![]() 188
188
![]()
![]() windows
windows
數據格式規範__數據規範_開發者指南_推薦引擎-阿裏雲
推薦引擎的基礎數據模型如下:
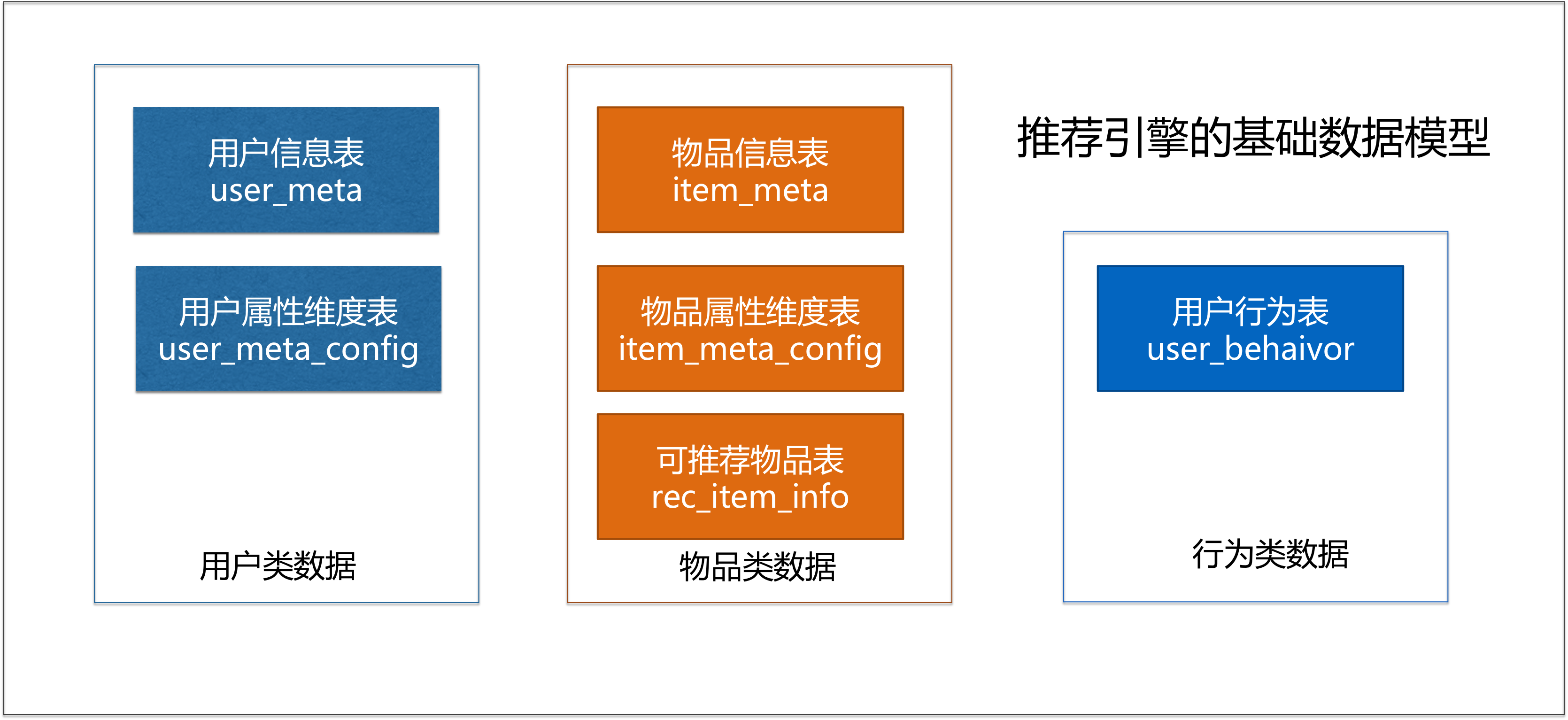
該數據模型總共包括了六張表,這些表有以下特點:
- 在MaxCompute(原來ODPS)中需要自己手工創建這些表;
- 表名沒有固定要求,可以按照自己的習慣命名;
- 每張表的表結構必須符合推薦引擎的要求,列名、字段類型和分區格式需要和規範中保持一致(參考下麵的表結構說明);
- 每張表中填充的數據,必須符合推薦引擎的要求;
- 每張表中是否都有記錄取決於業務場景和業務數據現狀,其中以下幾張表中必須有數據:用戶信息表、物品信息表、用戶行為表;
- 對於業務數據中無法提供的字段可以填NULL;
- 每張表都必須是分區表,以’yyyyMMdd’格式的字符型字段ds作為分區字段;
除了行為表需要每日上傳外,其他meta表如果不發生變化可以不導,推薦引擎會自動獲取最近一個有數據的分區中的meta表數據進行算法計算。將數據導入不同分區時,請遵守下麵的規則:
- 用戶表(user_meta):每天可全量導入在一個固定分區(insert OVERWRITE TABLE user_meta PARTITION (ds=’20160501’}));
- 物品表(item_meta):每天可全量導入在一個固定分區(insert OVERWRITE TABLE item_meta PARTITION (ds=’20160501’}));
- 可推薦物品表(rec_item_info):每天全量導入在一個固定分區(insert OVERWRITE TABLE rec_item_info PARTITION (ds=’20160501’}));
- 行為表(user_behavior):每天增量導入在不同的分區(insert OVERWRITE TABLE user_behavior PARTITION (ds=yyyyMMdd’}));
- 推薦引擎在對數據進行離線計算時,會產生數據結果數據和中間數據。其中中間數據的數據量大小取決於所使用的離線流程中的算法複雜度。例如一個標準的協同過濾算法其中間表數據量可能是原始數據輸入表數據量的5到10倍。推薦引擎默認對中間數據保留一天。
用戶表(user_meta)
字段描述
| 列名 | 數據類型 | 注釋 | Nullable |
|---|---|---|---|
| user_id | string | 用戶ID,可以是AID,device id,淘寶ID等各種唯一標識用戶身份的ID。不能出現(�01-�03)特殊字符。以下user_id字段同此意 | 否 |
| tags | string | 標簽-標簽值kv串。不同tag之間用�02分隔,tag和value之間用�03分隔(方括號不保存在數據庫中,以下同)。[t1�03v1�02t2�03v2…] 比如用戶有兩個標簽年齡和性別,tag可以取age,gender;value 取對應的值,如18、1 詳見【注釋1】 |
是 |
分區描述
| 分區名 | 數據類型 | 注釋 | Nullable |
|---|---|---|---|
| ds | string | 日期分區 格式 ‘yyyyMMdd’ | 否 |
ODPS DDL示例
CREATE TABLE user_meta (user_id STRING,tags STRING)PARTITIONED BY (ds STRING);
ODPS SQL示例
INSERT OVERWRITE TABLE user_meta PARTITION (ds='20160101')SELECT 'u1' AS user_id, concat('age', '�03', '18') AS tagsFROM dual;
用戶屬性維度表 (user_meta_config)
字段描述
| 列名 | 數據類型 | 注釋 | Nullable |
|---|---|---|---|
| config_name | string | config_name值為user_meta 表tags中的key,每個key一條記錄 | 否 |
| config_value | string | config_value取值為mv_enum,kv_num,sv_enum,sv_num,分別代表多值枚舉型,KV數值型,單值枚舉型,單值數值型四種標簽取值類型。 | 否 |
