![]() 431
431
![]()
![]() 技術社區[雲棲]
技術社區[雲棲]
《KAFKA官方文檔》入門指南(一)
Apache的Kafka™是一個分布式流平台(a distributed streaming platform)。這到底意味著什麼?
我們認為,一個流處理平台應該具有三個關鍵能力:
- 它可以讓你發布和訂閱記錄流。在這方麵,它類似於一個消息隊列或企業消息係統。
- 它可以讓你持久化收到的記錄流,從而具有容錯能力。
- 它可以讓你處理收到的記錄流。
Kafka擅長哪些方麵?
它被用於兩大類應用:
- 建立實時流數據管道從而能夠可靠地在係統或應用程序之間的共享數據
- 構建實時流應用程序,能夠變換或者對數據
- 進行相應的處理。
想要了解Kafka如何具有這些能力,讓我們從下往上深入探索Kafka的能力。
首先,明確幾個概念:
- Kafka是運行在一個或多個服務器的集群(Cluster)上的。
- Kafka集群分類存儲的記錄流被稱為主題(Topics)。
- 每個消息記錄包含一個鍵,一個值和時間戳。
Kafka有四個核心API:
- 生產者 API 允許應用程序發布記錄流至一個或多個Kafka的話題(Topics)。
- 消費者API允許應用程序訂閱一個或多個主題,並處理這些主題接收到的記錄流。
- Streams API允許應用程序充當流處理器(stream processor),從一個或多個主題獲取輸入流,並生產一個輸出流至一個或多個的主題,能夠有效地變換輸入流為輸出流。
-
Connector API允許構建和運行可重用的生產者或消費者,能夠把 Kafka主題連接到現有的應用程序或數據係統。例如,一個連接到關係數據庫的連接器(connector)可能會獲取每個表的變化。
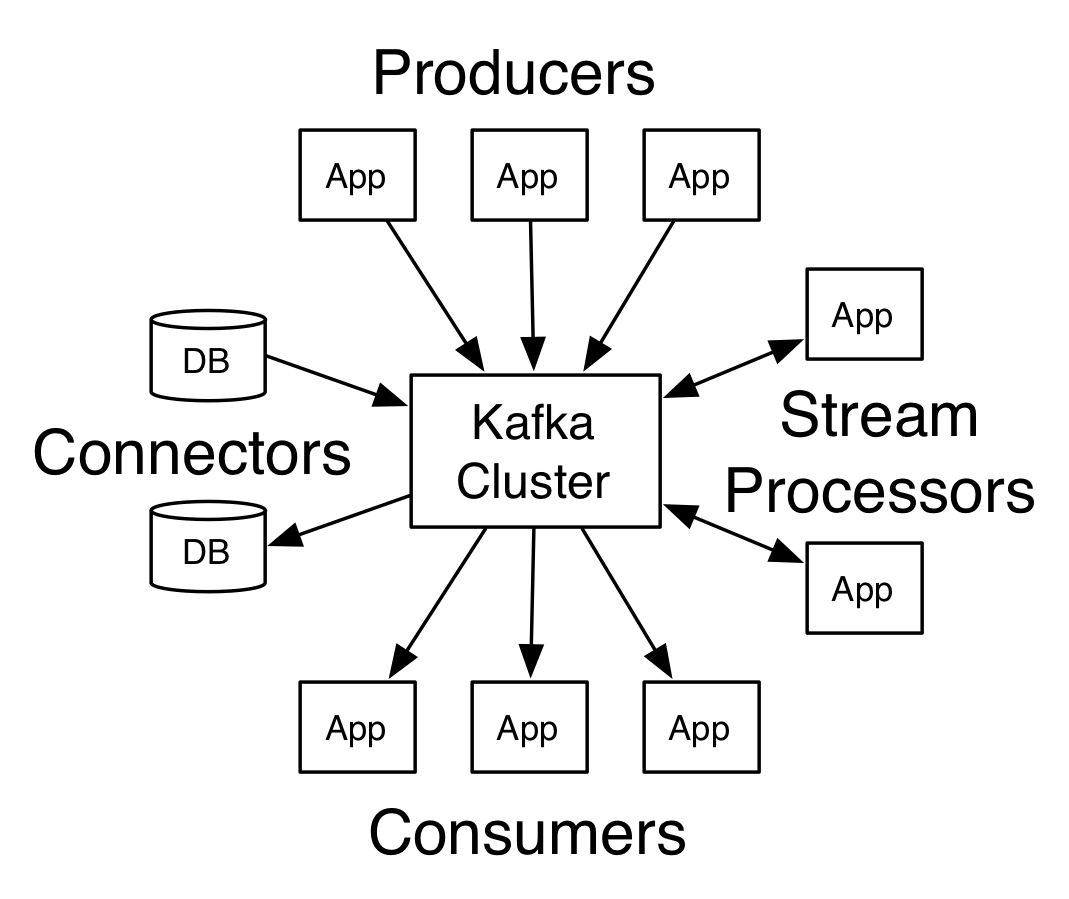
Kafka的客戶端和服務器之間的通信是靠一個簡單的,高性能的,與語言無關的TCP協議完成的。這個協議有不同的版本,並保持向後兼容舊版本(向前兼容舊版本?)。Kafka不光提供了一個Java客戶端,還有許多語言版本的客戶端。
讓我們先來了解Kafka的核心抽象概念記錄流 – 主題。
主題是一種分類或發布的一係列記錄的名義上的名字。Kafka的主題始終是支持多用戶訂閱的; 也就是說,一個主題可以有零個,一個或多個消費者訂閱寫入的數據。
