![]() 174
174
![]()
![]() 同花顺
同花顺
Python快速开始__快速入门_批量计算-阿里云
本文档将介绍如何使用 Python 版 SDK 来提交一个作业,目的是统计一个日志文件中“INFO”,”WARN”,”ERROR”,”DEBUG”出现的次数。
如果您还没开通批量计算服务,请先开通。
步骤预览
- 作业准备
- 上传数据文件到OSS
- 上传任务程序到OSS
- 使用SDK创建(提交)作业
- 查看结果
1. 作业准备
本作业是统计一个日志文件中“INFO”,”WARN”,”ERROR”,”DEBUG”出现的次数。
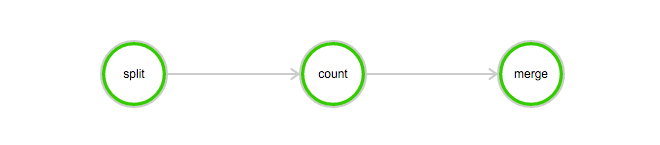
该作业包含3个任务: split, count 和 merge:
- split 任务会把日志文件分成 3 份。
- count 任务会统计每份日志文件中“INFO”,”WARN”,”ERROR”,”DEBUG”出现的次数 (count 任务需要配置InstanceCount为3,表示同时启动3台机器运行个 count 程序)。
- merge 任务会把 count 任务的结果统一合并起来。
DAG图例:
(1) 上传数据文件到OSS
下载本例子所需的数据: log-count-data.txt
将 log-count-data.txt 上传到:
oss://your-bucket/log-count/log-count-data.txt
- your-bucket如表示您自己创建的bucket,本例子假设region为: cn-shenzhen.
- 如何上传到OSS,请参考OSS上传文档。
(2) 上传任务程序到OSS
本例子的作业程序是使用python编写的, 下载本例子所需的程序: log-count.tar.gz
本例子不需要改动示例代码。直接将 log-count.tar.gz 上传到 oss,如上传到:
oss://your-bucket/log-count/log-count.tar.gz。
如何上传前面已经讲过。
- BatchCompute 只支持以 tar.gz 为后缀的压缩包, 请注意务必用以上方式(gzip)打包, 否则将会无法解析。
如果你要修改代码,可以解压后修改,然后要用下面的方法打包:
命令如下:
> cd log-count #进入目录> tar -czf log-count.tar.gz * #打包,将所有这个目录下的文件打包到 log-count.tar.gz
可以运行这条命令查看压缩包内容:
$ tar -tvf log-count.tar.gz
可以看到以下列表:
conf.pycount.pymerge.pysplit.py
2. 使用SDK创建(提交)作业
python SDK 的相关下载与安装请参阅这里。
v20151111版本,提交作业需要指定集群ID或者使用匿名集群参数。本例子使用匿名集群方式进行。匿名集群需要配置2个参数, 其中:
在 OSS 中创建存储StdoutRedirectPath(程序输出结果)和StderrRedirectPath(错误日志)的文件路径,本例中创建的路径为
oss://your-bucket/log-count/logs/
- 如需运行本例子,请按照上文所述的变量获取以及与上文对应的您的OSS路径对程序中注释中的变量进行修改。
Python SDK 提交程序模板如下,程序中具体参数含义请参照这里。
#encoding=utf-8import sysfrom batchcompute import Client, ClientErrorfrom batchcompute import CN_SHENZHEN as REGIONfrom batchcompute.resources import (JobDescription, TaskDescription, DAG, AutoCluster)ACCESS_KEY_ID='' # 填写你的AKACCESS_KEY_SECRET='' # 填写你的AKIMAGE_ID = 'img-ubuntu' #这里填写您的镜像IDINSTANCE_TYPE = 'ecs.s3.large' # 根据实际region支持的InstanceType 填写WORKER_PATH = '' # 'oss://your-bucket/log-count/log-count.tar.gz' 这里填写您上传的log-count.tar.gz的OSS存储路径LOG_PATH = '' # 'oss://your-bucket/log-count/logs/' 这里填写您创建的错误反馈和task输出的OSS存储路径OSS_MOUNT= '' # 'oss://your-bucket/log-count/' 同时挂载到/home/inputs 和 /home/outputsclient = Client(REGION, ACCESS_KEY_ID, ACCESS_KEY_SECRET)def main():try:job_desc = JobDescription()# Create auto cluster.cluster = AutoCluster()cluster.InstanceType = INSTANCE_TYPEcluster.ResourceType = "OnDemand"cluster.ImageId = IMAGE_ID# Create split task.split_task = TaskDescription()split_task.Parameters.Command.CommandLine = "python split.py"split_task.Parameters.Command.PackagePath = WORKER_PATHsplit_task.Parameters.StdoutRedirectPath = LOG_PATHsplit_task.Parameters.StderrRedirectPath = LOG_PATHsplit_task.InstanceCount = 1split_task.AutoCluster = clustersplit_task.InputMapping[OSS_MOUNT]='/home/input'split_task.OutputMapping['/home/output'] = OSS_MOUNT# Create map task.count_task = TaskDescription(split_task)count_task.Parameters.Command.CommandLine = "python count.py"count_task.InstanceCount = 3count_task.InputMapping[OSS_MOUNT] = '/home/input'count_task.OutputMapping['/home/output'] = OSS_MOUNT# Create merge taskmerge_task = TaskDescription(split_task)merge_task.Parameters.Command.CommandLine = "python merge.py"merge_task.InstanceCount = 1merge_task.InputMapping[OSS_MOUNT] = '/home/input'merge_task.OutputMapping['/home/output'] = OSS_MOUNT# Create task dag.task_dag = DAG()task_dag.add_task(task_name="split", task=split_task)task_dag.add_task(task_name="count", task=count_task)task_dag.add_task(task_name="merge", task=merge_task)task_dag.Dependencies = {'split': ['count'],'count': ['merge']}# Create job description.job_desc.DAG = task_dagjob_desc.Priority = 99 # 0-1000job_desc.Name = "log-count"job_desc.Description = "PythonSDKDemo"job_desc.JobFailOnInstanceFail = Truejob_id = client.create_job(job_desc).Idprint('job created: %s' % job_id)print('waiting for job finished ...')# Wait for job finished.errs = client.poll(job_id)if errs:print ("Some errors occur: %s" % 'n'.join(errs))return 1else:print ("Success!")return 0except ClientError, e:print (e.get_status_code(), e.get_code(), e.get_requestid(), e.get_msg())if __name__ == '__main__':sys.exit(main())
3. 查看结果
您可以登录OSS控制台 查看your-bucket 这个bucket下面的这个文件:/log-count/merge_result.json。
内容应该如下:
{"INFO": 2460, "WARN": 2448, "DEBUG": 2509, "ERROR": 2583}
最后更新:2016-11-23 17:16:09
上一篇: Java快速开始__快速入门_批量计算-阿里云
Java快速开始__快速入门_批量计算-阿里云
下一篇: 如何提交作业__操作指南_批量计算-阿里云
- 安装步骤__快速开始_Eclipse 插件-阿里云
- 名词解释及说明__产品简介_移动推送-阿里云
- Java SDK实例程序__最佳实践_归档存储-阿里云
- GetAccountAlias__安全设置接口_RAM API文档_访问控制-阿里云
- 使用 psql 命令迁移 PostgreSQL 数据__快速入门(PostgreSQL)_云数据库 RDS 版-阿里云
- 设备新增与留存__查询相关_API 列表_OpenAPI 2.0_移动推送-阿里云
- 通过镜像创建 Nginx__快速入门_容器服务-阿里云
- 问题解答__常见问题_Eclipse 插件-阿里云
- RDS for MySQL 如何定位本地 IP___常见问题_云数据库 RDS 版-阿里云
- 产品与技术__产品简介_数据集成-阿里云
相关内容
- 常见错误说明__附录_大数据计算服务-阿里云
- 发送短信接口__API使用手册_短信服务-阿里云
- 接口文档__Android_安全组件教程_移动安全-阿里云
- 运营商错误码(联通)__常见问题_短信服务-阿里云
- 设置短信模板__使用手册_短信服务-阿里云
- OSS 权限问题及排查__常见错误及排除_最佳实践_对象存储 OSS-阿里云
- 消息通知__操作指南_批量计算-阿里云
- 设备端快速接入(MQTT)__快速开始_阿里云物联网套件-阿里云
- 查询API调用流量数据__API管理相关接口_API_API 网关-阿里云
- 使用STS访问__JavaScript-SDK_SDK 参考_对象存储 OSS-阿里云