![]() 707
707
![]()
![]() windows
windows
統計分析__使用手冊(new)_機器學習-阿裏雲
統計分析
目錄
百分位
對一個存在的表,單列數據計算百分位
參數設置
選擇需要分析的字段,僅支持double類型和bigint類型
運行結果,如下
PAI 命令
PAI -name Percentile -project algo_public -DoutputTableName="pai_temp_666_6014_1"-DcolName="euribor3m" -DinputTableName="bank_data";
- name: 組件名字
- project: project名字,用於指定算法所在空間。係統默認是algo_public,用戶自己更改後係統會報錯
- outputTableName: 係統執行百分位運算後自動分配的結果表
- colName:要計算百分位的列,僅支持數字型
- inputTableName: 輸入表的名字
全表統計
對一個存在的表,進行全表基本統計,或者僅對選中的列做統計
PAI 命令
PAI -name stat_summary-project algo_public-DinputTableName=test_data-DoutputTableName=test_summary_out-DinputTablePartitions="ds='20160101'"-DselectColNames=col0,col1,col2-Dlifecycle=1
參數說明
| 參數名稱 | 參數描述 | 參數值可選項 | 默認值 |
|---|---|---|---|
| inputTableName | 必選,輸入表名 | - | - |
| outputTableName | 必選,推薦結果的輸出表名 | - | - |
| inputTablePartitions | 可選,輸入表的分區 | - | “” |
| selectColNames | 可選,指定需要統計的列名 | - | “” |
| lifecycle | 可選,輸出結果表的生命周期 | - | 不設生命周期 |
| coreNum | 可選,指定instance的總數 | - | -1 |
| memSizePerCore | 可選,指定memory大小,範圍在100~64*1024之間 | - | -1 |
輸入格式:選擇輸入列框中可選擇需要進行統計的列,默認情況下統計全部列
輸出格式:輸出統計結果的全部字段如下
| 列名 |
|---|
| colname |
| datatype |
| totalcount |
| count |
| missingcount |
| nancount |
| positiveinfinitycount |
| negativeinfinitycount |
| min |
| max |
| mean |
| variance |
| standarddeviation |
| standarderror |
| skewness |
| kurtosis |
| moment2 |
| moment3 |
| moment4 |
| centralmoment2 |
| centralmoment3 |
| centralmoment4 |
| sum |
| sum2 |
| sum3 |
| sum4 |
實例
測試數據
新建數據SQL
drop table if exists summary_test_input;create table summary_test_input asselect*from(select 'a' as col1, 1 as col2, 0.001 as col3 from dualunion allselect 'b' as col1, 2 as col2, 100.01 as col3 from dual) tmp;
運行命令
PAI -name stat_summary-project algo_public-DinputTableName=summary_test_input-DoutputTableName=summary_test_input_out-DselectColNames=col1,col2,col3-Dlifecycle=1;
運行結果
| colname | datatype | totalcount | count | missingcount | nancount | positiveinfinitycount | negativeinfinitycount | min | max | mean | variance | standarddeviation | standarderror | skewness | kurtosis | moment2 | moment3 | moment4 | centralmoment2 | centralmoment3 | centralmoment4 | sum | sum2 | sum3 | sum4 || col1 | string | 2 | 2 | 0 | 0 | 0 | 0 | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL || col2 | bigint | 2 | 2 | 0 | 0 | 0 | 0 | 1 | 2 | 1.5 | 0.5 | 0.7071067811865476 | 0.5 | 0 | -2 | 2.5 | 4.5 | 8.5 | 0.25 | 0 | 0.0625 | 3 | 5 | 9 | 17 || col3 | double | 2 | 2 | 0 | 0 | 0 | 0 | 0.001 | 100.01 | 50.0055 | 5000.900040500001 | 70.71704207968544 | 50.00450000000001 | 2.327677906939552e-16 | -1.999999999999999 | 5001.000050500001 | 500150.0150005006 | 50020003.00020002 | 2500.45002025 | 2.91038304567337e-11 | 6252250.303768232 | 100.011 | 10002.000101 | 1000300.030001001 | 100040006.0004 |
皮爾森係數
對輸入表或分區的2列(必須為數值列),計算其pearson相關係數,結果存入輸出表。
使用說明
組件的僅兩個參數:輸入列1、輸入列2;將需要計算相關係數的兩列的列名填入即可;
運行後,組件右擊菜單—> 查看分析報告,如下
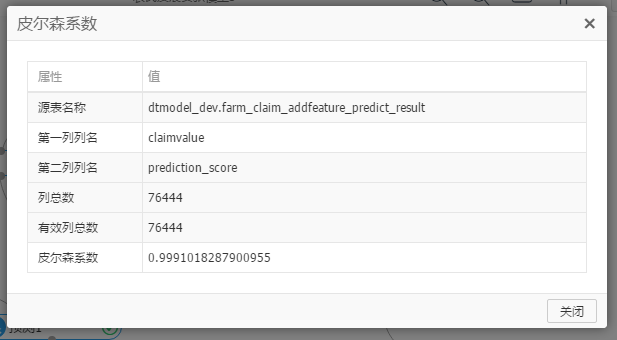 最後一列皮爾森係數值
最後一列皮爾森係數值
pai命令示例
pai -name pearson-project algo_test-DinputTableName=wpbc-Dcol1Name=f1-Dcol2Name=f2-DoutputTableName=wpbc_pear;
算法參數
| 參數key名稱 | 參數描述 | 取值範圍 | 是否必選,默認值/行為 |
|---|---|---|---|
| inputTableName | 輸入表的表名 | 表名 | 必選 |
| inputTablePartitions | 輸入表中指定哪些分區參與計算 | 格式為: partition_name=value。如果是多級格式為name1=value1/name2=value2;如果是指定多個分區,中間用’,’分開 | 輸入表的所有partition |
| col1Name | 輸入列1 | 列名 | 必選 |
| col2Name | 輸入列2 | 列名 | 必選 |
| outputTableName | 輸出結果表 | 表名 | 必選 |
直方圖
對一個存在的表,單列數據計算直方圖
參數設置
選擇需要分析字段,支持double類型和bigint類型
查看分析報告,如下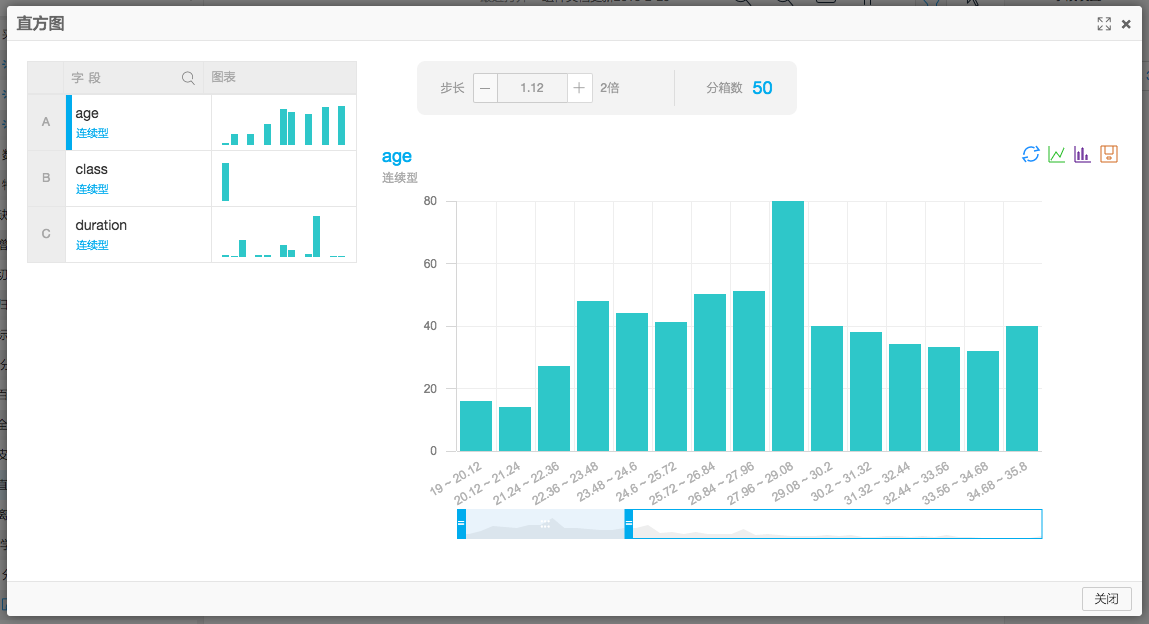 可調節步長大小,以及滑動查看直方圖
可調節步長大小,以及滑動查看直方圖
離散值特征分析
離散值特征分析統計離散特征的分布,gini,entropy,gini gain,infomation gain,infomation gain ratio等指標
其中計算每個離散值對應的gini,entropy
計算單列對應的gini gain,infomation gain,infomation gain ratio
gini index:
entropy:
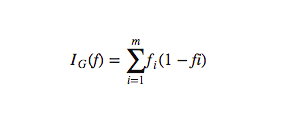
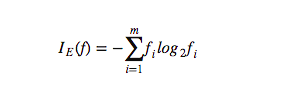
pai命令示例
PAI-name enum_feature_selection-project algo_public-DinputTableName=enumfeautreselection_input-DlabelColName=label-DfeatureColNames=col0,col1-DenableSparse=false-DoutputCntTableName=enumfeautreselection_output_cntTable-DoutputValueTableName=enumfeautreselection_output_valuetable-DoutputEnumValueTableName=enumfeautreselection_output_enumvaluetable;
算法參數
| 參數key名稱 | 參數描述 | 取值範圍 | 默認值 |
|---|---|---|---|
| inputTableName | 必選,輸入表名 | - | - |
| inputTablePartitions | 可選,輸入表選擇的分區 | - | 默認選擇全表 |
| featureColNames | 可選,輸入表選擇的列名 | - | 默認選擇除label外的其他列,如果輸入表為KV格式,則默認選擇所有的string類型的列 |
| labelColName | 必選,label所在的列 | - | - |
| enableSparse | 可選,輸入表是否是KV格式 | - | 默認為表 |
| kvFeatureColNames | 可選,KV格式的特征 | - | 默認選擇全表 |
