細說分布式數據庫的過去、現在與未來
主題簡介:
-
分布式數據庫的曆史和現狀
-
TiDB架構和特點
-
分布式數據庫未來趨勢
隨著大數據這個概念的興起以及真實需求在各個行業的落地,很多人都熱衷於討論分布式數據庫,今天就這個話題,主要分為三部分:第一部分講一下分布式數據庫的過去和現狀,希望大家能對這個領域有一個全麵的了解;第二部分講一下TiDB的架構以及最近的一些進展;最後結合我們開發TiDB過程中的一些思考講一下分布式數據庫未來可能的趨勢。
一、分布式數據庫的曆史和現狀

1、從單機數據庫說起
關係型數據庫起源自1970年代,其最基本的功能有兩個:
-
把數據存下來;
-
滿足用戶對數據的計算需求。
第一點是最基本的要求,如果一個數據庫沒辦法把數據安全完整存下來,那麼後續的任何功能都沒有意義。當滿足第一點後,用戶緊接著就會要求能夠使用數據,可能是簡單的查詢,比如按照某個Key來查找Value;也可能是複雜的查詢,比如要對數據做複雜的聚合操作、連表操作、分組操作。往往第二點是一個比第一點更難滿足的需求。
在數據庫發展早期階段,這兩個需求其實不難滿足,比如有很多優秀的商業數據庫產品,如Oracle/DB2。在1990年之後,出現了開源數據庫MySQL和PostgreSQL。這些數據庫不斷地提升單機實例性能,再加上遵循摩爾定律的硬件提升速度,往往能夠很好地支撐業務發展。
接下來,隨著互聯網的不斷普及特別是移動互聯網的興起,數據規模爆炸式增長,而硬件這些年的進步速度卻在逐漸減慢,人們也在擔心摩爾定律會失效。在此消彼長的情況下,單機數據庫越來越難以滿足用戶需求,即使是將數據保存下來這個最基本的需求。
2、分布式數據庫
所以2005年左右,人們開始探索分布式數據庫,帶起了NoSQL這波浪潮。這些數據庫解決的首要問題是單機上無法保存全部數據,其中以HBase/Cassadra/MongoDB為代表。為了實現容量的水平擴展,這些數據庫往往要放棄事務,或者是隻提供簡單的KV接口。存儲模型的簡化為存儲係統的開發帶來了便利,但是降低了對業務的支撐。
(1)NoSQL的進擊
HBase是其中的典型代表。HBase是Hadoop生態中的重要產品,Google BigTable的開源實現,所以這裏先說一下BigTable。
BigTable是Google內部使用的分布式數據庫,構建在GFS的基礎上,彌補了分布式文件係統對於小對象的插入、更新、隨機讀請求的缺陷。HBase也按照這個架構實現,底層基於HDFS。HBase本身並不實際存儲數據,持久化的日誌和SST file存儲在HDFS上,Region Server通過 MemTable 提供快速的查詢,寫入都是先寫日誌,後台進行Compact,將隨機寫轉換為順序寫。數據通過 Region 在邏輯上進行分割,負載均衡通過調節各個Region Server負責的Region區間實現,Region在持續寫入後,會進行分裂,然後被負載均衡策略調度到多個Region Server上。
前麵提到了,HBase本身並不存儲數據,這裏的Region僅是邏輯上的概念,數據還是以文件的形式存儲在HDFS上,HBase並不關心副本個數、位置以及水平擴展問題,這些都依賴於HDFS實現。和BigTable一樣,HBase提供行級的一致性,從CAP理論的角度來看,它是一個CP的係統,並且沒有更進一步提供 ACID 的跨行事務,也是很遺憾。
HBase的優勢在於通過擴展Region Server可以幾乎線性提升係統的吞吐,及HDFS本身就具有的水平擴展能力,且整個係統成熟穩定。但HBase依然有一些不足。首先,Hadoop使用Java開發,GC延遲是一個無法避免問題,這對係統的延遲造成一些影響。另外,由於HBase本身並不存儲數據,和HDFS之間的交互會多一層性能損耗。第三,HBase和BigTable一樣,並不支持跨行事務,所以在Google內部有團隊開發了MegaStore、Percolator這些基於BigTable的事務層。Jeff Dean承認很後悔沒有在BigTable中加入跨行事務,這也是Spanner出現的一個原因。
(2)RDMS的救贖
