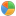 116
116

 阿裏雲 技術社區[雲棲]
阿裏雲 技術社區[雲棲]
《Java特種兵》5.1 基礎介紹
5.1 基礎介紹
5.1.1 線程基礎
本節內容介紹給那些還沒接觸過Java線程的朋友希望能有個感性認識。
Java線程英文名是Thread所有的Java程序的運行都是在進程中分配線程來處理的。如果是一個main方法則由一個主線程來處理如果不創建自定義線程那麼這個程序就是單線程的。如果是Web應用程序那麼就由Web容器分配線程來處理在4.4.1節中介紹了在Tomcat源碼中是如何分配線程的。
也許在使用main方法寫代碼時我們感覺不到多線程的存在在Web程序中也感覺不到多線程和自己編寫程序有什麼關係但是當遇到一些由於Java並發導致的古怪的問題時當需要自己用多線程來編寫程序或者控製多個線程訪問共享資源時就會用到相應的知識。
掌握知識的目標是駕馭知識要駕馭知識的前提是了解知識認識它的內在
在Java代碼中單獨創建線程都要使用類java.lang.Thread通常可以通過繼承並擴展Thread原本的run()方法也可以創建一個Thread將一個Runnable任務實體作為參數傳入這是通過線程來執行任務的過程但並不能說實現了Runnable接口就是一個線程。
Runnable接口顧名思義就是“可以被執行”的意思。在Java語言中還有一些類似的接口例如Closeable它隻能代表“可以被關閉”Closeable接口的描述中提供了一個close()方法要求子類實現。類似的Runnable接口提供了一個要求在實現類中去實現的run()方法換句話說Runnable接口隻是說明了外部程序都可以通過其實例化對象調用到run()方法因此我們通常把它叫作“任務”切忌將任務和時間掛在一起基於時間的任務隻是一類特殊的任務而已。
從另一個角度來看一個線程的啟動是需要通過Thread.start()方法來完成的這個方法會調用本地方法JNI來實現一個真正意義上的線程或者說隻有start()成功調用後由OS分配線程資源才能叫作線程而在JVM中分配的Thread對象隻是與之對應的外殼。
Runnable既然不是線程那麼有何用途
前麵提到可以把Runnable看成一個“任務”如果它僅僅與Thread配合使用即在創建線程的時候將Runnable的實例化對象作為一個參數傳入那麼它將被設置到Thread所在的對象中一個名為“target”的屬性上Thread默認的run()方法是調用這個target的run()方法來完成的這樣Runnable的概念就與線程隔離了——它本身是任務線程可以執行任務否則Thread需要通過子類去實現run()方法來描述任務的內容。
在後文中會提到線程池中的每個Thread可以嚐試獲取多個Runnable任務每次獲取過來後調用其run()方法這樣就更加明顯地說明Thread和Runnable不是一個概念。
區分了這個概念後下麵用一段簡單代碼來模擬一個線程的創建和啟動。請看代碼清單5-1在這段代碼中new Thread() {…}在Java堆中創建了一個簡單的Java對象當通過這個對象調用其start()方法後就啟動了一個線程。不過大家需要注意的是在這段代碼中胖哥將兩條代碼合並為一條來完成不過在內在的執行上依然會是兩條代碼來完成。
代碼清單5-1 一個簡單的Thread的執行
01 |
public static void main(String []args) {
|
04 |
System.out.println("我是被創建的線程我執行了...");
|
07 |
System.out.println("main process end...");
|
12 |
System.out.println("main process end...");
|
為了簡單起見這段程序使用了一個匿名子類重寫了Thread的run()方法與單獨寫一個繼承於Thread的類在功能上是一致的。
這段程序隻是讓初學者了解到線程的存在。
如果是順序執行的程序則應當先輸出“我是被創建的線程我執行了…”然後再輸出“main process end…”因為代碼順序是這樣的但是大家通過測試結果會發現不一定而且一般是先輸出“main process end…”這是因為run()方法被另一個線程調用了main()方法啟動線程後就直接向下執行不過啟動線程還需要做一些內核調用的處理最後才會由C區域的方法回調Java中的run()方法此時main線程可能已經輸出了內容。
為了進一步驗證大家在main()方法和run()方法內部分別輸出當前線程ID或NAME即可發現執行的線程是完全不同的如Thread.currentThread().getName()。
此代碼驗證了兩個結果
◎ 通過Thread的start()方法啟動了另一個線程來處理任務。
◎ 線程的run()方法調用並不是線程在調用start()方法時被同步調用的而是需要一個很短暫的延遲。
線程到底是什麼東西它與進程有何區別呢
通常將線程理解為輕量級進程它和進程有個非常大的區別是多個線程是共享一個進程資源的對於OS的許多資源的分配和管理例如內存通常是進程級別的線程隻是OS調度的最小單位線程相對進程更加輕量一些它的上下文信息會更少它的創建與銷毀會更加簡單線程因為某種原因掛起後不會導致整個進程被掛起一個進程中又可以分配許多的線程所以線程是許多應用係統中大家所喜歡的東西。
