![]() 714
714
![]()
![]() 阿裏雲
阿裏雲
人口普查統計案例__案例_機器學習-阿裏雲
一、背景
感謝大家關注玩轉數據係列文章,我們希望通過在阿裏雲機器學習平台上提供demo數據並搭建相關的實驗流程的方式來幫助大家學習如何通過算法來挖掘數據中的價值。本係列文章包含詳細的實驗流程以及相關的文檔教程,歡迎大家進入阿裏雲數加機器學習平台體驗。實驗案例請在新建實驗頁簽查看,如下圖。
本章作為玩轉數據係列的開篇,先提供一個簡單的案例給大家熱身。通過截取一份人口普查的數據,對學曆和收入進行統計和分析。主要目的是幫助大家學習阿裏雲機器學習實驗的搭建流程和組件的使用方式。任何關於阿裏雲機器學習方麵的交流歡迎訪問我們的雲棲社區公眾號。
二、數據集介紹
數據源: UCI開源數據集Adult針對美國某區域的一次人口普查結果,共32561條數據。具體字段如下表:
| 字段名 | 含義 | 類型 |
|---|---|---|
| age | 年齡 | double |
| workclass | 工作類型 | string |
| fnlwgt | 序號 | string |
| education | 教育程度 | string |
| education_num | 受教育時間 | double |
| maritial_status | 婚姻狀況 | string |
| occupation | 職業 | string |
| relationship | 關係 | string |
| race | 種族 | string |
| sex | 性別 | string |
| capital_gain | 資本收益 | string |
