![]() 822
822
![]()
![]() 同花顺
同花顺
Java快速开始__快速入门_批量计算-阿里云
Java快速开始例子
本文档将介绍如何使用 Java 版 SDK 来提交一个作业,目的是统计一个日志文件中“INFO”,”WARN”,”ERROR”,”DEBUG”出现的次数。
如果您还没开通批量计算服务,请先开通。
步骤预览
- 作业准备
- 上传数据文件到OSS
- 使用示例代码
- 编译打包
- 上传到OSS
- 使用SDK创建(提交)作业
- 查看结果
1. 作业准备
本作业是统计一个日志文件中“INFO”,”WARN”,”ERROR”,”DEBUG”出现的次数。
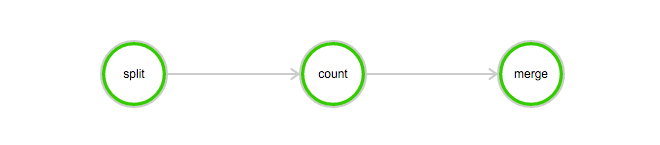
该作业包含3个任务: split, count 和 merge:
- split 任务会把日志文件分成 3 份。
- count 任务会统计每份日志文件中“INFO”,”WARN”,”ERROR”,”DEBUG”出现的次数 (count 任务需要配置InstanceCount为3,表示同时启动3台机器运行个 count 程序)。
- merge 任务会把 count 任务的结果统一合并起来。
DAG图例:
(1) 上传数据文件到OSS
下载本例子所需的数据: log-count-data.txt
将 log-count-data.txt 上传到:
oss://your-bucket/log-count/log-count-data.txt
- your-bucket如表示您自己创建的bucket,本例子假设region为: cn-shenzhen.
- 如何上传到OSS,请参考OSS上传文档。
(2) 使用示例代码
这里我们将采用Java来编写作业任务,使用maven来编译,推荐使用IDEA:https://www.jetbrains.com/idea/download/ 选择Community版本(免费).
示例程序下载:java-log-count.zip
这是一个maven工程。
- 注意:无需修改代码。
(3) 编译打包
运行命令编译打包:
mvn package
即可在target得到下面3个jar包:
batchcompute-job-log-count-1.0-SNAPSHOT-Split.jarbatchcompute-job-log-count-1.0-SNAPSHOT-Count.jarbatchcompute-job-log-count-1.0-SNAPSHOT-Merge.jar
再将3个jar包,打成一个tar.gz压缩包,命令如下:
> cd target #进入target目录> tar -czf worker.tar.gz *SNAPSHOT-*.jar #打包
运行以下命令,查看包的内容是否正确:
> tar -tvf worker.tar.gzbatchcompute-job-log-count-1.0-SNAPSHOT-Split.jarbatchcompute-job-log-count-1.0-SNAPSHOT-Count.jarbatchcompute-job-log-count-1.0-SNAPSHOT-Merge.jar
- 注意:BatchCompute 只支持以 tar.gz 为后缀的压缩包, 请注意务必用以上方式(gzip)打包, 否则将会无法解析。
(4) 上传到OSS
本例将 worke.tar.gz 上传到 OSS 的 your-bucket 中:
oss://your-bucket/log-count/worker.tar.gz
- 如要运行本例子,您需要创建自己的bucket,并且把worker.tar.gz文件上传至您自己创建的bucket的路径下。
2. 使用SDK创建(提交)作业
(1) 新建一个maven工程
在pom.xml中增加以下dependencies:
<dependencies><dependency><groupId>com.aliyun</groupId><artifactId>aliyun-java-sdk-batchcompute</artifactId><version>3.1.0</version></dependency><dependency><groupId>com.aliyun</groupId><artifactId>aliyun-java-sdk-core</artifactId><version>3.0.3</version></dependency></dependencies>
(2) 新建一个java类: Demo.java
提交作业需要指定集群ID或者使用匿名集群参数。本例子使用匿名集群方式进行。匿名集群需要配置2个参数, 其中:
在 OSS 中创建存储StdoutRedirectPath(程序输出结果)和StderrRedirectPath(错误日志)的文件路径,本例中创建的路径为
oss://your-bucket/log-count/logs/
- 如需运行本例子,请按照上文所述的变量获取以及与上文对应的您的OSS路径对程序中注释中的变量进行修改。
Java SDK 提交程序模板如下,程序中具体参数含义请参照 SDK接口说明。
Demo.java:
/** IMAGE_ID:ECS镜像,由上文所述获取* INSTANCE_TYPE: 实例类型,由上文所述获取* REGION_ID:区域为青岛/杭州,目前只有青岛开通,此项需与上文OSS存储worker的bucket地域一致* ACCESS_KEY_ID: AccessKeyId可以由上文所述获取* ACCESS_KEY_SECRET: AccessKeySecret可以由上文所述获取* WORKER_PATH:由上文所述打包上传的worker的OSS存储路径* LOG_PATH:错误反馈和task输出的存储路径,logs文件需事先自行创建*/import com.aliyuncs.batchcompute.main.v20151111.*;import com.aliyuncs.batchcompute.model.v20151111.*;import com.aliyuncs.batchcompute.pojo.v20151111.*;import com.aliyuncs.exceptions.ClientException;import java.util.ArrayList;import java.util.List;public class Demo {static String IMAGE_ID = "img-ubuntu";; //这里填写您的 ECS 镜像IDstatic String INSTANCE_TYPE = "bcs.a2.large"; //根据region填写合适的InstanceTypestatic String REGION_ID = "cn-shenzhen"; //这里填写regionstatic String ACCESS_KEY_ID = ""; //"your-AccessKeyId"; 这里填写您的AccessKeyIdstatic String ACCESS_KEY_SECRET = ""; //"your-AccessKeySecret"; 这里填写您的AccessKeySecretstatic String WORKER_PATH = ""; //"oss://your-bucket/log-count/worker.tar.gz"; // 这里填写您上传的worker.tar.gz的OSS存储路径static String LOG_PATH = ""; // "oss://your-bucket/log-count/logs/"; // 这里填写您创建的错误反馈和task输出的OSS存储路径static String MOUNT_PATH = ""; // "oss://your-bucket/log-count/";public static void main(String[] args){/** 构造 BatchCompute 客户端 */BatchCompute client = new BatchComputeClient(REGION_ID, ACCESS_KEY_ID, ACCESS_KEY_SECRET);try{/** 构造 Job 对象 */JobDescription jobDescription = genJobDescription();//创建JobCreateJobResponse response = client.createJob(jobDescription);//创建成功后,返回jobIdString jobId = response.getJobId();System.out.println("Job created success, got jobId: "+jobId);//查询job状态GetJobResponse getJobResponse = client.getJob(jobId);Job job = getJobResponse.getJob();System.out.println("Job state:"+job.getState());} catch (ClientException e) {e.printStackTrace();System.out.println("Job created failed, errorCode:"+ e.getErrCode()+", errorMessage:"+e.getErrMsg());}}private static JobDescription genJobDescription(){JobDescription jobDescription = new JobDescription();jobDescription.setName("java-log-count");jobDescription.setPriority(0);jobDescription.setDescription("log-count demo");jobDescription.setJobFailOnInstanceFail(true);jobDescription.setType("DAG");DAG taskDag = new DAG();/** 添加 split task */TaskDescription splitTask = genTaskDescription();splitTask.setTaskName("split");splitTask.setInstanceCount(1);splitTask.getParameters().getCommand().setCommandLine("java -jar batchcompute-job-log-count-1.0-SNAPSHOT-Split.jar");taskDag.addTask(splitTask);/** 添加 count task */TaskDescription countTask = genTaskDescription();countTask.setTaskName("count");countTask.setInstanceCount(3);countTask.getParameters().getCommand().setCommandLine("java -jar batchcompute-job-log-count-1.0-SNAPSHOT-Count.jar");taskDag.addTask(countTask);/** 