但是並非多線程就沒有問題它有個很大的問題就是由於某個線程占用過多的資源會導致整個進程“宕”機由於資源共享所以線程之間會相互影響但是多進程通常不會有這個問題它們共享服務器資源相互影響的級別在服務器資源上而不是在進程內部。
選擇多線程還是多進程要根據實際情況來定類似於Nginx這類負載均衡軟件就采用多進程模型因為它的異步I/O對於高並發來講已經足以解決進程或線程資源不足的情況而且比多線程模型處理得更好因為它是I/O密集型的。但是應用程序如果是計算密集型的或者涉及大量的業務邏輯處理則並不適合這樣做換句話說最終還得根據實際場景來定。
前文中提到new Thread()操作並非完成了線程的創建隻有當調用start()方法時才會真正在係統中存在一個線程。在OS處理線程上也有多種方式至於線程是哪種方式對於我們來講並不是那麼重要我們隻需要知道存在一個單獨的線程可以被調度即可。
我們回想一下第3章提到的一些內容當大量分配線程後可能會報錯“unable to create new native thread”說明線程使用的是堆外的內存空間也再次說明Thread本身所對應的實例僅僅是JVM內的一個普通Java對象是一個線程操作的外殼而不是真正的線程。
補充知識通過Thread的實例對象調用start()方法到底是怎麼啟動線程的下麵對其實現方式做一些簡單的補充。
◎ 基於Kernel ThreadKLT的映射來實現KLT是內核線程內核線程由OS直接完成調度切換它相對應用程序的線程來講隻是一個接口外部程序會使用一種輕量級進程Light Weight ProcessLWP來與KLT進行一對一的接口調用。也就是說進程內部會嚐試利用OS的內核線程去參與實際的調度而自己使用API調用作為中間橋梁與自己的程序進行交互。
◎ 基於用戶線程User ThreadUT的實現這種方式是考慮是否可以沒有中間這一層映射自己的線程直接由CPU來調度或許理論上效率會更高。不過這樣實現時用戶進程所需要關注的抽象層次會更低一些跳過OS更加接近CPU即自己要去做許多OS做的事情自然的OS的調度算法、創建、銷毀、上下文切換、掛起等都要自己來搞定因為CPU隻做計算。這樣做顯然很麻煩許多人曾經嚐試過後來放棄了。
◎ 混合實現方式它的設計理念是希望保留Kernel線程原有架構又想使用用戶線程輕量級進程依然與Kernel線程一一對應保持不變唯一變化的就是輕量級進程不再與進程直接掛鉤而是與用戶線程掛鉤用戶線程並不一定必須與輕量級進程一一對應而是多對多就像在使用一個輕量級進程列表一樣這樣增加了一層來解除輕量級進程與原進程之間的耦合可能會使得調度更為靈活。
在以前的JDK版本中嚐試使用UT的方式來實現但後來放棄了采用了與Kernel線程對應的方式至於一些細節與具體的平台有很大的關係JVM會適當考慮具體平台的因素去實現在JVM規範中也沒規定過必須如何去實現所以對於程序員來講隻需要知道在new Thread()調用start()方法後理論上就有一個可以被OS調度的線程了。
5.1.2 多線程
在上一節的代碼中自己創建了一個線程main()方法本身也有一個線程雖然有主次之分但是已經是多線程了。
寫多線程程序無非就是加線程數量讓多個線程可以並行地去做一些事情。大家可以根據代碼清單5-1增加線程來模擬本書就不再給出代碼了。
大家在代碼清單5-1的基礎上多創建幾個Thread就得到多線程的結果了例如可以讓多個線程輸出某些結果通過輸出會發現它們會交替輸出而不是一個線程輸出結束後下一個線程緊跟著再輸出結果。
5.1.3 線程狀態
談線程就必然要談狀態為何
對線程的每個操作都可能會使線程處於不同的工作機製下在不同的工作機製下某些動作可能會對它產生不同的影響而不同的工作機製就是用狀態來標誌的所以我們一定要了解它的狀態否則在編寫多線程程序時就會出現奇怪的問題。在本小節中胖哥會逐個描述線程中的狀態說明導致此線程狀態可能的原因以及在某種狀態下可以做的事情。
我們不僅要關注線程本身的狀態而且要養成一種關注狀態變化的習慣甚至於在自己做多線程設計時嚐試用一些狀態控製某些東西。因為在多線程的知識體係中關於狀態的信息遠遠不止線程本身的狀態這樣一些信息當然它是最基礎的在後文中介紹的許多Java的並發模型中都會存在各種各樣的狀態轉換如果沒有養成習慣去抓住這個重點我們將很難看懂代碼。
要獲取狀態可以通過線程Thread的getState()來獲取狀態的值。例如獲取當前線程的狀態就可以使用Thread.currentThread().getState()來獲取。該方法返回的類型是一個枚舉類型是Thread內部的一個枚舉全稱為“java.lang.Thread.State”這個枚舉中定義的類型列表就是Java語言這個級別對應的線程狀態列表包含了NEW、RUNNABLE、BLOCKED、WAITING、TIMED_WAITING、TERMINATED這些值。現在對照源碼中的注釋以及胖哥自己的理解來說明它們的意思。
1NEW狀態

意思是這個線程沒有被start()啟動或者說還根本不是一個真正意義上的線程從本質上講這隻是創建了一個Java外殼還沒有真正的線程來運行。
再一次提醒大家注意調用了start()並不代表狀態就立即改變中間還有一些步驟如果在這個啟動的過程中有另一個線程來獲取它的狀態其實是不確定的要看那些中間步驟是否已經完成了。