| capital_loss | 資本損失 | string |
| hours_per_week | 每周工作小時數 | double |
| native_country | 原籍 | string |
| income | 收入 | string |
三、數據探索流程
選中人口統計demo,從模型生成實驗,如下圖: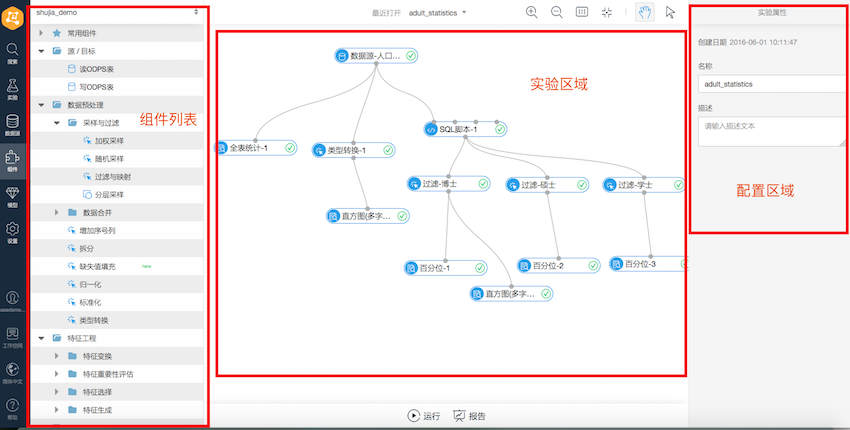
使用方式:
-用戶通過從左邊列表拖拽組件到試驗區域搭建實驗流程
-在配置區域對每個組件的參數進行設置
1.數據導入
機器學習平台的底層計算式阿裏雲分布式計算係統MaxCompute(原名ODPS),所以實驗數據需要先導入到ODPS表裏,用戶可以通過讀ODPS表(圖中的數據源-人口統計)組件導入數據。上傳成功後,右鍵組件可以查看數據,如下圖: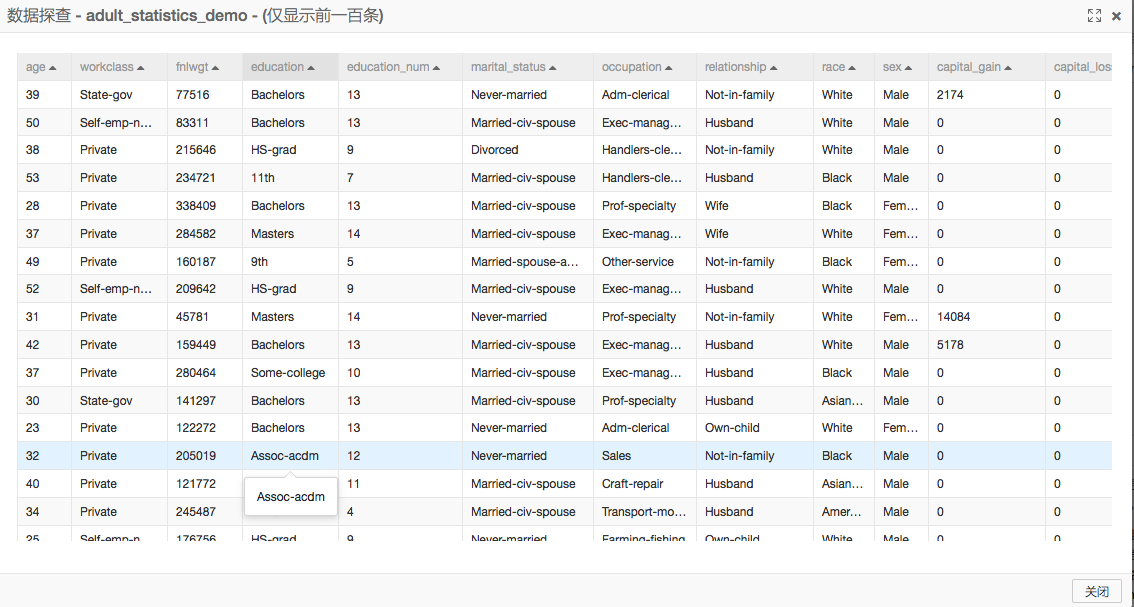
2.理解數據
數據導入後就可以對數據進行分析了,整個實現從縱向看分為三個部分。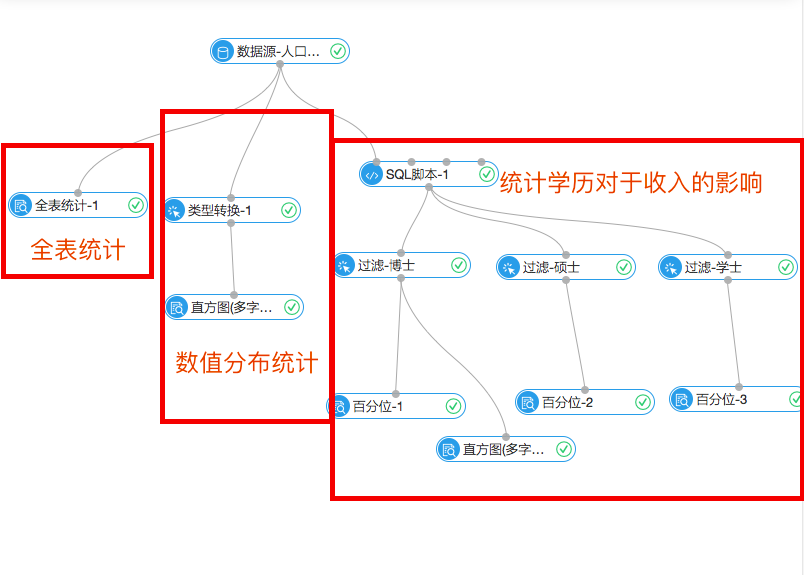
其中全表統計和數值分布統計是幫助用戶更好的理解一份數據,理解一份數據是符合泊鬆分布或是高斯分布,連續或是離散的對之後的算法的選擇會有一定幫助(具體的對照關係在之後的文章會詳細介紹)。阿裏雲機器學習的每個套件都提供了可視化顯示結果的功能,下圖是數值統計的直方圖組件結果,可以清楚地看到每個輸入數值的分布情況。
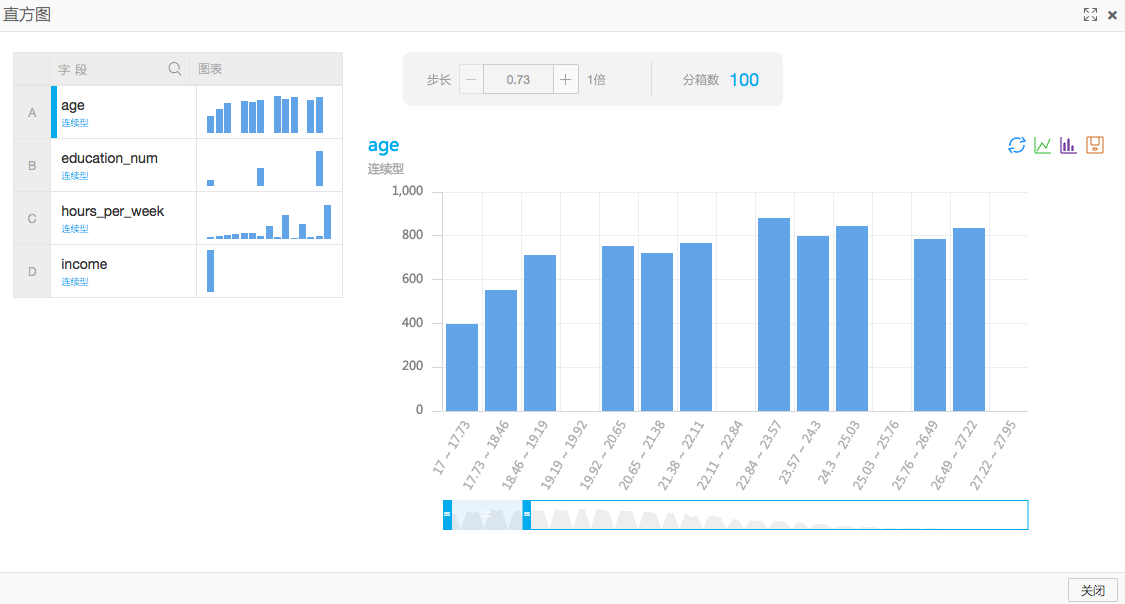
3.統計不同學曆的人員的收入情況
