《Java特種兵》5.2 線程安全(一)
接下來的內容都將基於多核處理器,因為單核處理器不會出現將要談到的可見性問題,不過並不代表單核CPU上多個線程就沒有一致性問題,因為CPU有時間片原則,還會有其他的一些問題,例如重排序。
本節的內容比較偏重於理論化,看過的同學應該知道這部分內容並不容易看懂。不過要學習並發編程就必然會涉及這方麵的內容,所以我們一定要努力去學習,胖哥會盡量通過自己的理解,用一些相對簡單的方式讓大家得到一些感性認識,進一步的深入就得靠大家自己多去參看相關的資料了。
5.2.1 並發內存模型概述
前文中提到,為了提升性能CPU會Cache許多數據。但在多核CPU下,每個CPU都有自己獨立的Cache,每個CPU都可以修改同一個單元數據,因此它們會有自己的一套“緩存一致性協議”,這個一致性是從CPU的角度認為某些來自主存的數據的讀取和修改需要一定的一致性保障。
在JVM運行時,每個線程的私有棧在使用共享數據時,會先將共享數據拷貝到棧頂進行運算,這份數據其實是一個副本,因此也同樣存在多個線程修改同一個內存單元的一致性問題。JVM自己完成了一套內存模型(Java Memory Model,JMM)的規範,這套模型將基於不同的平台去做特定的優化,JMM的基本管理策略是滿足於一種通用的規範,所以這件事情是比較麻煩的。這種模型在JDK 1.2就有了,直到JDK 1.5(JSR-133)及以後的版本中,JVM的內存管理才開始逐步成熟起來。
要了解並發的問題,就要知道並發的問題到底是什麼,下麵給出一段簡單的代碼來做個測試,以便對並發的問題有一個初步的了解。
代碼清單5-5 初識線程不安全的代碼
public class NoVisiabilityTest {
private static class ReadThread extends Thread {
private boolean ready;
private int number;
public void run() {
while(!ready) {
number++;
}
System.out.println(ready);
}
public void readyOn() {
this.ready = true;
}
}
public static void main(String []args) throws InterruptedException {
ReadThread readThread = new ReadThread();
readThread.start();
Thread.sleep(200);
readThread.readyOn();
System.out.println(readThread.ready);
}
}
這段代碼請確保運行在Server模式下,運行的結果可能會與我們所預想的不一樣,不過某些JDK本身不支持Server模式,則達不到本例子所想要模擬的結果。
由於服務器端程序絕大部分都是在Server模式下,所以本例也並非故意製造變態環境,因此編寫服務器端程序的同學應當關注這樣的問題。
按照常理來講,這段代碼會在運行一段時間後自動退出,因為readyOn()方法會將對象的ready參數設置為true,那麼while(!ready)會失敗,理論上就會跳出循環,結束子線程的運行。但是在Server模式下運行時,這段代碼會走入死循環,主線程輸出了結果,而子線程一直都不結束。
