符作为参数传进来,可以处理所有类似格式的text文件。
/*** Text extractor that extract schematized records from formatted plain-text(csv, tsv etc.)**/public class TextExtractor extends Extractor {private InputStreamSet inputs;private String columnDelimiter;private DataAttributes attributes;private BufferedReader currentReader;private boolean firstRead = true;public TextExtractor() {// default to ",", this can be overwritten if a specific delimiter is provided (via DataAttributes)this.columnDelimiter = ",";}// no particular usage for execution context in this example@Overridepublic void setup(ExecutionContext ctx, InputStreamSet inputs, DataAttributes attributes) {this.inputs = inputs; // (1)this.attributes = attributes;// check if "delimiter" attribute is supplied via SQL queryString columnDelimiter = this.attributes.getValueByKey("delimiter"); // (2)if ( columnDelimiter != null){this.columnDelimiter = columnDelimiter;}// note: more properties can be inited from attributes if needed}@Overridepublic Record extract() throws IOException {String line = readNextLine();if (line == null) {return null; // (5)}return textLineToRecord(line); // (3)(4)}@Overridepublic void close(){// no-op}}
说明:
- inputs是一个InputStreamSet,每次调用next()返回一个InputStream,这个InputStream可以读取一个OSS文件的所有内容。
- delimiter通过DDL语句传参。
- textLineToRecord将一行数据按照delimiter分割为多个列,完整实现可以参考: 此链接。
- extactor()调用返回一条Record,代表外部表中的一条记录。
- 返回NULL来表示这个表中已经没有记录可读。
2.2 定义StorageHandler
StorageHandler作为External Table自定义逻辑的统一入口。
package com.aliyun.odps.udf.example.text;public class TextStorageHandler extends OdpsStorageHandler {@Overridepublic Class<? extends Extractor> getExtractorClass() {return TextExtractor.class;}@Overridepublic Class<? extends Outputer> getOutputerClass() {return TextOutputer.class;}}
2.3 编译打包
将自定义代码编译打包,并上传到MaxCompute。
add jar odps-udf-example.jar;
2.4 创建External表
与使用内置Extractor类似,我们同样需要建立一个外部表,不同的是这次需要指定外部表访问数据的时候,使用自定义的StorageHandler。
set odps.task.major.version=2dot0_demo_flighting;set odps.sql.planner.mode=lot;set odps.sql.ddl.odps2=true;set odps.sql.preparse.odps2=lot;CREATE EXTERNAL TABLE IF NOT EXISTS ambulance_data_txt_external(vehicleId int,recordId int,patientId int,calls int,locationLatitute double,locationLongtitue double,recordTime string,direction string)STORED BY 'com.aliyun.odps.udf.example.text.TextStorageHandler' -- (1)with SERDEPROPERTIES ('delimiter'='\|', --(2)'odps.properties.rolearn'='acs:ram::xxxxxxxxxxxxx:role/aliyunodpsdefaultrole')LOCATION 'oss://oss-cn-shanghai-internal.aliyuncs.com/oss-odps-test/Demo/SampleData/CustomTxt/AmbulanceData/'USING 'odps-udf-example.jar'; --(3)
说明:
- STORED BY指定自定义StorageHandler的类名;
- SERDEPROPERITES可以指定参数,这些参数会通过DataAttributes传递到Extractor代码中;
- 同时需要指定类定义所在的jar包;
2.5 查询外部表
执行:
set odps.task.major.version=2dot0_demo_flighting;set odps.sql.planner.mode=lot;set odps.sql.ddl.odps2=true;set odps.sql.preparse.odps2=lot;select recordId, patientId, direction from ambulance_data_txt_external where patientId > 25;