每個人都想增加收入,都想知道哪些因素對收入的影響最大。這些問題都可以通過提取特征,利用機器學習算法訓練來得到。本文主要目的是簡單介紹一下機器學習平台的使用方法,這裏簡單的針對不同學曆的人員的收入做一下統計。
(1)數據的預處理
我們看到在收入統計的這條線上,數據流入的第一個組件是SQL腳本(如下圖),機器學習平台提供SQL腳本對於數據進行處理。這裏是將string型的income字段轉換成二值型的0和1的形式。0表示年收入在50K以下,1表示年收入在50K以上。這種將文本數據數值化是機器學習特征處理的常用方式,以後會經常用到這種方式。
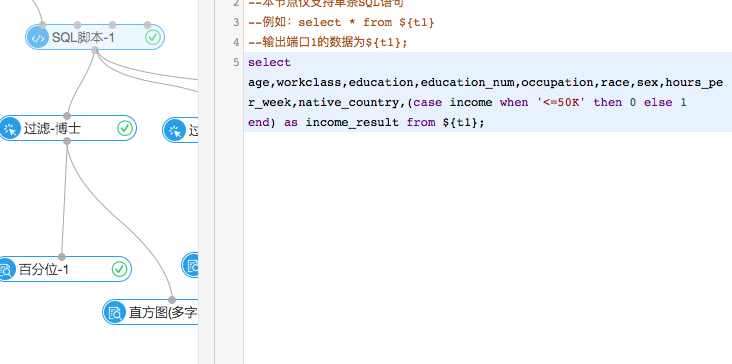
(2)過濾與映射
這一步主要是通過過濾與映射組件將數據按照學曆分為三部分,分別是博士、碩士和學士。過濾與映射底層是SQL語法,支持where過濾條件,用戶通過在右邊的配置欄填寫過濾條件即可。
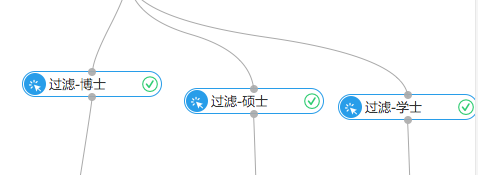
(3)統計結果
通過每個百分位組件就可以方便的得到每個分類下的收入比例。下圖是調成折線圖的展示效果,結果中為0的點也就是年收入在50K以下的人群占比例百分之25左右。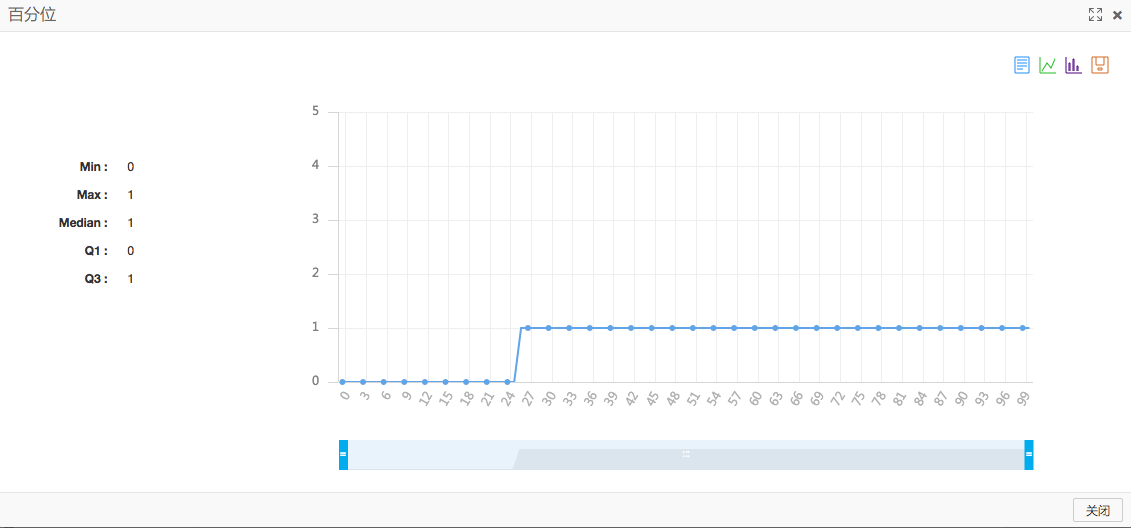
結合三個百分位組件就可以得到如下圖結果。
| 學曆 | 年收入>50K比例 |
|---|---|
| 博士 | 75% |
| 碩士 | 57% |
| 學士 | 42% |
四、其它
參與討論:雲棲社區公眾號
免費體驗:阿裏雲數加機器學習平台
下期預告:利用機器學習算法預測患者是否患有心髒病最後更新:2016-11-23 16:04:12
上一篇: 協同過濾做商品推薦__案例_機器學習-阿裏雲
協同過濾做商品推薦__案例_機器學習-阿裏雲