添加 merge task */TaskDescription mergeTask = genTaskDescription();mergeTask.setTaskName("merge");mergeTask.setInstanceCount(1);mergeTask.getParameters().getCommand().setCommandLine("java -jar batchcompute-job-log-count-1.0-SNAPSHOT-Merge.jar");taskDag.addTask(mergeTask);/** 添加Task依赖: split-->count-->merge */List<String> taskNameTargets = new ArrayList();taskNameTargets.add("merge");taskDag.addDependencies("count", taskNameTargets);List<String> taskNameTargets2 = new ArrayList();taskNameTargets2.add("count");taskDag.addDependencies("split", taskNameTargets2);//dagjobDescription.setDag(taskDag);return jobDescription;}private static TaskDescription genTaskDescription(){AutoCluster autoCluster = new AutoCluster();autoCluster.setInstanceType(INSTANCE_TYPE);autoCluster.setImageId(IMAGE_ID);//autoCluster.setResourceType("OnDemand");TaskDescription task = new TaskDescription();//task.setTaskName("Find");//打包上传的作业的OSS全路径Parameters p = new Parameters();Command cmd = new Command();//cmd.setCommandLine("");//打包上传的作业的OSS全路径cmd.setPackagePath(WORKER_PATH);p.setCommand(cmd);//错误反馈存储路径p.setStderrRedirectPath(LOG_PATH);//最终结果输出存储路p.setStdoutRedirectPath(LOG_PATH);task.setParameters(p);task.addInputMapping(MOUNT_PATH, "/home/input");task.addOutputMapping("/home/output",MOUNT_PATH);task.setAutoCluster(autoCluster);//task.setClusterId(clusterId);task.setTimeout(30000); /* 30000 秒*/task.setInstanceCount(1); /** 使用1个实例来运行 */return task;}}
正常输出样例:
Job created success, got jobId: job-01010100010192397211Job state:Waiting
3. 查看结果
您可以登录batchcompute控制台查看job状态。
Job运行结束,您可以登录OSS控制台 查看your-bucket 这个bucket下面的这个文件:/log-count/merge_result.json。
内容应该如下:
{"INFO": 2460, "WARN": 2448, "DEBUG": 2509, "ERROR": 2583}
最后更新:2016-12-05 17:29:54
上一篇: 命令行快速开始2__快速入门_批量计算-阿里云
命令行快速开始2__快速入门_批量计算-阿里云
下一篇: Python快速开始__快速入门_批量计算-阿里云
- 经典网络专线接入__使用金融云产品_金融云-阿里云
- 产品规则__产品简介_邮件推送-阿里云
- 查询堆栈信息__堆栈相关接口_API 文档_资源编排-阿里云
- MQ 快速入门__视频教程_消息队列 MQ-阿里云
- 设备注册__接口列表_服务器端API_阿里云物联网套件-阿里云
- 编辑账号信息__账号管理类 API_Open API 参考_企业级分布式应用服务 EDAS-阿里云
- 获取所有发布信息__发布管理相关接口_Open API_消息队列 MQ-阿里云
- 应用管理类__应用操作接口_API参考手册_开放搜索-阿里云
- Open API 简介__Open API 参考_企业级分布式应用服务 EDAS-阿里云
- 恢复直播流推送__直播流操作接口_API 手册_CDN-阿里云
相关内容
- 常见错误说明__附录_大数据计算服务-阿里云
- 发送短信接口__API使用手册_短信服务-阿里云
- 接口文档__Android_安全组件教程_移动安全-阿里云
- 运营商错误码(联通)__常见问题_短信服务-阿里云
- 设置短信模板__使用手册_短信服务-阿里云
- OSS 权限问题及排查__常见错误及排除_最佳实践_对象存储 OSS-阿里云
- 消息通知__操作指南_批量计算-阿里云
- 设备端快速接入(MQTT)__快速开始_阿里云物联网套件-阿里云
- 查询API调用流量数据__API管理相关接口_API_API 网关-阿里云
- 使用STS访问__JavaScript-SDK_SDK 参考_对象存储 OSS-阿里云