| kvDelimiter | 可選,KV之間的分隔符 | - | 默認為: |
| itemDelimiter | 可選,K和V的分隔符 | - | 默認為, |
| outputCntTableName | 必選,輸出離散特征的枚舉值分布數表 | - | - |
| outputValueTableName | 必選,輸出離散特征的gini,entropy表 | - | - |
| outputEnumValueTableName | 必選,輸出離散特征枚舉值gini,entropy表 | - | - |
| lifecycle | 可選,輸入表的聲明周期 | - | 默認不設置聲明周期 |
| coreNum | 可選,總得core個數 | - | 默認自動設置 |
| memSizePerCore | 可選,單個core對應的內存數量,單位為M | - | 默認為自動設置 |
示例
測試數據
新建數據SQL
drop table if exists enum_feature_selection_test_input;create table enum_feature_selection_test_inputasselect*from(select'00' as col_string,1 as col_bigint,0.0 as col_doublefrom dualunion allselectcast(null as string) as col_string,0 as col_bigint,0.0 as col_doublefrom dualunion allselect'01' as col_string,0 as col_bigint,1.0 as col_doublefrom dualunion allselect'01' as col_string,1 as col_bigint,cast(null as double) as col_doublefrom dualunion allselect'01' as col_string,1 as col_bigint,1.0 as col_doublefrom dualunion allselect'00' as col_string,0 as col_bigint,0.0 as col_doublefrom dual) tmp;
輸入數據說明
+------------+------------+------------+| col_string | col_bigint | col_double |+------------+------------+------------+| 01 | 1 | 1.0 || 01 | 0 | 1.0 || 01 | 1 | NULL || NULL | 0 | 0.0 || 00 | 1 | 0.0 || 00 | 0 | 0.0 |+------------+------------+------------+
運行命令
drop table if exists enum_feature_selection_test_input_enum_value_output;drop table if exists enum_feature_selection_test_input_cnt_output;drop table if exists enum_feature_selection_test_input_value_output;PAI -name enum_feature_selection -project algo_public -DitemDelimiter=":" -Dlifecycle="28" -DoutputValueTableName="enum_feature_selection_test_input_value_output" -DkvDelimiter="," -DlabelColName="col_bigint" -DfeatureColNames="col_double,col_string" -DoutputEnumValueTableName="enum_feature_selection_test_input_enum_value_output" -DenableSparse="false" -DinputTableName="enum_feature_selection_test_input" -DoutputCntTableName="enum_feature_selection_test_input_cnt_output";
界麵
參數界麵
界麵運行結果
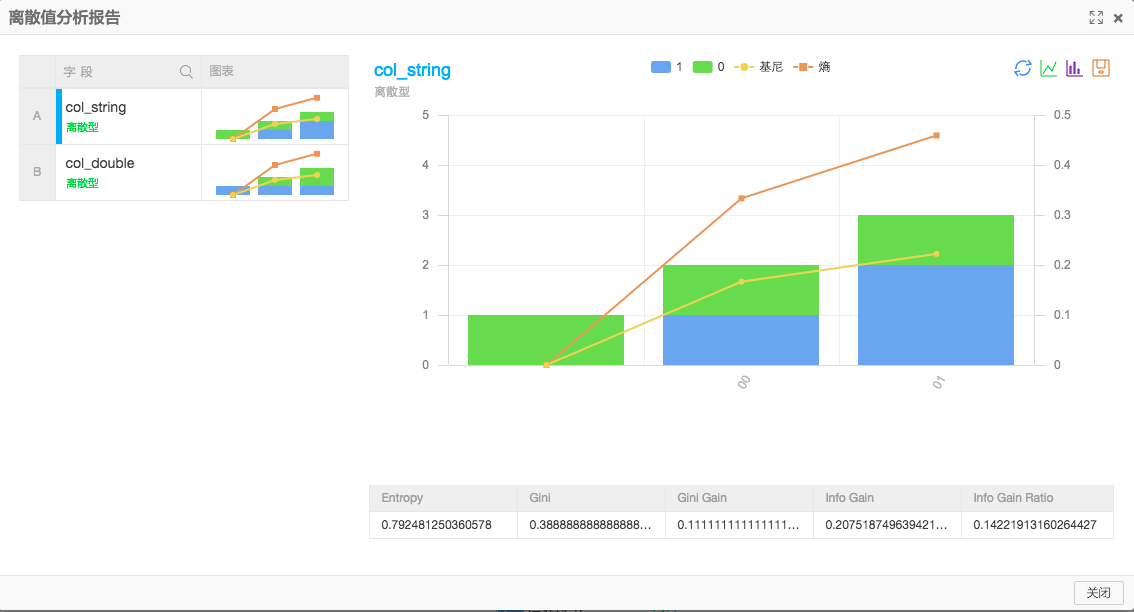
運行結果
enum_feature_selection_test_input_cnt_output