2RUNNABLE狀態
![7`M((26P$4H0W]XP7UCS5FN](https://res.3425.com.cn/aliyunqi/20170523/1495519322295.jpg)
當處於NEW狀態的線程發生start()結束後線程將變成RUNNABLE狀態。程序正在運行中的線程就肯定處於RUNNABLE狀態上麵提到用Thread.currentThread().getState()來獲取當前線程的狀態隻會得到“RUNNABLE”而不會得到其他的值因為要得到結果就必然處於運行中。所以獲取狀態都是獲取其他線程的狀態而不是自己的狀態。
RUNNABLE狀態也可以理解為存活著正在嚐試征用CPU的線程有可能這個瞬間並沒有占用CPU但是它可能正在發送指令等待係統調度。由於在真正的係統中並不是開啟一個線程後CPU就隻為這一個線程服務它必須使用許多調度算法來達到某種平衡不過這個時候線程依然處於RUNNABLE狀態。
舉個例子當某個運行中的線程發生了yield()操作時其實看到的線程狀態也是RUNNABLE隻是它有一個細節的內部變化就是做一個簡單的讓步。既然談到讓步我們就來簡單說說什麼叫作讓步。
胖哥認為這是一種“高素質”的做法它自己可能在做大量CPU計算認為自己會在相對較長的時間內占用資源如果調度算法存在問題就會一直占用CPU所以在適當的時候做下讓步讓別人也來使用下CPU資源。
在生活中就好比一群人排隊到取款機上取款有些人可能喜歡查了取、取了查、查了再取、取了再查也許中間還有許多思考的過程或許在計算也許還有許多從包裏拿出和放入的動作或許再打個電話再整理下衣服。這在這些人心目中是正常的因為他們認為現在是屬於自己的私人空間但卻忽略了後麵還有很多人在等待的因素可能有人在等待太久以後就放棄了就像放棄CPU調度一樣。而高素質的人會覺得自己占用的時間太長了會“不好意思”主動意識到耽誤了別人太多的時間自己會出來讓別人先處理等別人處理好以後自己再進去。
對應到代碼中比如某些任務可能會在一個比較集中的時間在後台啟動有可能反複執行有可能執行時間相對較長。在資源有限的情況下這樣的係統有可能和其他的係統部署在一台服務器上甚至於一個進程上自然會相互搶占資源在某些必要的情況下可以使用該方式做出一點讓步讓雙方的資源得到平衡。
RUNNABLE狀態可以由其他的許多狀態通過某些操作後進入該狀態處於RUNNABLE狀態的線程本身也可以執行許多操作轉換為其他的狀態比如執行synchronized、sleep()、wait()等操作。在接下來的狀態介紹中還會提到許多和RUNNABLE相關的狀態轉換關係。
不過就Java本身層麵的RUNNABLE狀態來講並不代表它一定處於運行中的狀態例如在BIO中線程正阻塞在網絡等待時看到的狀態依然是RUNNABLE狀態而在底層線程已經被阻塞這也是Java內在一些狀態不協調的問題所在。所以我們不僅僅要看狀態本身還得了解更多的計算機與Java之間的關係才能在麵對問題時更加接近本質。
3BLOCKED狀態

BLOCKED稱為阻塞狀態或者說線程已經被掛起它“睡著”了原因通常是它在等待一個“鎖”當某個synchronized正好有線程在使用時一個線程嚐試進入這個臨界區就會被阻塞直到另一個線程走完臨界區或發生了相應鎖對象的wait()操作後它才有機會去爭奪進入臨界區的權利。
細節補充synchronized會有各種粒度的問題這裏的臨界區是指多個線程嚐試進入同一塊資源區域這個區域在Java代碼中的體現方式通常是基於某個對象鎖代碼片段。關於它的一些細節將在後文中詳細介紹。
爭取到鎖的權利後才會從BLOCKEN狀態恢複到RUNNABLE狀態如果在征用鎖的過程中沒有搶到那麼它就又要回到休息室去等待了。
在實際的工作中BLOCKEN狀態也並非顯式地存在於synchronized上可能會是一種嵌套隱藏的方式例如使用了某種三方控件、集合類。
一旦線程處於阻塞狀態線程就像真的什麼也不做一樣在Java層麵始終無法喚醒它。許多人說現在用interrupt()方法來喚醒它小夥伴們可以進行小測試一點用處都沒有因為interrupt()隻是在裏麵做一個標記而已不會真正喚醒處於阻塞狀態的線程。
所以在程序中出現synchronized時通常會考慮它的粒度問題更要考慮它是否可能會被死鎖的問題。
4WAITING狀態

這種狀態通常是指一個線程擁有對象鎖後進入到相應的代碼區域後調用相應的“鎖對象”的wait()方法操作後產生的一種結果。變相的實現還有LockSupport.park()、LockSupport.parkNanos()、LockSupport.parkUntil()、Thread.join()等它們也是在等待另一個對象事件的發生也就是描述了等待的意思。
上麵提到的BLOCKEN狀態也是等待的意思它們有什麼關係與區別呢
其實BLOCKEN是虛擬機認為程序還不能進入某個區域因為同時進去就會有問題這是一塊臨界區。發生wait()操作的先決條件是要進入臨界區也就是線程已經拿到了“門票”自己可能進去做了一些事情但此時通過判定某些業務上的參數由具體業務決定發現還有一些其他配合的資源沒有準備充分那麼自己就等等再做其他的事情。