在同一個對象內部,一個線程將該對象的屬性修改後,另一個線程看不到該屬性被修改後的結果,或者說未必能馬上看到結果,這就是並發模型中的“可見性”問題。因為普通變量的修改並不需要立即寫回到主存,而線程讀取時也不需要每一次都從主存中去讀取,因此就可能導致這樣的現象。此時若在循環中增加一個Thread.yield();操作就可以讓線程讓步CPU,進而很可能到主存中讀到最新的ready值,達到退出循環的目的。也可以在循環中加一條System.out語句,或者將ready變量增加一個volatile修飾符也可以達到退出的目的。
我們研究這段代碼的目的不僅僅是為了解決一個死循環的問題,而且是要告訴大家代碼運行過程中確實存在可見性問題。或許前麵提到的幾種方法可以達到目的,但我們可能並不是太清楚是怎麼解決的,或者說在什麼情況下用這種方式來解決。
為了解決這個問題,早期做法都是加悲觀鎖,隨著計算機需求的發展,大牛們對技術內在做了許多研究,他們發現這種方式的開銷很大,我們希望有更細粒度的控製方式來提升性能。
從宏觀上我們將JVM內存劃分為堆和棧兩個部分,堆內存就是Java對象所使用的區域,在JMM的定義中通常把這塊空間叫作“Main Memroy”(主存)。棧空間內部應當包含局部變量、操作數棧、當前方法的常量池指針、當前方法的返回地址等信息,這塊空間在我們看來是最接近CPU運算的,也是每個線程私有的空間,當調用某方法開始時將給該私有棧分配空間,在方法內部再調用方法還會繼續使用相應的棧空間,方法返回時回收相應的棧空間(不論是否拋出異常)。這塊空間通常叫作“Working Memory”(工作內存)。
如果棧內部所包含的“局部變量”是引用(Reference),則僅僅是引用值在棧中,而且會占用一個引用本身的大小,具體的對象還是在堆當中的,即對象本身的大小與棧空間的使用無關。
工作內存與主存之間會采用read/write的方式進行通信,而當工作內存中的數據需要計算時,它會發生load/store操作,load操作通常是將本地變量推至棧頂,用來給CPU調度運算,而store就是將棧頂的數據寫入本地變量。
通過javap命令輸出指令列表,從中可以看到各種XXload指令(0x15~0x35),就是將不同類型的信息推至棧頂,指令除了可以標識數據類型外,還可以標識寬度;相應的XXstore指令(0x36~0x56)就是將不同類型的棧頂數據存入本地變量。
局部變量(本地變量)在使用時通常不存在一致性問題,因為它的定義本身就歸屬於線程運行時,生命周期由相應的代碼塊決定。所以在一致性問題上,我們關注的是多線程對主存的一些數據讀寫操作。
關於線程換個角度來理解,如果將JVM當成一個操作係統,則可以將多線程本身理解為多個CPU(理論上多個線程可以並行一起運行),站在抽象層次上看,多核處理緩存一致性就和這些思想有許多相通之處了。
Java想要自己來實現一套一致性協議,需要有一些基礎規則,下麵列舉幾個。
(1)JMM中一些普通變量的操作指令
◎ Load操作發生在read之後(兩個之間可以有其他的指令)。
◎ 普通變量的修改未必會立即發生Store操作,但發生Store操作,就會發生write操作。
有了這個基本規則後,我們似乎就不太關注write/read了,因為Load發生之前肯定有read,而Store操作之後肯定有write,因此我們將讀/寫的4個步驟理解為簡單的2個步驟。
這個JMM的基本規約似乎與多核處理器上的緩存一致性還沒有太大關係,因為在代碼運行過程中完全有可能一個線程讀、一個線程寫,此時就可能出現許多奇怪的現象,比如程序中讀到了老的數據,或者很久甚至永遠都讀不到最新的數據。把這類問題叫作“可見性”問題。
在現實中,我們通常會遇到如下版本管理問題。
例子1:你認為自己從SVN上拿到了最新代碼去修改,結果你在拿代碼時,別人提交了最新版本,在現實中或許沒有多大關係,因為版本管理最終可以一致,但是在計算機中或許不行,因為會導致許多意想不到的後果(例如,可能會導致算錯數據)。