除了NoSQL之外,RDMS係統也做了不少努力來適應業務的變化,也就是關係型數據庫的中間件和分庫分表方案。做一款中間件需要考慮很多,比如解析 SQL,解析出ShardKey,然後根據ShardKey分發請求,再合並結果。另外在中間件這層還需要維護Session及事務狀態,而且大多數方案並不支持跨shard的事務,這就不可避免地導致了業務使用起來會比較麻煩,需要自己維護事務狀態。此外,還有動態的擴容縮容和自動的故障恢複,在集群規模越來越大的情況下,運維和DDL的複雜度是指數級上升。
國內開發者在這個領域有過很多的著名的項目,比如阿裏的Cobar、TDDL,後來社區基於Cobar改進的MyCAT,360開源的Atlas等,都屬於這一類中間件產品。在中間件這個方案上有一個知名的開源項目是Youtube的Vitess,這是一個集大成的中間件產品,內置了熱數據緩存、水平動態分片、讀寫分離等,但這也造成了整個項目非常複雜。
另外一個值得一提的是PostgreSQL XC這個項目,其整體的架構有點像早期版本的OceanBase,由一個中央節點來處理協調分布式事務,數據分散在各個存儲節點上,應該是目前PG 社區最好的分布式擴展方案,不少人在基於這個項目做自己的係統。
3、NewSQL的發展
2012~2013年Google 相繼發表了Spanner和F1兩套係統的論文,讓業界第一次看到了關係模型和NoSQL的擴展性在一個大規模生產係統上融合的可能性。 Spanner 通過使用硬件設備(GPS時鍾+原子鍾)巧妙地解決時鍾同步的問題,而在分布式係統裏,時鍾正是最讓人頭痛的問題。Spanner的強大之處在於即使兩個數據中心隔得非常遠,也能保證通過TrueTime API獲取的時間誤差在一個很小的範圍內(10ms),並且不需要通訊。Spanner的底層仍然基於分布式文件係統,不過論文裏也說是可以未來優化的點。
Google的內部的數據庫存儲業務,大多是3~5副本,重要的數據需要7副本,且這些副本遍布全球各大洲的數據中心,由於普遍使用了Paxos,延遲是可以縮短到一個可以接受的範圍(寫入延遲100ms以上),另外由Paxos帶來的Auto-Failover能力,更是讓整個集群即使數據中心癱瘓,業務層都是透明無感知的。F1是構建在Spanner之上,對外提供了SQL接口,F1是一個分布式MPP SQL層,其本身並不存儲數據,而是將客戶端的SQL翻譯成對KV的操作,調用Spanner來完成請求。
Spanner和F1的出現標誌著第一個NewSQL在生產環境中提供服務,將下麵幾個功能在一套係統中提供:
-
SQL支持
-
ACID事務
-
水平擴展
-
Auto Failover
-
多機房異地容災
正因為具備如此多的誘人特性,在Google內部,大量的業務已經從原來的 BigTable切換到Spanner之上。相信這對業界的思路會有巨大的影響,就像當年的Hadoop一樣,Google的基礎軟件的技術趨勢是走在社區前麵的。
Spanner/F1論文引起了社區的廣泛的關注,很快開始出現了追隨者。第一個團隊是CockroachLabs做的CockroachDB。CockroachDB的設計和Spanner很像,但是沒有選擇TrueTime API ,而是使用HLC(Hybrid logical clock),也就是NTP +邏輯時鍾來代替TrueTime時間戳,另外CockroachDB選用Raft做數據複製協議,底層存儲落地在RocksDB中,對外的接口選擇了PG協議。
CockroachDB的技術選型比較激進,比如依賴了HLC來做事務,時間戳的精確度並沒有辦法做到10ms內的延遲,所以Commit Wait需要用戶自己指定,其選擇取決於用戶的NTP服務時鍾誤差,這點對於用戶來說非常不友好。當然 CockroachDB的這些技術選擇也帶來了很好的易用性,所有邏輯都在一個組件中,部署非常簡單,這個是非常大的優點。
另一個追隨者就是我們做的TiDB。這個項目已經開發了兩年時間,當然在開始動手前我們也準備了很長時間。接下來我會介紹一下這個項目。
二、TiDB的架構和最近進展
TiDB本質上是一個更加正統的Spanner和F1實現,並不CockroachDB那樣選擇將SQL和KV融合,而是像Spanner和F1一樣選擇分離。下麵是TiDB的架構圖:
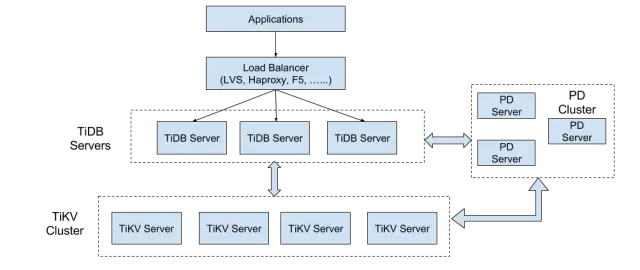