理解起來是不是很麻煩其實有一個非常典型的案例就是通過wait()和notify()來完成生產者消費者模型當生產者生產過快發現倉庫滿了即消費者還沒有把東西拿走空位資源還沒準備好時生產者就等待有空位再做事情消費者拿走東西時會發出“有空位了”的消息那麼生產者就又開始工作了。反過來也是一樣當消費者消費過快發現沒有存貨時消費者也會等存貨到來生產者生產出內容後發出“有存貨了”的消息消費者就又來搶東西了。
這種通過製衡方式的協調工作機製在工作中用得很多它稍加變化就能產生巨大的價值現代的Java語言很牛已經將這些複雜的細節包裝成了對象對外提供了很好用的API這些API為我們提供的僅僅是簡單的任務內容輸入具體的調度細節由Java來完成。
在這種狀態下如果發生了對該線程的interrupt()是有用的處於該狀態的線程內部會拋出一個InterruptedException異常這個異常應當在run()方法裏麵捕獲使得run()方法正常地執行完成。當然在run()方法內部捕獲異常後還可以讓線程繼續運行這完全是根據具體的應用場景來決定的。
在這種狀態下如果某線程對該鎖對象做了notify()動作那麼將從等待池中喚醒一個線程重新恢複到RUNNABLE狀態。除notify()方法外還有一個notifyAll()方法前者是喚醒一個處於WAITING狀態的線程而後者是喚醒所有的線程。
Object.wait()是否需要死等呢不是除中斷外它還有兩個重構方法
◎ Object.wait(int timeout)傳入的timeout參數是超時的毫秒值超過這個值後會自動喚醒繼續做下麵的操作不會拋出InterruptedException異常但是並不意味著我們不去捕獲因為不排除其他線程會對它做interrupt()動作。
◎ Object.wait(int timeout , int nanos)這是一個更精確的超時設置理論上可以精確到納秒這個納秒值可接受的範圍是0999999因為1000000ns等於1ms。
同樣的LockSupport.park()、LockSupport.parkNanos()、LockSupport.parkUntil()、Thread. join()這些方法都會有類似的重構方法來設置超時達到類似的目的不過此時的狀態不再是WAITING而是TIMED_WAITING。
通常寫代碼的人肯定不想讓程序死掉但是又希望通過這些等待、通知的方式來實現某些平衡這樣就不得不去嚐試采用“超時+重試+失敗告知”等方式來達到目的。
5TIMED_WAITING狀態
相信使用過線程的小夥伴們都應該使用過Thread.sleep()前文中已經提到了通過其他的方式也可以進入這種TIME_WATING狀態。或許可以這種理解當調用Thread.sleep()方法時相當於使用某個時間資源作為鎖對象進而達到等待的目的當時間達到時觸發線程回到工作狀態。
6TERMINATED狀態
線程結束了就處於這種狀態換句話說run()方法走完了線程就處於這種狀態。其實這隻是Java語言級別的一種狀態在操作係統內部可能已經注銷了相應的線程或者將它複用給其他需要使用線程的請求而在Java語言級別隻是通過Java代碼看到的線程狀態而已。
下麵再來探討一些問題。
為什麼wait()和notify()必須要使用synchronized
如果不用就會報錯IllegalMonitorStateException常見的寫法如下
2 |
object.wait();//object.notify();
|
8 |
this.wait();//this.notify();
|
首先要明確wait()和notify()的實現基礎是基於對象存在的。那為什麼要基於對象存在呢
解釋既然要等就要考慮等什麼這裏等待的就是一個對象發出的信號所以要基於對象而存在。
不用對象也可以實現比如suspend()/resume()就不需要但是它們是反麵教材表麵上簡單但是處處都是問題在5.1.4節中會介紹。
理解基於對象的這個道理後目前認為它調用的方式隻能是Object.wait()方法這樣才能和對象掛鉤。但這些東西還與問題“wait()/notify()為什麼必須要使用synchronized”沒有半點關係或者說與對象扯上關係為什麼非要用鎖呢
我們還得繼續探討既然是基於對象的因此它不得不用一個數據結構來存放這些等待的線程而且這個數據結構應當是與該對象綁定的通過查看C++代碼發現該數據結構為一個雙向鏈表此時在這個對象上可能同時有多個線程調用wait()/notify()方法。
在向這個對象所對應的雙向鏈表中寫入、刪除數據時依然存在並發的問題理論上也需要一個鎖來控製。在JVM內核源碼中並沒有發現任何自己用鎖來控製寫入的動作隻是通過檢查當前線程是否為對象的OWNER來判定是否要拋出相應的異常。由此可見它希望該動作由Java程序這個抽象層次來控製它為什麼不想去自己控製鎖呢
因為有些時候更低抽象層次的鎖未必是好事因為這樣的請求對於外部可能是反複循環地去征用或者這些代碼還可能在其他地方複用也許將它粗粒度化會更好一些而且這樣的代碼寫在Java程序中本身也會更加清晰更加容易看到相互之間的關係。
在這個問題上胖哥的解釋就到此結束了其中包含了許多個人的理解有興趣的朋友可以去查閱資料細化這個問題的根源。
interrupt()操作在線程處於BLOCKEN狀態時沒用在其他狀態下都有效嗎
interrupt()操作對線程處於RUNNING狀態時也沒用或者說隻對處於WAITING和TIME_WAITING狀態的線程有用讓它們產生實質性的異常拋出。