例子2:拿到了最新版本的代碼,一直在修改,一直沒有從SVN更新最新的代碼,如果在這個過程中別人提交了代碼,代碼就不是最新的了。
在現實中想要解決這個問題,就需要大家睜大眼睛隨時看著SVN這個公共的區域是否發生改變,包括對每一個文件的修改,或者大家將代碼就直接寫在SVN上,在同一台服務器上調試代碼,顯然這十分影響工作效率,而且也不現實。計算機也是這樣,在絕大部分情況下,各自的變量沒有衝突,那麼就無須關注對方是否和自己操作同一個內存單元,這樣一來計算機的性能就會很高,隻是在某些特殊場景下,我們不得不有選擇性地使用另一種方式來保障一致性。
這個時候喜歡思考的小夥伴們有了美妙的聯想,希望每次使用某個文件前都自動從SVN上提取最新的,如果有人修改了文件,則自動立即上傳,上傳中如果有人正在下載,則必須等待上傳者完成。當然這隻是一種假設,在計算機中或許能達到這個粒度,我們就有機會進一步做事情了。
這種最細的粒度支持,也就是對Load、Store的各種順序控製,load、store兩兩組合為4種情況:LoadLoad、StoreStore、LoadStore、StoreLoad,它們以一種指令屏障的方式來控製順序,有些係統可能不支持某些指令的順序化,不過絕大部分係統都支持StoreLoad。
(2)StoreLoad的意思
我們可以簡單地認為讓Store先於Load發生。例如兩個在某個瞬間同時修改和讀取主存中的一個共享變量,此時的讀取操作將發生在修改之後。有了這樣一種特征,就實現了最細粒度的鎖,也是最輕量級的鎖(在這裏所提到的輕量的概念與JVM本身對悲觀鎖優化中所引導出的輕量級鎖的概念不是同一個)。
不過,這樣的方式僅僅能保證讀的一瞬間確保線程讀取到最新的數據,因此要進一步做到讀取、修改、寫入的動作是一致的,就將其升級為原子性。要達到原子性的效果,可以通過可見性、CAS自旋來完成,也可以通過synchronized來完成。
5.2.2 一些並發問題描述
前文中的一個簡單例子提到了可見性問題,這個問題比較好模擬,但是還有一些非常不好模擬的並發問題,而且總是存在於一些細節上,本節我們就來描述一此並發問題。
(1)指令重排序
指令重排序可能是Java編譯器在編譯Java代碼時對虛指令進行重排序,也可以是CPU對目標指令進行重排序,它們的目的當然都是為了高效(換句話說,我們自己寫的代碼對於計算機的解析和運行來講順序未必是最高效的)。
重排序在提升性能的同時,也給我們帶來了許多麻煩,而這些麻煩通常帶來的問題十分詭異。為了說明這樣的問題,請大家先看圖5-2。
圖5-2 兩個線程操作共享變量
根據圖5-2描述的代碼及調用關係,按照常理線程1執行init()方法將先創建一個B對象賦值給屬性b,然後再將初始化參數inited設置為true(先拋開可見性問題),其他的線程會先通過isInited()方法判定對象內的屬性是否已經被初始化好,然後再操作對象本身,這樣對象的操作應當是安全的。
如果這裏發生指令重排序,就未必安全了!假如inited=true先於其他屬性被賦值前被執行,那麼此時線程2通過isInited()方法得到返回值為true,但有可能對象內部的某些屬性根本還沒有初始化完成,從而導致許多不可預見的問題。
(1)重排序並不意味著程序中的所有代碼是雜亂無序的,隻是重排序那些沒有相互依賴的代碼,便於某些優化,我們可以認為在單線程中執行代碼結果永遠不會變(as-if-serial)。
(2)用Java寫代碼時本身不注重性能,但是並不意味著不注重較低的抽象層次,因為較低的抽象層次的優化可能影響到Java中大量頻繁的簡單操作的性能,這種時間的提升雖然很小,但有可能對Java整體的運行性能是有影響的。