對於每一個主題,Kafka集群保持一個分區日誌文件,看下圖:
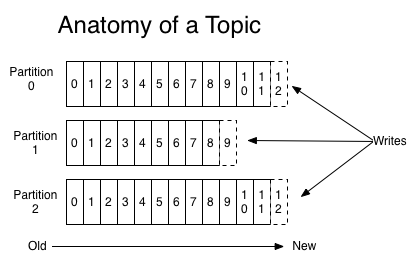
每個分區是一個有序的,不可變的消息序列,新的消息不斷追加到這個有組織的有保證的日誌上。分區會給每個消息記錄分配一個順序ID號 – 偏移量, 能夠唯一地標識該分區中的每個記錄。
Kafka集群保留所有發布的記錄,不管這個記錄有沒有被消費過,Kafka提供可配置的保留策略去刪除舊數據(還有一種策略根據分區大小刪除數據)。例如,如果將保留策略設置為兩天,在記錄公布後兩天,它可用於消費,之後它將被丟棄以騰出空間。Kafka的性能跟存儲的數據量的大小無關, 所以將數據存儲很長一段時間是沒有問題的。
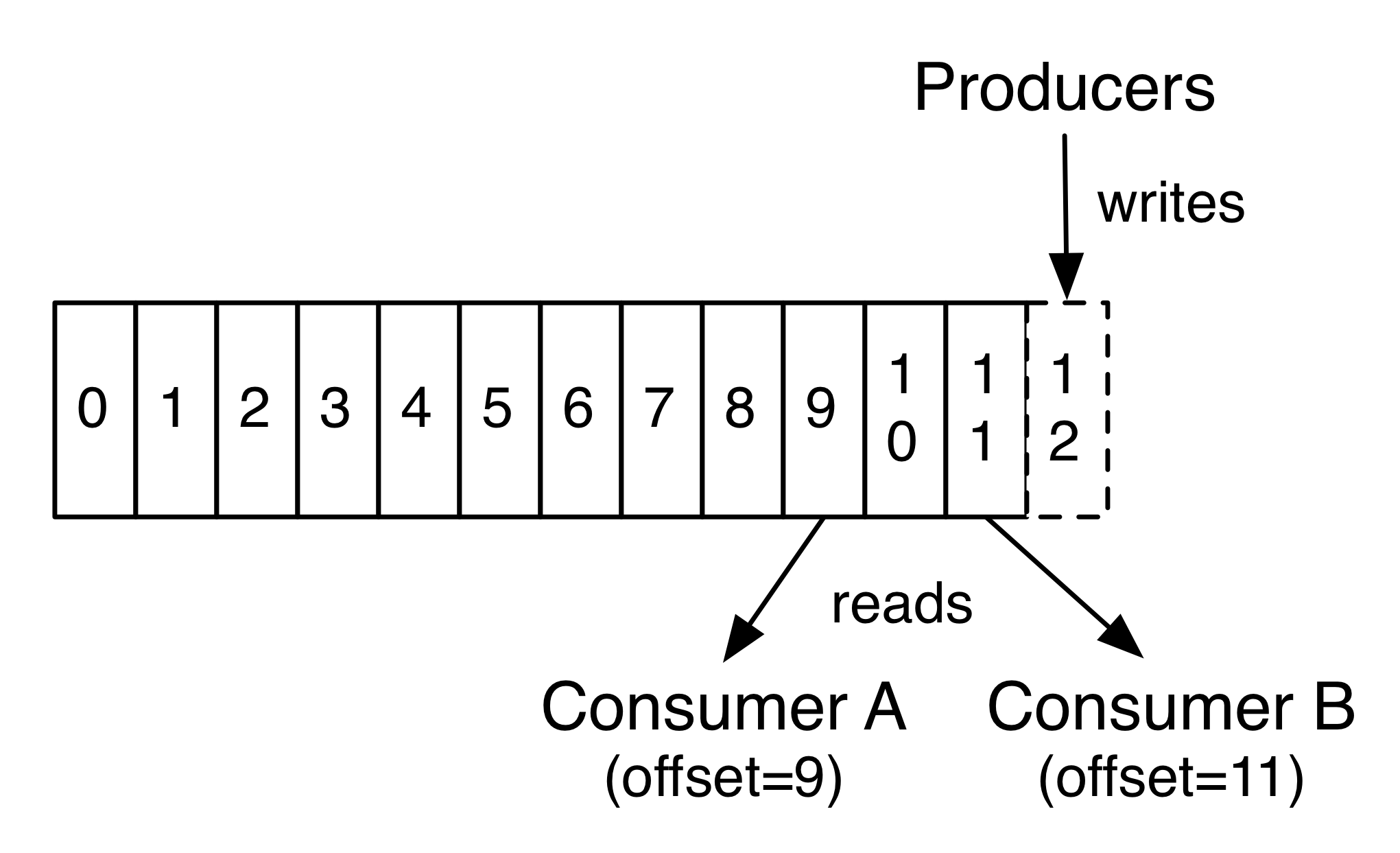
事實上,保留在每個消費者元數據中的最基礎的數據就是消費者正在處理的當前記錄的偏移量(offset)或位置(position)。這種偏移是由消費者控製:通常偏移會隨著消費者讀取記錄線性前進,但事實上,因為其位置是由消費者進行控製,消費者可以在任何它喜歡的位置讀取記錄。例如,消費者可以恢複到舊的偏移量對過去的數據再加工或者直接跳到最新的記錄,並消費從“現在”開始的新的記錄。
這些功能的結合意味著,實現Kafka的消費者的代價都是很小的,他們可以增加或者減少而不會對集群或其他消費者有太大影響。例如,你可以使用我們的命令行工具去追隨任何主題,而且不會改變任何現有的消費者消費的記錄。
數據日誌的分區,一舉數得。首先,它們允許數據能夠擴展到更多的服務器上去。每個單獨的分區的大小受到承載它的服務器的限製,但一個話題可能有很多分區,以便它能夠支持海量的的數據。其次,更重要的意義是分區是進行並行處理的基礎單元。
分布式
日誌的分區會跨服務器的分布在Kafka集群中,每個服務器會共享分區進行數據請求的處理。每個分區可以配置一定數量的副本分區提供容錯能力。
每個分區都有一個服務器充當“leader”和零個或多個服務器充當“followers”。 leader處理所有的讀取和寫入分區的請求,而followers被動的從領導者拷貝數據。如果leader失敗了,followers之一將自動成為新的領導者。每個服務器可能充當一些分區的leader和其他分區的follower,這樣的負載就會在集群內很好的均衡分配。