這樣分層的思想也是貫穿整個TiDB項目始終的,對於測試,滾動升級以及各層的複雜度控製會比較有優勢,另外TiDB選擇了MySQL協議和語法的兼容,MySQL社區的ORM框架、運維工具,直接可以應用在TiDB上,另外和 Spanner一樣,TiDB是一個無狀態的MPP SQL Layer,整個係統的底層是依賴 TiKV 來提供分布式存儲和分布式事務的支持,TiKV的分布式事務模型采用的是Google Percolator的模型,但是在此之上做了很多優化,Percolator的優點是去中心化程度非常高,整個繼續不需要一個獨立的事務管理模塊,事務提交狀態這些信息其實是均勻分散在係統的各個key的meta中,整個模型唯一依賴的是一個授時服務器,在我們的係統上,極限情況這個授時服務器每秒能分配 400w以上個單調遞增的時間戳,大多數情況基本夠用了(畢竟有Google量級的場景並不多見),同時在TiKV中,這個授時服務本身是高可用的,也不存在單點故障的問題。

上麵是TiKV的架構圖。TiKV和CockroachDB一樣也是選擇了Raft作為整個數據庫的基礎,不一樣的是,TiKV整體采用Rust語言開發,作為一個沒有GC和 Runtime的語言,在性能上可以挖掘的潛力會更大。不同TiKV實例上的多個副本一起構成了一個Raft Group,PD負責對副本的位置進行調度,通過配置調度策略,可以保證一個Raft Group的多個副本不會保存在同一台機器/機架/機房中。
除了核心的TiDB、TiKV之外,我們還提供了不少易用的工具,便於用戶做數據遷移和備份。比如我們提供的Syncer,不但能將單個MySQL實例中的數據同步到TiDB,還能將多個MySQL實例中的數據匯總到一個TiDB集群中,甚至是將已經分庫分表的數據再合庫合表。這樣數據的同步方式更加靈活好用。
TiDB目前即將發布RC3版本,預計六月份能夠發布GA版本。在即將到來的 RC3版本中,對MySQL兼容性、SQL優化器、係統穩定性、性能做了大量的工作。對於OLTP場景,重點優化寫入性能。另外提供了權限管理功能,用戶可以按照MySQL的權限管理方式控製數據訪問權限。對於OLAP場景,也對優化器做了大量的工作,包括更多語句的優化、支持SortMergeJoin算子、IndexLookupJoin算子。另外對內存使用也做了大量的優化,一些場景下,內存使用下降75%。
除了TiDB本身的優化之外,我們還在做一個新的工程,名字叫TiSpark。簡單來講,就是讓Spark更好地接入TiDB。現在其實Spark已經可以通過JDBC接口讀取TiDB中的數據,但是這裏有兩個問題:1. 隻能通過單個TiDB節點讀取數據且數據需要從TiKV中經過 TiDB 中轉。2. 不能和Spark的優化器相結合,我們期望能和Spark的優化器整合,將Filter、聚合能通過TiKV的分布式計算能力提速。這個項目已經開始開發,預計近期開源,五月份就能有第一個版本。
三、分布式數據庫的未來趨勢
關於未來,我覺得未來的數據庫會有幾個趨勢,也是TiDB項目追求的目標:
1、數據庫會隨著業務雲化,未來一切的業務都會跑在雲端,不管是私有雲或者公有雲,運維團隊接觸的可能再也不是真實的物理機,而是一個個隔離的容器或者「計算資源」,這對數據庫也是一個挑戰,因為數據庫天生就是有狀態的,數據總是要存儲在物理的磁盤上,而數據移動的代價比移動容器的代價可能大很多。
2、多租戶技術會成為標配,一個大數據庫承載一切的業務,數據在底層打通,上層通過權限,容器等技術進行隔離,但是數據的打通和擴展會變得異常簡單,結合第一點提到的雲化,業務層可以再也不用關心物理機的容量和拓撲,隻需要認為底層是一個無窮大的數據庫平台即可,不用再擔心單機容量和負載均衡等問題。
3、OLAP和OLTP業務會融合,用戶將數據存儲進去後,需要比較方便高效的方式訪問這塊數據,但是OLTP和OLAP在SQL優化器/執行器這層的實現一定是千差萬別的。以往的實現中,用戶往往是通過ETL工具將數據從OLTP數據庫同步到OLAP數據庫,這一方麵造成了資源的浪費,另一方麵也降低了OLAP的實時性。對於用戶而言,如果能使用同一套標準的語法和規則來進行數據的讀寫和分析,會有更好的體驗。
4、在未來分布式數據庫係統上,主從日誌同步這樣落後的備份方式會被Multi-Paxos / Raft這樣更強的分布式一致性算法替代,人工的數據庫運維在管理大規模數據庫集群時是不可能的,所有的故障恢複和高可用都將是高度自動化的。
原文發布時間為:2017-05-02
本文來自雲棲社區合作夥伴DBAplus
最後更新:2017-05-17 14:01:39