在通常情況下如果線程處於運行中狀態也不會讓它中斷如果中斷是成立的則可能會導致正常的業務運行出現問題。另外如果不想用強製手段就得為每條代碼的運行設立檢查但是這個動作很麻煩JVM不願意做這件事情它做interrupt()僅僅是打一個標記此時程序中通過isInterrupt()方法能夠判定是否被發起過中斷操作如果被中斷了那麼如何處理程序就是設計上的事情了。
舉個例子如果代碼運行是一個死循環那麼在循環中可以這樣做
2 |
if(Thread.currentThread.isInterrupt()) {
|
3 |
//可以做類似的break、return拋出InterruptedException達到某種目的這完全由自己決定
|
4 |
//如拋出異常通常包裝一層try catch異常處理進一步做處理如退出run方法或什麼也不做
|
許多小夥伴認為這太麻煩了為什麼不可以自動呢
小夥伴們可以通過一些生活的溝通方式來理解一下當你發現門外麵有人唿叫你時你自己是否搭理他是你的事情胖哥認為這是一種有“愛”的溝通方式反之是暴力地破門而入把你強製“抓”出去的方式。
在JDK 1.6及以後的版本中可以使用線程的interrupted()方法來判定線程是否已經被調用過中斷方法表麵上的效果與isInterrupted()方法的結果一樣不過這個方法是一個靜態方法直接通過Thread.interrupted()調用判定的就是當前線程。除此之外更大的區別在於這個方法調用後將會重新將中斷狀態設置為false這樣方便於循環利用線程而不是中斷後狀態就始終為true就無法將狀態修改回來了。類似的判定線程的相關方法還有isAlive()、isDaemon()分別用來判定線程是否還活著以及是否為後台線程。
5.1.4 反麵教材suspend()、resume()、stop()
雖然是反麵教材但是胖哥認為反麵教材往往體現在自己寫代碼時容易犯錯的地方。隻有看清楚這些反麵教材自己寫代碼時才會去多考慮一些細節性的問題。
suspend()、resume()、stop()這些API雖然Java一直保留著但在代碼中使用時會發現JVM已經不推薦使用了它們都被加上了@Deprecated注解表示它們已經過時了保留隻是為了兼容而已。
關於suspend()/resume()這兩個方法類似於wait()/notify()但是它們不是等待和喚醒線程。通過對它們的實驗會發現suspend()後的線程處於RUNNING狀態而不是WAITING狀態但是線程本身在這裏已經掛起了線程本身的狀態就開始對不上號了。
如果是在synchronized區域內部發生suspend()操作那麼它並不會像發生wait() 那樣把鎖釋放出來因為它自己還在運行中。而當發生resume()時程序正常結束了其實如果代碼正常走過synchronized區域鎖也會釋放的。但是很多資料上講解的是沒有釋放資源這是怎麼回事呢下麵我們就寫個反麵教材的例子。
代碼清單5-2 反麵例子
01 |
public class SuspendAndResume {
|
03 |
private final static Object object = new Object();
|
05 |
static class ThreadA extends Thread {
|
08 |
synchronized(object) {
|
09 |
System.out.println("start...");
|
10 |
Thread.currentThread().suspend();
|
11 |
System.out.println("thread end...");
|
16 |
public static void main(String []args) throws InterruptedException {
|
17 |
ThreadA t1 = new ThreadA();
|
18 |
ThreadA t2 = new ThreadA();
|
22 |
System.out.println(t1.getState());
|
23 |
System.out.println(t2.getState());
|
輸出結果如下

代碼中啟動了兩個子線程這兩個子線程幾乎是同時啟動的main方法所在的線程延遲100ms目的是為了讓兩個子線程都進入運行的區域至少其中一個發生了suspend()操作。
輸出時首先會輸出一個“start…”剛開始也隻會輸出一個“start…”因為這是由synchronized來保證的此時第一個進入synchronized區域的線程調用了suspend()方法此時它停止執行了。
然後輸出的兩個狀態是在main方法中打印出來的因為一個線程在synchronized區域外部等待另一個線程調用了suspend()方法而被掛起這裏輸出的狀態一個是BLOCKED狀態另一個是RUNNABLE多次測試後結果相同說明有一個線程被阻塞了阻塞線程自然在synchronized區域外麵等待進入而一個線程肯定是已經進入synchronized區域的線程並在調用suspend()方法時掛起但是我們看到的狀態是RUNNABLE。
如果去掉synchronized動作將會輸出兩個RUNNABLE但是兩個線程都在suspend()方法時停止執行了這說明什麼呢suspend()/resume()並不需要synchronized的支持因此不需要基於對象。