3. 通过自定义Extractor读取非结构化数据
在前面我们看到了通过内置与自定义的Extractor可以轻松处理存储在OSS上的CSV等文本数据。接下来我们以语音数据(wav格式文件)为例,来看看怎样通过自定义的Extractor来访问处理OSS上的非文本文件。
这里我们从最终执行的SQL开始,介绍以MaxCompute SQL为入口,处理存放在OSS上的语音文件的使用方法:
set odps.task.major.version=2dot0_demo_flighting;set odps.sql.planner.mode=lot;set odps.sql.ddl.odps2=true;set odps.sql.preparse.odps2=lot;CREATE EXTERNAL TABLE IF NOT EXISTS speech_sentence_snr_external(sentence_snr double,id string)STORED BY 'com.aliyun.odps.udf.example.speech.SpeechStorageHandler'WITH SERDEPROPERTIES ('mlfFileName'='sm_random_5_utterance.text.label' ,'speechSampleRateInKHz' = '16')LOCATION 'oss://oss-cn-shanghai-internal.aliyuncs.com/oss-odps-test/dev/SpeechSentenceTest/'USING 'odps-udf-example.jar,sm_random_5_utterance.text.label';
这里我们依然建立的外部表,并且通过外部表的Schema定义了我们希望通过外部表从语音文件中抽取出来的信息:
- 一个语音文件中的语句信噪比(SNR):sentence_snr;
- 对应语音文件的名字:id;
创建了外部表后,通过标准的Select语句进行查询,则会触发Extractor运行计算。从这我们可以更直接的感受到,在读取处理OSS数据时,除了之前介绍过的对文本文件做简单的反序列化处理,还可以通过在自定义的Extractor中实现更复杂的数据处理抽取逻辑:在这个例子中,我们通过自定义的Ecom.aliyun.odps.udf.example.speech.SpeechStorageHandler 中封装的Extractor, 实现了对语音文件计算平均有效语句信噪比的功能,并将抽取出来的结构化数据直接进行SQL运算(WHERE sentence_snr > 10), 最终返回所有信噪比大于10的语音文件以及对应的信噪比值。
在OSS地址oss://oss-cn-hangzhou-zmf.aliyuncs.com/oss-odps-test/dev/SpeechSentenceTest/上,存储了原始的多个WAV格式的语音文件,MaxCompute 框架将读取该地址上的所有文件,并在必要的时候进行文件级别的分片,自动将文件分配给多个计算节点处理。每个计算节点上的Extractor则负责处理通过InputStreamSet分配给该节点的文件集。具体的处理逻辑则与用户单机程序相仿,用户不用关心分布计算中的种种细节,按照类单机方式实现其用户算法即可。
这里简单介绍一下定制化的SpeechSentenceSnrExtractor主体逻辑。首先我们在setup接口中读取参数,进行初始化,并且导入语音处理模型(通过resource引入):
public SpeechSentenceSnrExtractor(){this.utteranceLabels = new HashMap<String, UtteranceLabel>();}@Overridepublic void setup(ExecutionContext ctx, InputStreamSet inputs, DataAttributes attributes){this.inputs = inputs;this.attributes = attributes;this.mlfFileName = this.attributes.getValueByKey(MLF_FILE_ATTRIBUTE_KEY);String sampleRateInKHzStr = this.attributes.getValueByKey(SPEECH_SAMPLE_RATE_KEY);this.sampleRateInKHz = Double.parseDouble(sampleRateInKHzStr);try {// read the speech model file from resource and load the model into memoryBufferedInputStream inputStream = ctx.readResourceFileAsStream(mlfFileName);loadMlfLabelsFromResource(inputStream);inputStream.close();} catch (IOException e) {throw new RuntimeException("reading model from mlf failed with exception " + e.getMessage());}}
Extractor()接口中,实现了对语音文件的具体读取和处理逻辑,对读取的数据根据语音模型进行信噪比的计算,并且将结果填充成[snr, id]格式的Record。这个例子中对实现进行了简化,同时也没有包括涉及语音处理的算法逻辑,具体实现可参靠MaxCompute SDK在开源社区中提供的样例代码。