生產者發布數據到他們所選擇的主題。生產者負責選擇把記錄分配到主題中的哪個分區。這可以使用輪詢算法( round-robin)進行簡單地平衡負載,也可以根據一些更複雜的語義分區算法(比如基於記錄一些鍵值)來完成。
消費者以消費群(consumer group )的名稱來標識自己,每個發布到主題的消息都會發送給訂閱了這個主題的消費群裏麵的一個消費者的一個實例。消費者的實例可以在單獨的進程或單獨的機器上。
如果所有的消費者實例都屬於相同的消費群,那麼記錄將有效地被均衡到每個消費者實例。
如果所有的消費者實例有不同的消費群,那麼每個消息將被廣播到所有的消費者進程。
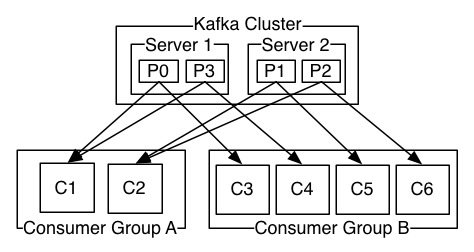
兩個服務器的Kafka集群具有四個分區(P0-P3)和兩個消費群。A消費群有兩個消費者,B群有四個。
更常見的是,我們會發現主題有少量的消費群,每一個都是“邏輯上的訂閱者”。每組都是由很多消費者實例組成,從而實現可擴展性和容錯性。這隻不過是發布 – 訂閱模式的再現,區別是這裏的訂閱者是一組消費者而不是一個單一的進程的消費者。
Kafka消費群的實現方式是通過分割日誌的分區,分給每個Consumer實例,使每個實例在任何時間點的都可以“公平分享”獨占的分區。維持消費群中的成員關係的這個過程是通過Kafka動態協議處理。如果新的實例加入該組,他將接管該組的其他成員的一些分區; 如果一個實例死亡,其分區將被分配到剩餘的實例。
Kafka隻保證一個分區內的消息有序,不能保證一個主題的不同分區之間的消息有序。分區的消息有序與依靠主鍵進行數據分區的能力相結合足以滿足大多數應用的要求。但是,如果你想要保證所有的消息都絕對有序可以隻為一個主題分配一個分區,雖然這將意味著每個消費群同時隻能有一個消費進程在消費。
保證
Kafka提供了以下一些高級別的保證:
- 由生產者發送到一個特定的主題分區的消息將被以他們被發送的順序來追加。也就是說,如果一個消息M1和消息M2都來自同一個生產者,M1先發,那麼M1將有一個低於M2的偏移,會更早在日誌中出現。
- 消費者看到的記錄排序就是記錄被存儲在日誌中的順序。
- 對於副本因子N的主題,我們將承受最多N-1次服務器故障切換而不會損失任何的已經保存的記錄。
對這些保證的更多細節可以參考文檔的設計部分。
如何將Kafka的流的概念和傳統的企業信息係統作比較?