+------------+------------+------------+------------+| colname | colvalue | labelvalue | cnt |+------------+------------+------------+------------+| col_double | NULL | 1 | 1 || col_double | 0 | 0 | 2 || col_double | 0 | 1 | 1 || col_double | 1 | 0 | 1 || col_double | 1 | 1 | 1 || col_string | NULL | 0 | 1 || col_string | 00 | 0 | 1 || col_string | 00 | 1 | 1 || col_string | 01 | 0 | 1 || col_string | 01 | 1 | 2 |+------------+------------+------------+------------+
enum_feature_selection_test_input_value_output
+------------+------------+------------+------------+------------+---------------+| colname | gini | entropy | infogain | ginigain | infogainratio |+------------+------------+------------+------------+------------+---------------+| col_double | 0.3888888888888889 | 0.792481250360578 | 0.20751874963942196 | 0.1111111111111111 | 0.14221913160264427 || col_string | 0.38888888888888884 | 0.792481250360578 | 0.20751874963942196 | 0.11111111111111116 | 0.14221913160264427 |+------------+------------+------------+------------+------------+---------------+
enum_feature_selection_test_input_enum_value_output
+------------+------------+------------+------------+| colname | colvalue | gini | entropy |+------------+------------+------------+------------+| col_double | NULL | 0.0 | 0.0 || col_double | 0 | 0.22222222222222224 | 0.4591479170272448 || col_double | 1 | 0.16666666666666666 | 0.3333333333333333 || col_string | NULL | 0.0 | 0.0 || col_string | 00 | 0.16666666666666666 | 0.3333333333333333 || col_string | 01 | 0.2222222222222222 | 0.4591479170272448 |+------------+------------+------------+------------+
T檢驗
單樣本T檢驗是檢驗某個變量的總體均值和某指定值之間是否存在顯著差異。T檢驗的前提是樣本總體服從正態分布。
pai命令示例
pai -name t_test -project algo_public-DxTableName=pai_t_test_all_type-DxColName=col1_double-DoutputTableName=pai_t_test_out-DxTablePartitions=ds=2010/dt=1-Dalternative=less-Dmu=47-DconfidenceLevel=0.95
算法參數
| 參數名稱 | 參數描述 | 取值範圍 | 是否必選,默認值/行為 |
|---|---|---|---|
| xTableName | 輸入表x | 表名 | 必選 |
| xColName | 需要做t檢驗的列 | 列名,隻能是double或者bigint | 必選 |
| outputTableName | 輸出表 | 不存在的表名 | 必選 |
| xTablePartitions | 輸入表x的分區列表 | 分區列表 | 可選, 默認值:”” |
| alternative | 對立假設 | two.sided, less, greater” | 可選, 默認值: two.sided |
| mu | 假設的均值 | double | 可選,默認值:0 |
| confidenceLevel | 置信度 | 0.8,0.9,0.95,0.99,0.995,0.999 | 可選,默認值:0.95 |
輸出說明
輸出是一個表,隻有一行一列,是json格式。