ODPS DDL示例
CREATE TABLE user_meta_config (config_name STRING,config_value STRING);
ODPS SQL示例
INSERT OVERWRITE TABLE user_meta_configSELECT 'age' AS config_name, 'sv_enum' AS config_valueFROM dual;
物品表(item_meta)
字段描述
| 列名 | 數據類型 | 注釋 | Nullable |
|---|---|---|---|
| item_id | string | 物品ID,唯一標識 | 否 |
| category | string | 物品所屬類目,最好以ID的形式給出 | 是 |
| keywords | string | 關鍵詞串。關鍵詞可以有權重(需要歸一化到0-1之間),也可以沒有權重,沒有權重時所有詞的權重都是1。Keywords之間用�02分隔,keyword和score之間用�03分隔(如果score存在)[kw1�03s1�02kw2�03s2�02…] | 是,不過category,keywords,properties,description,bizinfo五者不能都為空 |
| description | string | 用於描述這個物品C的一段文本 | 是 |
| properties | string | 屬性-屬性值kv串。不同key之間用�02分隔,key和value之間用�03分隔。不同property的key最好以ID的形式給出【注釋1】[k1�03v1�02k2�03v2…] 比如電影作為item,那麼properties中的key可以是演員、風格、製片人等 |
是 |
| bizinfo | string | 物品的業務信息,KV格式。不同KV之間以�02分隔,key和value之間以�03分隔。可以留NULL。bizinfo和properties的區別在bizinfo不參與特征提取的計算 | 是 |
分區描述
| 分區名 | 數據類型 | 注釋 | Nullable |
|---|---|---|---|
| ds | string | 日期分區格式 ‘yyyyMMdd’ | 否 |
ODPS DDL示例
CREATE TABLE item_meta (item_id STRING,category STRING,keywords STRING,description STRING,properties STRING,bizinfo STRING)PARTITIONED BY (ds STRING);
ODPS SQL示例
INSERT OVERWRITE TABLE item_meta PARTITION (ds='20160101')SELECT 'i1' AS item_id, '16' AS category, concat('hello', '�02', 'word') AS keywords, '' AS description, NULL AS properties, NULL AS bizinfoFROM dual
物品屬性維度表 (item_meta_config)
字段描述
| 列名 | 數據類型 | 注釋 | Nullable |
|---|---|---|---|
| config_name | string | config_name值為item_meta表properties中的key,每個key一條記錄 | 否 |
| config_value | string | config_value取值為mv_enum,kv_num,sv_enum,sv_num,分別代表多值枚舉型,KV數值型,單值枚舉型,單值數值型四種標簽取值類型。多值用�04 隔開 | 否 |
ODPS DDL示例
CREATE TABLE item_meta_config (config_name STRING,config_value STRING);
ODPS SQL示例
INSERT OVERWRITE TABLE item_meta_configSELECT 'singer' AS config_name, 'sv_enum' AS config_valueFROM dual;
行為表(user_behavior)
字段描述
| 列名 | 數據類型 | 注釋 | Nullable |