接下來輸出“thread end…”說明有一個線程正常結束了也說明resume()操作確實生效了在它輸出後緊接著會輸出一個“start…”說明另一個線程進入了synchronized區域但是神奇的事情發生了另一個線程也被主線程調用過resume()方法但實際情況是這個線程在這裏卡住了沒有釋放掉為何
因為在這個例子中main方法所在的線程對第2個進入synchronized區域的線程做的resume()操作很可能發生在它未進入synchronized區域之前也自然發生在它調用suspend()操作之前在線程沒有調用suspend()方法之前調用resume()是無效的也不會使得線程在其後麵調用suspend()方法直接被喚醒。當該線程被掛起時相應持有的鎖就釋放不掉了因為它的操作與鎖無關而外部認為已經將這個線程釋放掉了因為外部看到的狀態是RUNNING而且已經調用過resume()方法了由於這些信息的不一致就導致了各種資源無法釋放的問題。
總的來說問題應當出在線程狀態對外看到的是RUNNING狀態外部程序並不知道這個線程掛起了需要去做resume()操作如果有狀態判定還可以做檢測。另外它並不是基於對象來完成這個動作的因此suspend()和wait()相關的順序性很難保證。所以suspend()/resume()不推薦使用了。
反過來想這也更加說明了wait()和notify()為什麼要基於對象來做數據結構因為它要控製生產者和消費者之間的關係它需要一個臨界區來控製它們之間的平衡。它不是隨意地在線程上做操作來控製資源的而是由資源反過來控製線程狀態的。當然wait()/notify()並非不會導致死鎖隻是它們的死鎖通常是程序設計不當導致的並且在通常情況下是可以通過優化解決的。
關於stop()胖哥認為它和interrupt()最大的區別如下
interrupt()是相對友愛的行為它不是破門而入而stop()卻是這樣的當你發起對某個線程的stop()操作時如果這個線程處於RUNNING狀態stop()將會導致這個線程直接拋出一個java.lang.ThreadDeath的Error。這似乎沒有問題那麼我們就來探討一下是否會有問題。
假如線程是一個死循環被外部容器所複用在業務代碼中會通過多個步驟的計算將某些值賦予線程內的某些屬性或更大作用域的屬性這些屬性可能是多個當發起stop()時程序可能會進入try {} catch(Throwable e)區域但是前麵執行的計算和賦值隻做了一半而且做到那裏沒法找回來這樣就可能會導致業務程序中上下文數據不一致的情況發生。
5.1.5 調度優先級
線程的優先級就是對優先權的level設置就像VIP專區為何要設立VIP呢因為資源有限才會存在特權給予更多所以享有特權。
計算機也是這樣的CPU資源是有限的那麼在某些情況下我們希望先保證某些VIP先被執行。任務沒有高低貴賤之分但是有重要性、緊急性之分因此會設立線程的優先級讓OS根據不同的優先級進行調度這樣在算法策略上就不再是一視同仁“吃大鍋飯”了可以使得調度更加靈活達到局部優化的目的。
線程調度的優先級每個OS有著不同的實現而Java虛擬機為了兼容各種OS平台設定了110個優先級理論上數字越大優先級越高但這並不代表每個OS也有10個優先級某些OS可能隻有3個或5個優先級。因此JVM會在相應的平台上根據實際情況設定110這10個數字與OS的線程優先級做一個映射關係總體會保持順序化。通過這一點大家應該清楚Java中連續的兩個數字所表示的優先級在實際場景中可能是同一個優先級。
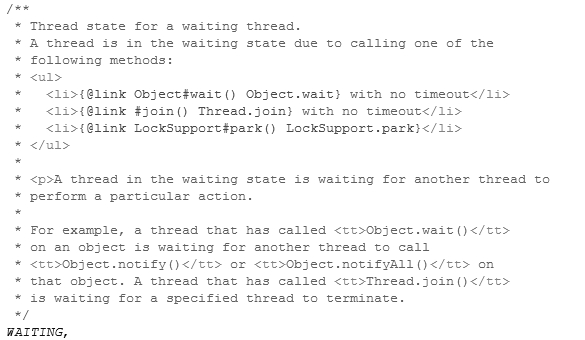
作為程序員使用優先級時又不想脫離Java語言本身的限製通常將優先級設置為“普通”、“最大”、“最小”如圖5-1所示其定義在Thread類中通常不會設置一些細節的數字那樣設置可能根本達不到目的。
![ETKC$57]QEEDJVT_~$]QYVP](https://res.3425.com.cn/aliyunqi/20170523/1495519324741.jpg)
圖5-1 線程優先級代碼截圖
創建一個線程時默認的優先級是Thread.NORM_PRIORITY值為5。在程序中可以為指定線程設定優先級通過setPriority(int)方法來完成調用這個方法時傳入上麵描述的幾種值就基本可以達到調度優先的目的。
在JVM中還有一種特殊的後台線程通過對線程調用setDaemon(boolean)標誌是否為後台線程它通常優先級極低也就是通常不會跟別人搶CPU但是它可能在某些時候提升自己的優先級來做一些事情。例如JVM的GC線程就是後台線程它很多時候不去和業務爭用CPU而是在資源忙時會被提升優先級來做事情。
這類線程貌似與普通線程沒有區別因為普通線程也可以做到這一點。但是後台線程有一個十分重要的特征是如果JVM進程中活著的線程隻剩下後台線程那麼意味著就要結束整個進程。
大家可以做一個實驗來證明這個結論。在一個線程中做死循環main方法啟動這個線程後就結束了此時整個進程不會退出。如果將線程設置為後台線程setDaemon(boolean)當main方法結束後進程會立即結束。本書光盤中的src/chapter05/base/ThreadDaemonTest. java是一個簡單的測試例子大家隻需要將代碼中的setDaemon(true)操作注釋掉或啟用就會得到不同的結果。