(2)4字節賦值問題
在JVM中允許對一個非volatile的64位(8字節)變量賦值時,分解為兩個32位(4字節)來完成,但並不是必須要一次性完成(從Java角度來理解,在虛指令中對變量的操作都以slot為單位,每個slot就是4字節)。
問題出來了,如果變量是long、double類型的數據,在賦值某個32位後,正好被另一個線程所讀取,那麼它讀取出來的數據就可能是不可預見的結果。
(3)數據失效
正常的在JavaBean中提供大量的set、get是沒有問題的,如果這樣的對象提供給多線程使用就不一定了,用前麵提到的可見性的道理來講,當一個線程調用set後,其他的線程未必能看得到。
這似乎沒什麼大不了的,那麼胖哥就說個有點小影響的例子。
假如某個賦值是一個應用平台的係統配置參數,它在內存中有一份拷貝,這份配置參數將會影響程序對某些金額的計算方法或業務流程,這時偶然發生了另一個線程看不到的情況,導致雖然有最新的配置,但是這個線程還在走老路,那麼結果自然是錯誤的,完全由可能帶來經濟損失。
(4)非安全的發布
為了說明問題,請先看圖5-3。![DI]7TFO0U{59)_H[S4ZKCKG](https://ifeve.com/wp-content/uploads/2014/11/DI7TFO0U59_HS4ZKCKG.jpg)
圖5-3 對象發布逃逸
這裏的引用a可以直接被外部使用,它希望有一個線程將其初始化後再讓外部看到,但在未初始化好a以前,線程2可能對a直接進行使用了,那麼自然是空指針。更加可怕的是另一種現象,就是此時a引用指向的是一個還未初始化完成的A對象,這個對象空間可能被創建了,但是它的內部屬性的初始化還需要一個過程(例子中隻有1個簡單屬性,在實際的程序中可能會有很多複雜屬性),這是由於在JMM中並沒有規定普通屬性的賦值必須發生在構造方法的return語句之前。換句話說,A對象的構造方法內的屬性賦值可以在return發生之後,而當A對象的構造方法發生return後,B類中的靜態屬性a就可以被賦值了,這樣就會導致線程3在判定B類中的屬性a不為空的情況下,使用這個對象來做操作,而這個對象依然有可能沒有被初始化好。這種問題算是發布的一種“逃逸”問題,換句話說,就是程序訪問了不該訪問的內容,訪問了可能還沒準備好的內容。
並發問題的例子遠不止這些,下麵再做一點點補充。
例如,在內存中用數組或集合類來Cache一些數據,提供給應用服務器的多個線程訪問使用,那麼我們應當如何提供API給它們使用呢?
假如API返回整個集合類或數組,那麼集合類或數組中的元素將有可能被多線程並發修改,這種修改自然就可能會存在並發的問題;如果返回集合類或數組中其中一個下標的元素理論上沒有問題,但集合類或數組中所存放的元素也是對象,對象中包含了許多可變的屬性,則該對象依然可能會被多線程並發地修改。
因此,為了避免並發問題,我們需要考慮一些場景,例如可以使用一份數據拷貝返回,或者返回不允許修改的代理API(Collections.unmodifiable相關API)。返回的數據拷貝,可以是一個集合類或數組的一個元素或者整個集合類或數組,而拷貝的深度需要根據業務來控製,對於複雜的包裝對象,要保證絕對的線程安全性是十分麻煩的。如果要返回不允許修改的數據結構的代理操作類,則可以使用Collections提供的unmodifiable相關的靜態方法,例如Collections.unmodifiableList(List)將返回不可修改的List對象,同樣的,該API限製僅僅局限於List本身不能被修改,若List內部的元素是數組、集合類、包含許多非final屬性的對象,則依然可以在獲取元素後修改相應的內容。