|---|---|---|---|
| user_id | string | 用戶ID | 否 |
| item_id | string | 物品ID | 否 |
| bhv_type | string | 行為類型: view:物品曝光 click:用戶點擊物品 collect:用戶收藏了某個物品 uncollect:用戶取消收藏某個物品 search_click:用戶點擊搜索結果中的物品 comment:用戶對物品的評論 share: 分享 like:點讚 dislike:點衰 grade:評分 consume:消費 use:觀看視頻/聽音樂/閱讀 行為表記錄的用戶行為用於用戶偏好建模 |
否 |
| bhv_amt | double | 用戶對物品的評分、消費、觀看時長等。 | 否 |
| bhv_cnt | double | 行為次數,默認為1,消費可以埋購買件數 | 否 |
| bhv_datetime | datetime | 行為發生的時間,UTC格式。 | 否 |
| content | string | 用戶對物品的評價文本 | 是 |
| media_type | string | 如果bhv_type=share,該字段記錄分享到目標媒體。短信:sms,郵件:email,微博:sina_wb,微信好友:wechat_friend,微信朋友圈:wechat_circle,QQ空間:qq_zone,來往好友:laiwang_friend,來往動態:laiwang_circle | 是 |
| pos_type | string | 行為發生的位置類型,和下麵position字段聯合使用,有三種取值: ll:經緯度格式的位置信息 gh:geohash格式的位置信息 poi:poi格式的位置信息 |
是 |
| position | string | 行為發生的位置,根據pos_type有不同的取值格式: 如果pos_type=ll,position格式[longitude:latitude] 如果pos_type=gh,position格式[geohashcode] 如果pos_type=poi,position格式[poi_string] |
是 |
| env | string | JSON String { “IP”:””, “network”:””, “device”:”” } IP: IP地址。行為發生時用戶的IP地址。IPv4為點分十進製格式;IPv6為冒號分隔的標準6段格式(不使用IPv6嵌套IPv4的格式) network: 網絡製式。行為發生時用戶所使用的接入網絡,取值為solid,2G,3G,4G,WIFI。分別表示固網,2G,3G,4G和WIFI接入方式 device: 發生行為所使用的設備,包括mobile,pad,pc等,可添加 其他自定義環境變量也可以添加到JSON中 |
是 |
| trace_id | string | 返回的推薦列表用於跟蹤效果。如果對item_id 的行為不是來自推薦引導,則為NULL | 是 |
分區描述
| 分區名 | 數據類型 | 注釋 | Nullable |
|---|---|---|---|
| ds | string | 日期分區 | 否 |
ODPS DDL示例
CREATE TABLE user_behavior (user_id STRING,item_id STRING,bhv_type STRING,bhv_amt DOUBLE,bhv_cnt DOUBLE,bhv_datetime DATETIME,content STRING,media_type STRING,pos_type STRING,position STRING,env STRING,trace_id STRING)PARTITIONED BY (ds STRING);
ODPS SQL示例
INSERT OVERWRITE TABLE user_behavior PARTITION (ds='20160101')SELECT 'u1' AS user_id, 'i1' AS item_id, 'click' AS bhv_type, 0 AS bhv_amt, 1 AS bhv_cnt, getdate() AS bhv_datetime, NULL AS content, NULL AS media_type, 'll' AS pos_type, concat('74', '�02', '56') AS position, NULL AS env, NULL AS trace_idFROM dual;
