![]() 884
884
![]()
![]() 魔兽
魔兽
创建数据同步任务__快速开始_大数据开发套件-阿里云
【说明】目前数据同步任务支持的数据源类型包括:MaxCompute、RDS(MySQL、SQL Server、PostgreSQL)、Oracle、FTP、ADS、OSS、OCS、DRDS。

以RDS数据同步至MaxCompute为例,详细说明如下:
step1:创建数据表
创建MaxCompute表的详细操作详见 :创建表。
step2:新建数据源
【说明】新建数据源需项目管理员角色才能够创建。
准备工作
目前RDS数据源仅支持华东1(杭州)域的RDS,北京地域暂时不支持。另外当杭州地域的RDS也遇到数据源测试不连通的时候,需要到自己RDS上添加数据同步机器ip白名单:
10.152.69.0/24,10.153.136.0/24,10.143.32.0/24,120.27.160.26,10.46.67.156,120.27.160.81,10.46.64.81,121.43.110.160,10.117.39.238,121.43.112.137,10.117.28.203,118.178.84.74,10.27.63.41,118.178.56.228,10.27.63.60,118.178.59.233,10.27.63.38,118.178.142.154,10.27.63.15
具体操作如下:
step2.1:以开发者身份进入阿里云数加平台>大数据开发套件>管理控制台,点击对应项目操作栏中的进入工作区。
step2.2:点击顶部菜单栏中的项目管理,点击左侧导航数据源管理。
step2.3:点击新增数据源。
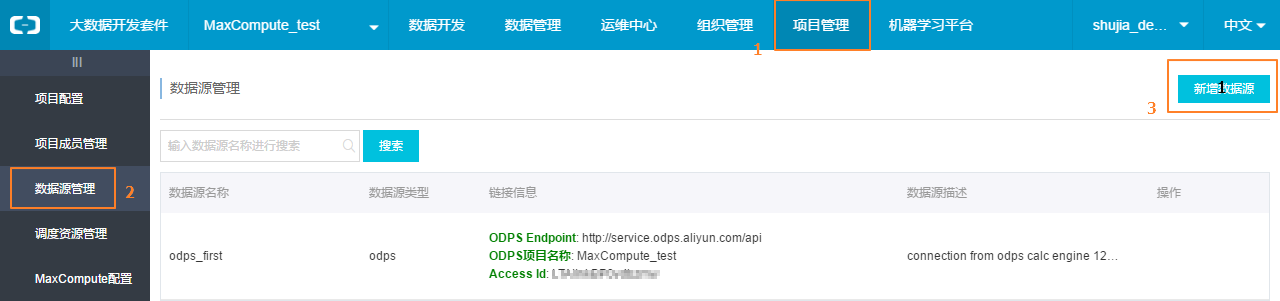
step2.4:在新增数据源弹出框中填写相关配置项。
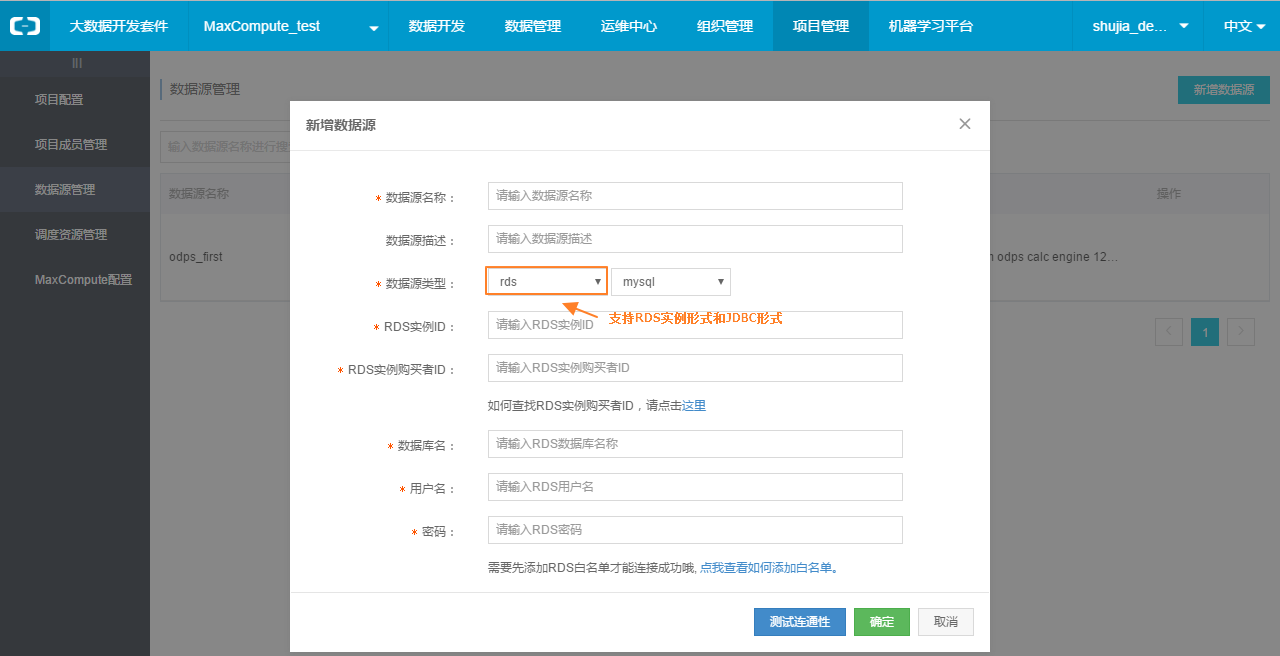
上图中的配置项具体说明如下:
- 数据源名称:由英文字母、数字、下划线组成且需以字符或下划线开头,长度不超过30个字符。
- 数据源描述:对数据源的简单描述,不超过1024个字符。
- 数据源类型:当前选择的数据源类型(RDS>MySQL>RDS实例形式)。
- RDS实例ID:该MySQL数据源的RDS实例ID。
- RDS实例购买者ID:该MySQL数据源的RDS实例购买者ID。
【备注】若选择JDBC形式来配置数据源,其JDBC连接信息,格式为:jdbc:mysql://IP:Port/database。
- 数据库名:该数据源对应的数据库名。
- 用户名/密码:数据库对应的用户名和密码。
step2.5:点击测试连通性。
step2.6:若测试连通性成功,则点击保存按钮完成配置信息保存。
关于其他类型(MaxCompute、RDS、Oracle、FTP、ADS、OSS、OCS、DRDS)数据源的配置,详见:数据源配置。
step3:新建任务