@Overridepublic Record extract() throws IOException {SourceInputStream inputStream = inputs.next();if (inputStream == null){return null;}// process one wav file to extract one output record [snr, id]String fileName = inputStream.getFileName();fileName = fileName.substring(fileName.lastIndexOf('/') + 1);logger.info("Processing wav file " + fileName);String id = fileName.substring(0, fileName.lastIndexOf('.'));// read speech file into memory bufferlong fileSize = inputStream.getFileSize();byte[] buffer = new byte[(int)fileSize];int readSize = inputStream.readToEnd(buffer);inputStream.close();// compute the avg sentence snrdouble snr = computeSnr(id, buffer, readSize);// construct output record [snr, id]Column[] outputColumns = this.attributes.getRecordColumns();ArrayRecord record = new ArrayRecord(outputColumns);record.setDouble(0, snr);record.setString(1, id);return record;}private void loadMlfLabelsFromResource(BufferedInputStream fileInputStream)throws IOException {// skipped here}// compute the snr of the speech sentence, assuming the input buffer contains the entire content of a wav fileprivate double computeSnr(String id, byte[] buffer, int validBufferLen){// computing the snr value for the wav file (supplied as byte buffer array), skipped here}
执行查询:
set odps.task.major.version=2dot0_demo_flighting;set odps.sql.planner.mode=lot;set odps.sql.ddl.odps2=true;set odps.sql.preparse.odps2=lot;select sentence_snr, idfrom speech_sentence_snr_externalwhere sentence_snr > 10.0;
可获得计算结果:
--------------------------------------------------------------| sentence_snr | id |--------------------------------------------------------------| 34.4703 | J310209090013_H02_K03_042 |--------------------------------------------------------------| 31.3905 | tsh148_seg_2_3013_3_6_48_80bd359827e24dd7_0 |--------------------------------------------------------------| 35.4774 | tsh148_seg_3013_1_31_11_9d7c87aef9f3e559_0 |--------------------------------------------------------------| 16.0462 | tsh148_seg_3013_2_29_49_f4cb0990a6b4060c_0 |--------------------------------------------------------------| 14.5568 | tsh_148_3013_5_13_47_3d5008d792408f81_0 |--------------------------------------------------------------
可以看到,通过自定义Extractor,我们在SQL语句上即可分布式地处理多个OSS上语音数据文件。同样的,用类似的方法,我们可以方便的利用MaxCompute的大规模计算能力,完成对图像,视频等各种类型非结构化数据的处理。
最后更新:2016-12-15 13:25:27
上一篇: 编写Graph__快速开始_大数据计算服务-阿里云
编写Graph__快速开始_大数据计算服务-阿里云
下一篇: 项目空间__基本概念_基本介绍_大数据计算服务-阿里云
- UpdateRole__角色管理接口_RAM API文档_访问控制-阿里云
- 授权策略示例__子账号访问IoT_控制台使用手册_阿里云物联网套件-阿里云
- 新建自定义路由__路由表相关接口_API 参考_云服务器 ECS-阿里云
- 创建订阅__订阅操作_快速入门_消息服务-阿里云
- 单IP多HTTPS域名场景下的解决方案__最佳实践_HTTPDNS-阿里云
- DescribeRuleAttribute__转发规则相关API_API 参考_负载均衡-阿里云
- 安全组默认规则__安全组_用户指南_云服务器 ECS-阿里云
- 查询共享带宽包监控信息__监控相关接口_API参考_专有网络 VPC-阿里云
- 创建存储过程__数据库开发_用户指南(RDBMS)_数据管理-阿里云
- SetPasswordPolicy__安全设置接口_RAM API文档_访问控制-阿里云
相关内容
- 常见错误说明__附录_大数据计算服务-阿里云
- 发送短信接口__API使用手册_短信服务-阿里云
- 接口文档__Android_安全组件教程_移动安全-阿里云
- 运营商错误码(联通)__常见问题_短信服务-阿里云
- 设置短信模板__使用手册_短信服务-阿里云
- OSS 权限问题及排查__常见错误及排除_最佳实践_对象存储 OSS-阿里云
- 消息通知__操作指南_批量计算-阿里云
- 设备端快速接入(MQTT)__快速开始_阿里云物联网套件-阿里云
- 查询API调用流量数据__API管理相关接口_API_API 网关-阿里云
- 使用STS访问__JavaScript-SDK_SDK 参考_对象存储 OSS-阿里云