下一篇: 學生考試成績預測__案例_機器學習-阿裏雲
- 項目空間的權限管理__安全相關語句匯總_安全指南_大數據計算服務-阿裏雲
- 恢複 RDS 數據__備份與恢複_用戶指南_雲數據庫 RDS 版-阿裏雲
- 門店識別__API介紹_文字識別_人工智能圖像類-阿裏雲
- TxtFileWriter__Writer插件_使用手冊_數據集成-阿裏雲
- MapReduce開發插件介紹__Eclipse開發插件_工具_大數據計算服務-阿裏雲
- MaxCompute數據源配置__數據源配置_數據同步手冊_用戶操作指南_大數據開發套件-阿裏雲
- RemoveTags__標簽相關API_API 參考_負載均衡-阿裏雲
- CreateTable__API 概覽_API 參考_表格存儲-阿裏雲
- Condition__DataType_API 參考_表格存儲-阿裏雲
- 阿裏雲大數據學院簽約落戶青島西海岸新區
相關內容
- 常見錯誤說明__附錄_大數據計算服務-阿裏雲
- 發送短信接口__API使用手冊_短信服務-阿裏雲
- 接口文檔__Android_安全組件教程_移動安全-阿裏雲
- 運營商錯誤碼(聯通)__常見問題_短信服務-阿裏雲
- 設置短信模板__使用手冊_短信服務-阿裏雲
- OSS 權限問題及排查__常見錯誤及排除_最佳實踐_對象存儲 OSS-阿裏雲
- 消息通知__操作指南_批量計算-阿裏雲
- 設備端快速接入(MQTT)__快速開始_阿裏雲物聯網套件-阿裏雲
- 查詢API調用流量數據__API管理相關接口_API_API 網關-阿裏雲
- 使用STS訪問__JavaScript-SDK_SDK 參考_對象存儲 OSS-阿裏雲