关于新建任务的详细说明与操作见:新建工作流。
step4:配置数据同步任务
您可向工作流设计器中拖入数据同步节点并双击进入数据同步节点配置界面,包括“选择数据来源和目标”、“选择要抽取的列,并映射到目标表字段”、“数据抽取和加载控制”和“流量与出错控制”四大配置项。
step4.1:选择数据来源和目标
选择数据源(数据源为已经建立好的数据源)后并且选择数据表。
显示建表DDL:点击将源头表的建表语句转化为符合ODPS SQL语法规范的DDL语句。
添加数据源:点击添加数据源跳转到项目管理>数据源管理页面。
【备注】若源头为Mysql数据源,则数据同步任务还支持分库分表模式的数据导入(前提是无论数据存储在同一数据库还是不同数据库,表结构必须是一致的)。
分库分表可支持如下场景:
同库多表:点击搜索表,添加需要同步的多张表即可。
分库多表:首先点击添加选择源库,再点击搜索表来添加表。如下图所示:
step4.2:字段配置
需对字段映射关系进行配置,左侧“源表字段”和右侧“宿表字段”为一一对应的关系。
批量编辑,可批量编辑源表或宿表字段,通过此方式添加的表字段类型默认为空。
增加/删除,点击”添加一行”可单个增加字段。鼠标Hover上每一行,点击删除图标可以删除当前字段。
【提示】自定义变量和常量的写入方法:如果需要把常量或者变量导入ODPS中表的某个字段,只需要点击插入按钮,然后输入常量或者变量的值,并且用英文单引号包起来即可,如变量‘${yesterday}’,然后再参数配置组件配置给变量赋值如yesterday=$[yyyymmdd]。具体时间参数详见系统调度参数 说明 。
step4.3:数据抽取和加载控制
数据抽取控制即数据抽取的过滤条件,而数据加载控制即数据写入时的规则。
抽取控制,可参考相应的SQL语法填写where过滤语句(不需要填写where关键字),该过滤条件将作为增量同步的条件。
【说明】where条件即针对源头数据筛选条件,根据指定的column、table、where条件拼接SQL进行数据抽取。利用where条件可进行全量同步和增量同步,具体说明如下:
1)全量同步:第一次做数据导入时通常为全量导入,可不用设置where条件;如只是在测试时,避免数据量过大,可将where条件指定为limit 10。
2)增量同步:增量导入在实际业务场景中,往往会选择当天的数据进行同步,通常需要编写where条件语句,请先确认表中描述增量字段(时间戳)为哪一个。如tableA描述增量的字段为creat_time,那么在where条件中编写creat_time>${yesterday},在参数配置中为其参数赋值即可。其中更多内置参数使用方法,请参照“系统调度参数 ”章节。
分区信息:分区是为了便于查询部分数据引入的特殊列,指定分区便于快速定位到需要的数据。支持常量和变量。
- 清理规则:
1)写入前清理已有数据:导数据之前,清空表或者分区的所有数据,相当于insert overwrite。
