協同過濾做商品推薦__案例_機器學習-阿裏雲
(本文數據為虛構,僅供實驗)
一、背景
數據挖掘的一個經典案例就是尿布與啤酒的例子。尿布與啤酒看似毫不相關的兩種產品,但是當超市將兩種產品放到相鄰貨架銷售的時候,會大大提高兩者銷量。很多時候看似不相關的兩種產品,卻會存在這某種神秘的隱含關係,獲取這種關係將會對提高銷售額起到推動作用,然而有時這種關聯是很難通過理性的分析得到的。這時候我們需要借助數據挖掘中的常見算法-協同過濾來實現。這種算法可以幫助我們挖掘人與人以及商品與商品的關聯關係。
協同過濾算法是一種基於關聯規則的算法,以購物行為為例。假設有甲和乙兩名用戶,有a、b、c三款產品。如果甲和乙都購買了a和b這兩種產品,我們可以假定甲和乙有近似的購物品味。當甲購買了產品c而乙還沒有購買c的時候,我們就可以把c也推薦給乙。這是一種典型的user-based情況,就是以user的特性做為一種關聯。
本文的業務場景如下:通過一份7月份前的用戶購物行為數據,獲取商品的關聯關係,對用戶7月份之後的購買形成推薦,並評估結果。比如用戶甲某在7月份之前買了商品A,商品A與B強相關,我們就在7月份之後推薦了商品B,並探查這次推薦是否命中。
二、數據集介紹
數據源:本數據源為天池大賽提供數據,數據按時間分為兩份,分別是7月份之前的購買行為數據和7月份之後的。具體字段如下:
| 字段名 | 含義 | 類型 | 描述 |
|---|---|---|---|
| user_id | 用戶編號 | string | 購物的用戶ID |
| item_id | 物品編號 | string | 被購買物品的編號 |
| active_type | 購物行為 | string | 0表示點擊,1表示購買,2表示收藏,3表示購物車 |
| active_date | 購物時間 | string | 購物發生的時間 |
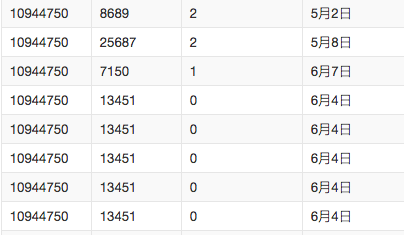
數據截圖:
三、數據探索流程
首先,實驗流程圖: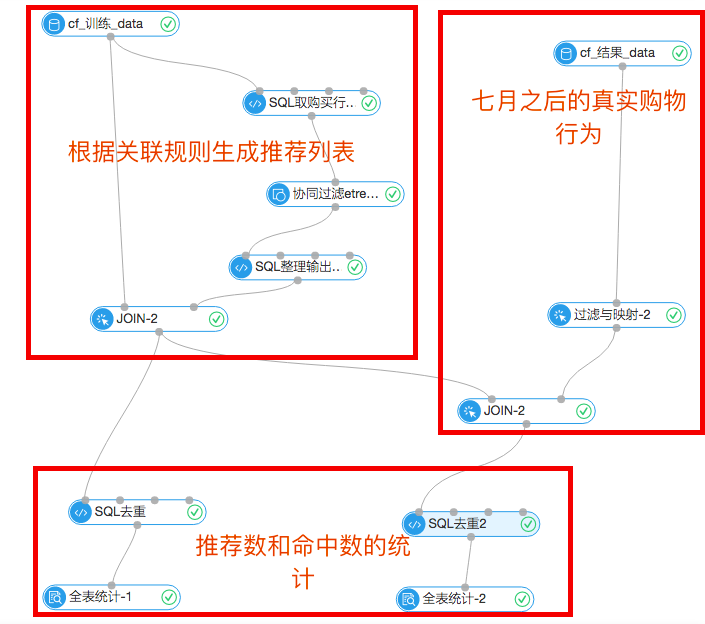
1.協同過濾推薦流程
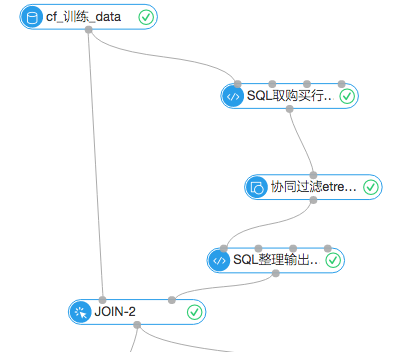
首先輸入的數據源是7月份之前的購物行為數據,通過SQL腳本取出用戶的購買行為數據,進入協同過濾組件。協同過濾的組件設置中把TopN設置成1,表示每個item返回最相近的item和它的權重。通過購買行為,分析出哪些商品被同一個user購買的可能性最大。設置圖如下:

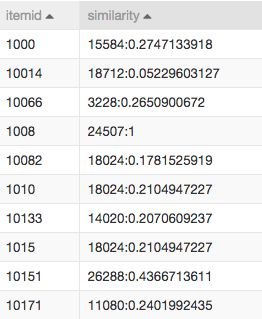
協同過濾結果,表示的是商品的關聯性,itemid表示目標商品,similarity字段的冒號左側表示與目標關聯性高的商品,右邊表示概率:
2.推薦
上述步驟介紹了如何生成強關聯商品的對應列表。這裏使用了比較簡單的推薦規則,比如用戶甲某在7月份之前買了商品A,商品A與B強相關,我們就在7月份之後推薦了商品B,並探查這次推薦是否命中。這個步驟是通過下圖實現的:
3.結果統計
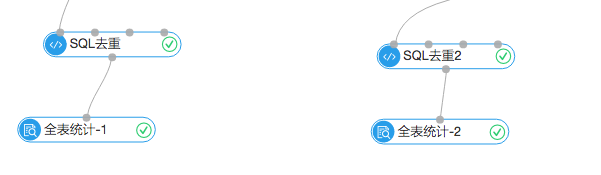
上麵是統計模塊,左邊的全表統計展示的是根據7月份之前的購物行為生成的推薦列表,去重後一共18065條。右邊的統計組件顯示一共命中了90條。
四、推薦係統反思
根據上文的統計結果可以看出,本次試驗的推薦效果並不理想,原因在如下幾方麵。
1)首先本文隻是針對了業務場景大致介紹了協同過濾推薦的用法。很多針對於購物行為推薦的關鍵點都沒有處理,比如說時間序列,購物行為一定要注意對於時效性的分析,跨度達到幾個月的推薦不會有好的效果。其次沒有注意推薦商品的屬性,本文隻考慮了商品的關聯性,沒有考慮商品是否為高頻或者是低頻商品,比如說用戶A上個月買了個手機,A下個月就不大會繼續購買手機,因為手機是低頻消費品。
2)基於關聯規則的推薦很多時候最好是作為補充,真正想提高準確率還是要依靠機器學習算法訓練模型的方式。
五、其它
參與討論:雲棲社區公眾號
免費體驗:阿裏雲數加機器學習平台
往期文章:
【玩轉數據係列二】機器學習應用沒那麼難,這次教你玩心髒病預測
最後更新:2016-07-15 14:39:57
上一篇: 新聞分類案例__案例_機器學習-阿裏雲
新聞分類案例__案例_機器學習-阿裏雲
下一篇: 人口普查統計案例__案例_機器學習-阿裏雲
- 其他實例遷入__數據遷移_API 參考_雲數據庫 RDS 版-阿裏雲
- 優化建議__最佳實踐_雲數據庫 PetaData-阿裏雲
- 查詢API列表__API管理相關接口_API_API 網關-阿裏雲
- SDK API介紹__Android SDK手冊_App SDK 手冊_移動推送-阿裏雲
- python日誌__常見日誌格式_用戶指南_日誌服務-阿裏雲
- 百度聯手奇瑞打造全新人工智能汽車,阿裏雲推出FPGA計算實例,提供人工智能加速服務
- 步驟 2:創建Windows實例__快速入門(Windows)_雲服務器 ECS-阿裏雲
- 快速切換API版本__API管理相關接口_API_API 網關-阿裏雲
- 示例項目使用說明__開發準備_開發人員指南_E-MapReduce-阿裏雲
- 分區__公共資源說明_API-Reference_日誌服務-阿裏雲
相關內容
- 常見錯誤說明__附錄_大數據計算服務-阿裏雲
- 發送短信接口__API使用手冊_短信服務-阿裏雲
- 接口文檔__Android_安全組件教程_移動安全-阿裏雲
- 運營商錯誤碼(聯通)__常見問題_短信服務-阿裏雲
- 設置短信模板__使用手冊_短信服務-阿裏雲
- OSS 權限問題及排查__常見錯誤及排除_最佳實踐_對象存儲 OSS-阿裏雲
- 消息通知__操作指南_批量計算-阿裏雲
- 設備端快速接入(MQTT)__快速開始_阿裏雲物聯網套件-阿裏雲
- 查詢API調用流量數據__API管理相關接口_API_API 網關-阿裏雲
- 使用STS訪問__JavaScript-SDK_SDK 參考_對象存儲 OSS-阿裏雲