下麵再舉個通過子類“逃逸”的例子。
從圖5-3中可以看到一種通過“逃逸”的例子。很多時候場景千變萬化,例如在子類中提供了自定義的構造方法,在構造方法中將this 引用交給另一個線程所訪問或作為任務的屬性提交給線程池,它們可以通過this訪問這個對象的一些方法或屬性,而此時對象可能還沒有初始化完成相應的屬性。
描述了這麼多問題,或許我們不會這樣寫代碼,或許有的牛人會說“根本就不該這樣寫代碼”,不過反過來講,其實我們是在就問題而探討問題,或許真正的程序會隱藏得更深,但道理基本是一致的。換句話說,我們要理解內在機製,當某一天遇到類似的問題時,可以有能力去分析和解決。
接下來,我們就介紹一些Java麵對各種並發問題提供的語法支持,或者稱作JVM層麵上的功能支持。
5.2.3 volatile
變量被volatile關鍵字修飾後,貌似就會避開前麵提到的部分問題。在前麵我們用一個SVN上傳/下載的理想例子來說明,要做到完美就得犧牲一些性能,雖然volatile它被譽為“最輕量級的鎖”,但它依舊比普通變量的訪問慢一些。之所以說它輕,是因為它隻是在讀這個瞬間要求一個簡單的順序,而不是一個變量上的原子讀寫,或者在一段代碼上的同步。
在JDK 1.5以前,volatile變量並沒有完全實現輕量級的鎖,不過JDK 1.5對可見性做了更為嚴格的定義,因此我們可以開始放心使用。不過也因此volatile修飾的變量的性能可能會有所下降。JDK也同樣對synchronized做了各種輕量級、偏向的優化,簡單來講是Java的作者們開始意識到一些Java鎖的場景,認為在很多場景下鎖的開銷是不需要完全使用悲觀鎖的,因此做了很多改造和優化,不過從理論上講,其開銷應該不會比volatile小(因為它最少會保證一個原子變量的讀寫一致性,而volatile不需要)。另外,synchronized通常是基於代碼段的,開銷變小僅僅是加鎖的過程開銷,而並非鎖所包含的代碼區域也會加快運行速度,相關的代碼區域依然被串行訪問,因此不要期望於係統的鎖優化為我們解決所有的問題,很多優化原則依然需要根據我們對於鎖粒度本身的理解,以及結合相關的業務背景來綜合分析,才能得出答案。
volatile變量也會像普通變量那樣從主存中拷貝到各個線程中去操作,區別在於它要求實現StoreLoad指令屏障(當然JVM也未必一定要用這種指令來實現,前文中提到的4種指令屏障隻要對應的處理器支持,也可以采用具體的平台來優化),由此我們可以簡單地認為volatile的第一個作用就是:保證多線程中的共享變量是始終可見的(但這並不保證volatile引用對象內部的屬性是完全可見的)。
在JSR-133中對volatile語義的定義進行了增強(主要是為了真正實現更簡單的鎖),要求在對volatile變量進行讀/寫操作時,其前後的指令在某些情況下不允許進行重排序(不論是編譯時重排序還是處理器重排序,都不允許)。對於這種限製分為如下幾種情況。
(1)如果是一條對volatile變量進行賦值操作的代碼,那麼在該代碼前麵的任何代碼不能與這個賦值操作交換順序。在圖5-2中,一個inited變量如果使用volatile修飾,那麼就能夠達到目的,因為它能確保前麵屬性的賦值在inited=true發生之前。
我們需要注意兩點:
◎ 如果這個操作後有普通變量的讀寫操作,則是可以與它交換順序的。
◎ 在這個動作之前的指令相互之間還是可以重排序的,隻是不能排序到該動作後麵。它就像一個向前的隔板,隔板前麵的多個動作依然可以被重排序,隔板一邊的普通變量可以進入另一邊,以便於做更多的優化。
(2)如果是一條讀取volatile變量的代碼,則正好相反,相當於隔板翻了一個麵,在它後麵的操作動作不允許與它交換順序,之後的多個動作依然可以重排序,在它之前的普通變量的操作動作也可以與它交換順序。