{"AlternativeHypthesis": "mean not equals to 0","ConfidenceInterval": "(44.72234194006504, 46.27765805993496)","ConfidenceLevel": 0.95,"alpha": 0.05,"df": 99,"mean": 45.5,"p": 0,"stdDeviation": 3.919647479510927,"t": 116.081867662439}
卡方檢驗
卡方擬合性檢驗是檢驗單個多項分類名義型變量各分類間的實際觀測次數與理論次數之間是否一致的問題,其零假設是觀測次數與理論次數之間無差異。
pai命令示例
PAI -name chisq_test-project algo_public-DinputTableName=pai_chisq_test_input-DcolName=f0-DprobConfig=0:0.3,1:0.7-DoutputTableName=pai_chisq_test_output0-DoutputDetailTableName=pai_chisq_test_output0_detail
算法參數
| 參數名稱 | 參數描述 | 取值範圍 | 是否必選,默認值/行為 |
|---|---|---|---|
| inputTableName | 輸入表 | 表名 | 必選 |
| colName | 需要做卡方檢驗的列 | 列名 | 必選 |
| outputTableName | 輸出表 | 不存在的表名 | 必選 |
| outputDetailTableName | 輸出detail表 | 不存在的表名 | 必選 |
| inputTablePartitions | 輸入表的分區列表 | 分區列表 | 可選, 默認值:”” |
| probConfig | 類別概率配置 | kv對,格式 類別:概率,類別:概率…所有概率和為1 | 可選, 默認為所有類別概率相等 |
示例
測試數據
create table pai_chisq_test_input asselect * from(select '1' as f0,'2' as f1 from dualunion allselect '1' as f0,'3' as f1 from dualunion allselect '1' as f0,'4' as f1 from dualunion allselect '0' as f0,'3' as f1 from dualunion allselect '0' as f0,'4' as f1 from dual)tmp;
pai命令
PAI -name chisq_test-project algo_public-DinputTableName=pai_chisq_test_input-DcolName=f0-DprobConfig=0:0.3,1:0.7-DoutputTableName=pai_chisq_test_output0-DoutputDetailTableName=pai_chisq_test_output0_detail
輸出說明
輸出表outputTableName,隻有一行一列,是json格式。
{"Chi-Square": {"comment": "皮爾遜卡方","df": 1,"p-value": 0.75,"value": 0.2380952380952381}}
輸出表outputDetailTableName,對應列:類別,觀察頻率(observed),期望頻率(expected),標準誤差(residuals = (observed-expected) / sqrt(expected) )

最後更新:2016-08-15 10:00:16
上一篇: 特征工程__使用手冊(new)_機器學習-阿裏雲
特征工程__使用手冊(new)_機器學習-阿裏雲
下一篇: 文本分析__使用手冊(new)_機器學習-阿裏雲
- 阿裏雲如何煉就“神龍”這個“新物種”?
- ALIYUN::MarketPlace::Order__資源列表_資源編排-阿裏雲
- 簡單路由-域名配置__服務發現和負載均衡_用戶指南_容器服務-阿裏雲
- Job(作業)__產品概念_產品簡介_數據集成-阿裏雲
- 查詢媒體工作流__媒體工作流接口_API使用手冊_視頻點播-阿裏雲
- 轉換函數__函數_SQL語法參考_雲數據庫 OceanBase-阿裏雲
- 阿裏雲的技術到底有多強?
- 新老版本API使用FAQ__圖片處理指南_對象存儲 OSS-阿裏雲
- GetGroup__組管理接口_RAM API文檔_訪問控製-阿裏雲
- GetCursor__日誌庫相關接口_API-Reference_日誌服務-阿裏雲
相關內容
- 常見錯誤說明__附錄_大數據計算服務-阿裏雲
- 發送短信接口__API使用手冊_短信服務-阿裏雲
- 接口文檔__Android_安全組件教程_移動安全-阿裏雲
- 運營商錯誤碼(聯通)__常見問題_短信服務-阿裏雲
- 設置短信模板__使用手冊_短信服務-阿裏雲
- OSS 權限問題及排查__常見錯誤及排除_最佳實踐_對象存儲 OSS-阿裏雲
- 消息通知__操作指南_批量計算-阿裏雲
- 設備端快速接入(MQTT)__快速開始_阿裏雲物聯網套件-阿裏雲
- 查詢API調用流量數據__API管理相關接口_API_API 網關-阿裏雲
- 使用STS訪問__JavaScript-SDK_SDK 參考_對象存儲 OSS-阿裏雲