2)写入前保留已有数据:导数据之前不清理任何数据,每次运行数据都是追加进去的,相当于insert into。
step4.3:流量与出错控制
流量与出错控制用来配置作业速率上限和脏数据检查规则:
- 作业速率上限,即配置当前数据同步任务速率,支持最大为10MB/s(通道流量度量值是数据同步任务本身的度量值,不代表实际网卡流量)。
若数据同步任务是RDS/OracleODPS,在该页面中会有切分键配置。
- 切分键:只支持类型为整型的字段。读取数据时,根据配置的字段进行数据分片,实现并发读取,可提升数据同步效率。只有同步任务是RDS/Oracle数据导入至ODPS时,才显示切分键配置项。
以下为脏数据检查规则(写入RDS、Oracle时可用 ),可配置一个或两个,两个规则之间为或的关系:
- 当出错纪录数超过,当脏数据数量(即错误记录数)超过所配置的个数时,该数据同步任务结束。
- 错误百分比达到,当脏数据数量(即错误记录数)超过所配置的百分比时,该数据同步任务结束。
最后更新:2016-12-19 19:37:51
上一篇: 创建任务(以MaxCompute SQL任务为例)__快速开始_大数据开发套件-阿里云
创建任务(以MaxCompute SQL任务为例)__快速开始_大数据开发套件-阿里云
下一篇: 创建自定义函数__快速开始_大数据开发套件-阿里云
- 人脸技术服务简介__人脸技术服务_人工智能图像类-阿里云
- 在线安装命令行工具和 SDK__安装命令行工具(Windows)_用户指南_命令行工具 CLI-阿里云
- 浏览作业__作业管理_Console参考手册_数据集成-阿里云
- 步骤 3:登录Linux实例__快速入门(Linux)_云服务器 ECS-阿里云
- 简单下载示例__SDK示例_批量数据通道_大数据计算服务-阿里云
- 修改产品信息__接口列表_服务器端API_阿里云物联网套件-阿里云
- 天粒度资源使用概览__资源监控接口_API 手册_CDN-阿里云
- HTTPS 双向认证常见问题__常见问题_负载均衡-阿里云
- 常用管理函数__快速入门(PPAS)_云数据库 RDS 版-阿里云
- KMS地域分布__API 参考_密钥管理服务-阿里云
相关内容
- 常见错误说明__附录_大数据计算服务-阿里云
- 发送短信接口__API使用手册_短信服务-阿里云
- 接口文档__Android_安全组件教程_移动安全-阿里云
- 运营商错误码(联通)__常见问题_短信服务-阿里云
- 设置短信模板__使用手册_短信服务-阿里云
- OSS 权限问题及排查__常见错误及排除_最佳实践_对象存储 OSS-阿里云
- 消息通知__操作指南_批量计算-阿里云
- 设备端快速接入(MQTT)__快速开始_阿里云物联网套件-阿里云
- 查询API调用流量数据__API管理相关接口_API_API 网关-阿里云
- 使用STS访问__JavaScript-SDK_SDK 参考_对象存储 OSS-阿里云