(3)普通變量的讀寫操作相互之間是可以重排序的,隻要不影響它們之間的邏輯語義順序就可以重排序。但是如果普通變量的讀/寫操作遇上了volatile變量的操作,就需要遵循前兩個基本原則。
(4)如果兩個volatile變量的讀/寫操作都在一段代碼中,則依然遵循前兩個基本原則,此時無論兩者之間讀/寫順序如何,都肯定不會重排序。
這裏反複強調的順序,大家可能會有所疑惑,由於它的重要性,也同時幫助大家理解,下麵舉幾個真實代碼的例子。
◎ 一個變量被賦值後,經過某些讀寫操作,再賦值給另一個變量,這個順序是不會被打亂的。
◎ 程序中try、catch、finally代碼肯定不會交換順序來執行,比如:try部分的代碼還沒執行完,也沒有拋出異常,就執行finally的代碼,這種情況是不會發生的,否則就全部亂套了。我們可以用前麵提到的“始終保持與單線程中的最終計算結果是相同的”這句話來理解這個邏輯順序問題。
綜上所述,volatile修飾變量的第2個作用是:防止相關性代碼的重排序,從指令級別達到了輕量級鎖的目的。除此之外,volatile還有一個重要的作用是解決前麵提到的4字節賦值問題,對於volatile修飾的變量,必須一次性賦值。
volatile內在到底是怎麼回事?或許我們可以輸出某些平台上的匯編指令來看看它到底與普通變量的操作有何特殊性。
輸出匯編指令?這在Java領域很少聽到,不過確實可以做到,隻是有點麻煩。首先要做的事情就是下載插件,由於與平台相關,所以插件也與平台相關。打開地址https://kenai. com/projects/base-hsdis/downloads,可以下載到很多種操作的插件,Windows 32bit版本在https://hllvm.group.iteye.com/ 上可以找到。
將插件下載好以後,放在哪裏?在Linux JVM中放在$JAVA_HOME/jre/lib/amd64/server及client兩個目錄下,並記得執行chmod +x相應的命令;在Windows JVM中放在%JAVA_ HOME%/jre/bin/server及client兩個目錄中,若隻存在一個目錄,則隻放一個。
接下來,我們需要編寫一段簡單的程序,用於檢測不同變量的賦值。
代碼清單5-6 測試輸出匯編指令
public class AssemTest {
int a, b;
volatile int c, d;
public static void main(String[] args) throws Exception {
new AssemTest().test();
}
public void test() {
a = 1;
b = 2;
c = a;
d = b;
b = 3;
c = 2;
}
}
該代碼通過javac編譯為Class文件,下麵使用java命令攜帶相應的參數來輸出匯編指令。
java -XX:+UnlockDiagnosticVMOptions -XX:+PrintAssembly -Xcomp -XX:CompileCommand=compileonly,*AssemTest.test AssemTest
在Linux係統上輸出結果如圖5-4所示。
從圖5-4所示的匯編指令中可以看出,匯編指令中出現了lock addl $0x0操作,它是通過某個較低抽象層次的鎖實現了相應的屏障。
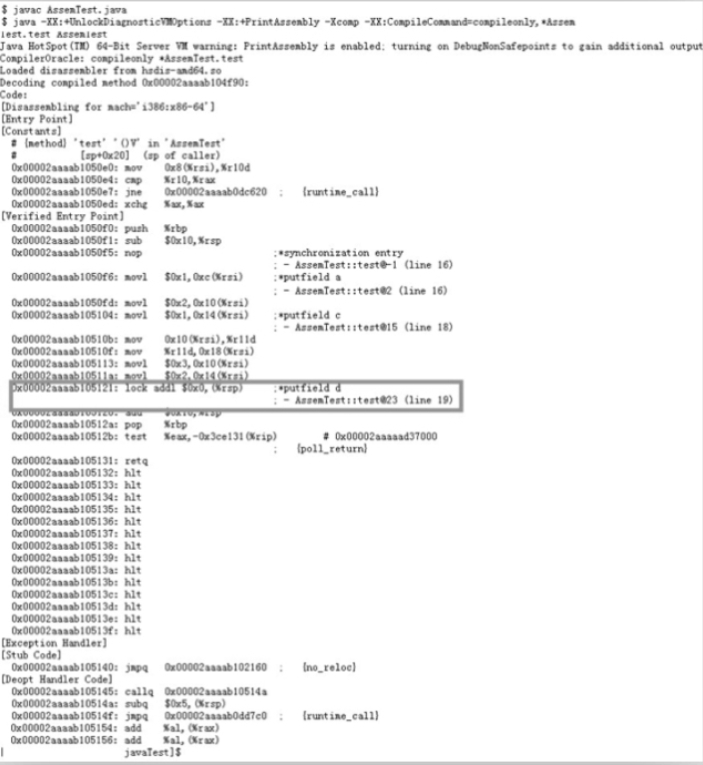
圖5-4 輸出Java在對應平台上的匯編指令
最後更新:2017-05-23 12:31:43