可推薦物品表(rec_item_info)
字段描述
| 列名 | 數據類型 | 注釋 | Nullable |
|---|---|---|---|
| item_id | string | 物品ID,唯一標識。本表中的物品都是允許被推薦的物品 | 否 |
| item_info | string | 如果業務方希望RecEng在返回推薦物品時同時返回物品的其他信息,保存在這裏。RecEng不需要了解item_info的內部格式,原樣返回給業務方。 | 是 |
分區描述
| 分區名 | 數據類型 | 注釋 | Nullable |
|---|---|---|---|
| ds | string | 日期分區 | 否 |
ODPS DDL示例
CREATE TABLE rec_item_info (item_id STRING,item_info STRING)PARTITIONED BY (ds STRING);
ODPS SQL示例
INSERT OVERWRITE TABLE rec_item_info PARTITION (ds='20160101')SELECT 'i1', NULLFROM dual;
注釋1
特征的數值類型分為mv_enum,kv_num,sv_enum,sv_num,分別代表多值枚舉型,KV數值型,單值枚舉型,單值數值型四種標簽取值類型舉例:單值數值型,如信用,隻能取一個值,但這個值是不可枚舉的單值枚舉型,如性別,隻能取一個值,但這個值是可以枚舉的(男,女)KV數值型,如用戶的類目偏好,用戶對某幾個類目有偏好分,如3298:0.89,3456:0.98..這裏3298和3456是類目id,0.89和0.98是偏好分多值枚舉型,如用戶的標簽,美包控、準媽媽等可以枚舉,但是每個用戶可以取多個在特征串中,不同key之間用�02分隔,key和value之間用�03分隔,多值key的value之間用�04連接。以上述4個例子為例,如果把它們串起來,則形式為信用 �03 98�02性別 �03 男�02類目偏好 �03 3298 �04 0.89 �03 3456 �04 0.98�02標簽 �03 美包控 �03 準媽媽
注釋2
文中提到 �02 �03 等指的是ASCII碼為整型2,3的特殊字符,每種編程語言有不同的表示方法,ODPS SQL 及 JAVA可以直接使用 '�02'
最後更新:2016-11-23 16:04:08
上一篇: 實時修正算法開發手冊__算法規範_開發者指南_推薦引擎-阿裏雲
實時修正算法開發手冊__算法規範_開發者指南_推薦引擎-阿裏雲
下一篇: 日誌埋點規範__數據規範_開發者指南_推薦引擎-阿裏雲
- 獲取用戶 Region 信息__用戶管理相關接口_Open API_消息隊列 MQ-阿裏雲
- ALTER_DATABASE__數據定義語言_SQL語法參考_雲數據庫 OceanBase-阿裏雲
- 如何變更發票信息__發票問題_發票及合同_財務-阿裏雲
- 使用RAM授權__用戶訪問權限控製_用戶指南_文件存儲-阿裏雲
- EDAS 商業化服務條款__服務條款和價格說明_企業級分布式應用服務 EDAS-阿裏雲
- 步驟 2:創建Windows實例__快速入門(Windows)_雲服務器 ECS-阿裏雲
- 使用在線幫助__命令行結構和參數_用戶指南_命令行工具 CLI-阿裏雲
- 查詢 Topic 當前位點__Topic 相關接口_Open API_消息隊列 MQ-阿裏雲
- 批量修改解析記錄__批量管理接口_API文檔_雲解析-阿裏雲
- 發布曆史__產品介紹_雲數據庫 HybridDB-阿裏雲
相關內容
- 常見錯誤說明__附錄_大數據計算服務-阿裏雲
- 發送短信接口__API使用手冊_短信服務-阿裏雲
- 接口文檔__Android_安全組件教程_移動安全-阿裏雲
- 運營商錯誤碼(聯通)__常見問題_短信服務-阿裏雲
- 設置短信模板__使用手冊_短信服務-阿裏雲
- OSS 權限問題及排查__常見錯誤及排除_最佳實踐_對象存儲 OSS-阿裏雲
- 消息通知__操作指南_批量計算-阿裏雲
- 設備端快速接入(MQTT)__快速開始_阿裏雲物聯網套件-阿裏雲
- 查詢API調用流量數據__API管理相關接口_API_API 網關-阿裏雲
- 使用STS訪問__JavaScript-SDK_SDK 參考_對象存儲 OSS-阿裏雲