5.1.6 線程合並Join
許多同學剛開始學Java多線程時可能不會關注Join這個動作因為不知道它是用來做什麼的而當需要用到類似的場景時卻有可能會說Java沒有提供這種功能。為此胖哥就先說它的一些應用場景再說怎麼用吧。
當我們將一個大任務劃分為多個小任務多個小任務由多個線程去完成時顯然它們完成的先後順序不可能完全一致。在程序中希望各個線程執行完成後將它們的計算結果最終合並在一起換句話說要等待多個線程將子任務執行完成後才能進行合並結果的操作。
這時就可以選擇使用Join了Join可以幫助我們輕鬆地搞定這個問題否則就需要用一個循環去不斷判定每個線程的狀態。
在實際生活中就像把任務分解給多個人去完成其中的各個板塊但老板需要等待這些人全部都完成後才認為這個階段的任務結束了也許每個人的板塊內部和別人還有相互的接口依賴如果對方接口沒有寫好自己的這部分也不算完全完成就會發生類似於合並的動作到底要將任務細化到什麼粒度完全看實際場景和自己對問題的理解。下麵用一段簡單的代碼來說明Join的使用。
代碼清單5-3 Join的例子
01 |
public class ThreadJoinTest {
|
03 |
static class Computer extends Thread {
|
09 |
public Computer(int []array , int start , int end) {
|
16 |
for(int i = start; i < end ; i++) {
|
18 |
if(result < 0) result &= Integer.MAX_VALUE;
|
22 |
public int getResult() {
|
27 |
private final static int COUNTER = 10000000;
|
29 |
public static void main(String []args) throws InterruptedException {
|
30 |
int []array = new int[COUNTER];
|
31 |
Random random = new Random();
|
32 |
for(int i = 0 ; i < COUNTER ; i++) {
|
33 |
array[i] = Math.abs(random.nextInt());
|
35 |
long start = System.currentTimeMillis();
|
36 |
Computer c1 = new Computer(array , 0 , COUNTER / 2);
|
37 |
Computer c2 = new Computer(array , COUNTER / 2 + 1 , COUNTER);
|
42 |
System.out.println(System.currentTimeMillis() - start);
|
43 |
//System.out.println(c1.getResult());
|
44 |
System.out.println((c1.getResult() + c2.getResult())
|
這個例子或許不太好隻是1000萬個隨機數疊加為了防止CPU計算過快在計算中增加一些判定操作最後再將計算完的兩個值輸出也輸出運算時間。如果在有多個CPU的機器上做測試就會發現數據量大時多個線程計算具有優勢但是這個優勢非常小而且在數據量較小的情況下單線程會更快一些。為何單線程可能會更快呢
最主要的原因是線程在分配時就有開銷每個線程的分配過程本身就需要執行很多條底層代碼這些代碼的執行相當於很多條CPU疊加運算的指令Join操作過程還有其他的各種開銷。
如果嚐試將每個線程疊加後做一些其他的操作例如I/O讀寫、字符串處理等操作多線程的優勢一下子就出來了因為這樣總體計算下來後線程的創建時間是可以被忽略的所以我們在考量係統的綜合性能時不能就一個點或某種測試就輕易得出一個最終結論一定要考慮更多的變動因素。
要模擬單線程做許多相對時間較長的操作也不一定非要用文件讀寫、字符串處理等操作這樣設計測試比較麻煩由於已經知道了關鍵點在於運行時間與線程創建時間的比重所以可以讓每個線程循環時休眠一個隨機的毫秒值這個時間其實不需要太長例如10ms、20ms、30ms就可以模擬出效果了。
但這並不代表多線程就一定能提升效率首先要檢測CPU是不是多核如果不是那麼使用多線程帶來更多的是上下文切換的開銷多線程操作的共享對象還會有鎖瓶頸否則就是非線程安全的。
綜合考量各種開銷因素、時間、空間最後利用大量的場景測試來證明推理是有指導性的如果隻是一味地為了用多線程而使用多線程則往往很多事情可能會適得其反。
Join隻是語法層麵的線程合並其實它更像是當前線程處於BLOCKEN狀態時去等待其他線程結束的事件而且是逐個去Join。換句話說Join的順序並不一定是線程真正結束的順序要保證線程結束的順序性它還無法實現即使在本例中它也不是唯一的實現方式本章後麵會提到許多基於並發編程工具的方式來實現會更加理想管理也會更加體係化能適應更多的業務場景需求。
5.1.7 線程補充小知識
本小節的內容是一些小例子簡單地講解線程棧的獲取以及UncaughtExceptionHandler的簡單使用大家隻需要對照本書光盤中的例子來運行以及本書的相應講解就會清楚這些小例子的用途和意義。