消息處理模型曆來有兩種:隊列和發布-訂閱。在隊列模型中,一組消費者可以從服務器讀取記錄,每個記錄都會被其中一個消費者處理; 在發布-訂閱模式裏,記錄被廣播到所有的消費者。這兩種模式都具有一定的優點和弱點。隊列的優點是它可以讓你把數據分配到多個消費者去處理,它可以讓您擴展你的處理能力。不幸的是,隊列不支持多個訂閱者,一旦一個進程讀取了數據,這個數據就會消失。發布-訂閱模式可以讓你廣播數據到多個進程,但是因為每一個消息發送到每個訂閱者,沒辦法對訂閱者處理能力進行擴展。
Kafka的消費群的推廣了這兩個概念。消費群可以像隊列一樣讓消息被一組進程處理(消費群的成員),與發布 – 訂閱模式一樣,Kafka可以讓你發送廣播消息到多個消費群。
Kafka的模型的優點是,每個主題都具有這兩個屬性,它可以擴展處理能力,也可以實現多個訂閱者,沒有必要二選一。
Kafka比傳統的消息係統具有更強的消息順序保證的能力。
傳統的消息隊列的消息在隊列中是有序的,多個消費者從隊列中消費消息,服務器按照存儲的順序派發消息。然而,盡管服務器是按照順序派發消息,但是這些消息記錄被異步傳遞給消費者,消費者接收到的消息也許已經是亂序的了。這實際上意味著消息的排序在並行消費中都將丟失。消息係統通常靠 “排他性消費”( exclusive consumer)來解決這個問題,隻允許一個進程從隊列中消費,當然,這意味著沒有並行處理的能力。
Kafka做的更好。通過一個概念:並行性-分區-主題實現主題內的並行處理,Kafka是能夠通過一組消費者的進程同時提供排序保證和負載均衡。每個主題的分區指定給每個消費群中的一個消費者,使每個分區隻由該組中的一個消費者所消費。通過這樣做,我們確保消費者是一個分區唯一的讀者,從而順序的消費數據。因為有許多的分區,所以負載還能夠均衡的分配到很多的消費者實例上去。但是請注意,一個消費群的消費者實例不能比分區數量多。
Kafka作為存儲係統
任何消息隊列都能夠解耦消息的生產和消費,還能夠有效地存儲正在傳送的消息。Kafka與眾不同的是,它是一個非常好的存儲係統。
Kafka把消息數據寫到磁盤和備份分區。Kafka允許生產者等待返回確認,直到副本複製和持久化全部完成才認為成功,否則則認為寫入服務器失敗。
Kafka使用的磁盤結構很好擴展,Kafka將執行相同的策略不管你是有50 KB或50TB的持久化數據。
由於存儲的重要性,並允許客戶控製自己的讀取位置,你可以把Kafka認為是一種特殊用途的分布式文件係統,致力於高性能,低延遲的有保障的日誌存儲,能夠備份和自我複製。
Kafka流處理
隻是讀,寫,以及儲存數據流是不夠的,目的是能夠實時處理數據流。
在Kafka中,流處理器是從輸入的主題連續的獲取數據流,然後對輸入進行一係列的處理,並生產連續的數據流到輸出主題。
例如,零售應用程序可能需要輸入銷售和出貨量,根據輸入數據計算出重新訂購的數量和調整後的價格,然後輸出到主題。
這些簡單處理可以直接使用生產者和消費者的API做到。然而,對於更複雜的轉換Kafka提供了一個完全集成的流API。這允許應用程序把一些重要的計算過程從流中剝離或者加入流一起。
這種設施可幫助解決這類應用麵臨的難題:處理雜亂的數據,改變代碼去重新處理輸入,執行有狀態的計算等
流API建立在Kafka提供的核心基礎單元之上:它使用生產者和消費者的API進行輸入輸出,使用Kafka存儲有狀態的數據,並使用群組機製在一組流處理實例中實現容錯。
最後更新:2017-05-18 20:34:36