1線程棧的獲取
在前文中多次提到過棧尤其在第3章中介紹BTrace時通過BTraceUtils的jstack()方法就可以輸出調用棧信息。由此我們知道了代碼切入是怎麼回事但是線程棧如何獲取呢其實很簡單請看下麵的例子。
代碼清單5-4 獲取線程棧的簡單例子
01 |
public class ThreadStackTest {
|
03 |
public static void main(String []args) {
|
04 |
printStack(getStackByThread());
|
05 |
printStack(getStackByException());
|
08 |
private static void printStack(StackTraceElement []stacks) {
|
09 |
for(StackTraceElement stack : stacks) {
|
10 |
System.out.println(stack);
|
12 |
System.out.println("\n");
|
15 |
private static StackTraceElement[] getStackByThread() {
|
16 |
return Thread.currentThread().getStackTrace();
|
19 |
private static StackTraceElement[] getStackByException() {
|
20 |
return new Exception().getStackTrace();
|
這樣就通過兩種方式輸出線程棧了
這麼簡單
不信我們就看看輸出結果
1 |
java.lang.Thread.getStackTrace(Thread.java:1568)
|
2 |
chapter05.base.ThreadStackTest.getStackByThread(ThreadStackTest.java:23)
|
3 |
chapter05.base.ThreadStackTest.main(ThreadStackTest.java:11)
|
5 |
chapter05.base.ThreadStackTest.getStackByException(ThreadStackTest.java:27)
|
6 |
chapter05.base.ThreadStackTest.main(ThreadStackTest.java:12)
|
這和異常信息很像隻是沒有異常類型而已。沒錯在例子中大家也應當看到有通過異常來獲取線程棧的方式。對於該例子大家可以方法套用方法進行多層套用後看看輸出結果會是什麼樣子的。
獲取到的這個線程棧是一個數組數組的順序就是調用代碼的來源路徑數組中的每個元素是一個java.lang.StackTraceElement類型的對象它內部包含了相應的class、方法、文件名、行號信息我們可以通過這些信息來追蹤代碼、監控、定位異常、控製調用來源等。
對於調用來源的類可以通過sun.reflect.Reflection的getCallerClass(int)來獲取在JDK 1.7以後API有少量變化。
2UncaughtExceptionHandler的簡單使用
這是Java本身提供的一種對run()方法沒有捕獲到的異常、錯誤的一次補救在這裏可以吃點後悔藥。通常我們不依賴這種方式因為這是線程級別的業務代碼中通常不會關心這個層次即使要關心也是在框架當中通常我們希望在內層就將該異常處理掉走到這個位置也意味著線程已經脫離了run()方法會立即結束不能再被線程所複用了。
不過從學習Java的角度來講也需要知道Java確實提供了這樣一種機製請看下麵的例子。
代碼清單5-5 UncaughtExceptionHandler的測試
01 |
class TestExceptionHandler implements UncaughtExceptionHandler {
|
03 |
public void uncaughtException(Thread t, Throwable e) {
|
04 |
System.out.printf("線程出現異常");
|
08 |
public class ExceptionHandlerTest {
|
10 |
public static void main(String []args) {
|
11 |
Thread t = new Thread() {
|
13 |
Integer.parseInt("ABC");
|
16 |
t.setUncaughtExceptionHandler(new TestExceptionHandler());
|
17 |
最後更新:2017-05-23 14:02:04
|
![7`M((26P$4H0W]XP7UCS5FN](https://ifeve.com/wp-content/uploads/2014/10/7M26P4H0WXP7UCS5FN.jpg)

![ETKC$57]QEEDJVT_~$]QYVP](https://ifeve.com/wp-content/uploads/2014/10/ETKC57QEEDJVT_QYVP.jpg)