![]() 1003
1003
![]()
![]() 财经资讯
财经资讯
特征工程__使用手册(new)_机器学习-阿里云
特征工程
目录
主成分分析
- PCA 利用主成分分析方法,实现降维和降维的功能. PCA算法原理见wiki
- 目前支持稠密数据格式
PAI 命令
PAI -name PrinCompAnalysis-project algo_public-DinputTableName=bank_data-DeigOutputTableName=pai_temp_2032_17900_2-DprincompOutputTableName=pai_temp_2032_17900_1-DselectedColNames=pdays,previous,emp_var_rate,cons_price_idx,cons_conf_idx,euribor3m,nr_employed-DtransType=Simple-DcalcuType=CORR-DcontriRate=0.9;
算法参数说明
| 参数名称 | 参数描述 | 参数值可选项 | 默认值 |
|---|---|---|---|
| inputTableName | 必选,进行主成分分析的输入表 | - | - |
| eigOutputTableName | 必选,特征向量与特征值的输出表 | - | - |
| princompOutputTableName | 必选,进行主成分降维降噪后的结果输出表 | - | - |
| selectedColNames | 必选,参与主成分分析运算的特征列 | - | - |
| transType | 可选,原表转换为主成分表的方式,支持Simple, Sub-Mean, Normalization | - | Simple |
| calcuType | 可选,对原表进行特征分解的方式,支持 CORR/COVAR_SAMP/COVAR_POP | - | CORR |
| contriRate | 可选,降维后数据信息保留的百分比 | - | 0.9 |
| remainColumns | 可选,降维表保留原表的字段 | - | - |
PCA输出示例
降维后的数据表
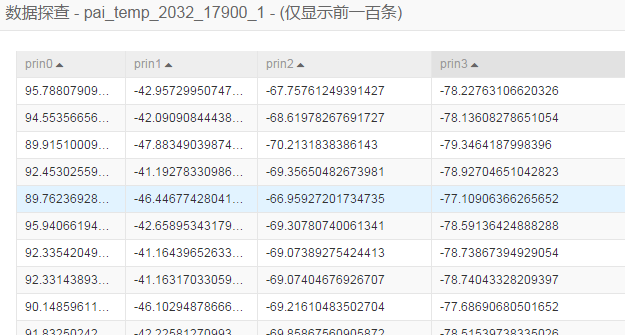
特征值和特征向量表

特征规范
功能说明
- 根据用户选择需要规范特征,采用Min-Max或者ZScore进行规范化。默认情况下 支持稀疏和稠密特征数据自动化筛选需要规范化的Top10特征(按照标准差大小筛选)
PAI 命令
PAI -name fe_normlize_runner -project algo_public-DnormTopN=10-Dlifecycle=28 -DnormCols=nr_employed-DnormMethod=minmax-DinputTable=pai_dense_10_1-DoutputTable=pai_temp_2262_22605_1;
参数说明
| 参数名称 | 参数描述 | 参数值可选项 | 默认值 |
|---|---|---|---|
| inputTable | 必选,输入表的表名 | - | - |
| inputTablePartitions | 可选,输入表中指定哪些分区参与训练,格式为: partition_name=value。如果是多级,格式为name1=value1/name2=value2;如果指定多个分区,中间用’,’分开 | - | 输入表的所有partition |
| outputTable | 必选,规范化后结果表 | - | - |
| normCols | 必选 需要规范的特征,如果是稀疏特征会自动化筛选 | - | |
| labelCol | 可选, 标签字段,如果设该签列,可视化特征到目标变量的x-y分布直方图 | - | - |
| categoryCols | 可选,将勾选的字段视作枚举特征处理 | “” | |
| normMethod | 可选,特征规范方法,默认zscore 目前支持:minmax,zscore | zscore | |
| normTopN | 挑选的TopN个需要规范的特征特征,默认10 | 10 | |
| isSparse | 是否是k:v的稀疏特征,可选,默认稠密数据 | 100 | |
| itemSpliter | 稀疏特征item分隔符,可选,默认逗号 | “,” | |
| kvSpliter | 稀疏特征item分隔符,可选,默认冒号 | “:” | |
| lifecycle | 结果表生命周期,可选,默认7 | 7 |
建模示例
输入数据
create table if not exists pai_dense_10_1 asselectnr_employedfrom bank_data limit 10;
| nr_employed |
|---|
| 5228.1 |
| 5195.8 |
| 4991.6 |
| 5099.1 |
| 5076.2 |
| 5228.1 |
| 5099.1 |
| 5099.1 |
| 5076.2 |
| 5099.1 |
参数配置
输入数据为pai_dense_10_1, 串联特征规范组件,规范特征勾选nr_employed ,配置规范方法是Min-Max,运行
运行结果
| nr_employed |
|---|
| 0.045236319121669435 |
| 0.03905816644670144 |
| 0.0 |
| 0.02056196323712247 |
| 0.01618178688242372 |
| 0.045236319121669435 |
| 0.02056196323712247 |
| 0.02056196323712247 |
| 0.01618178688242372 |
| 0.02056196323712247 |
特征尺度变换
功能说明
- 支持常见的 尺度变化函数 log2,log10,ln,abs,sqrt。支持 稠密或稀疏
PAI 命令
PAI -name fe_scale_runner -project algo_public-Dlifecycle=28-DscaleMethod=log2-DscaleCols=nr_employed-DinputTable=pai_dense_10_1-DoutputTable=pai_temp_2262_20380_1;
算法参数
| 参数名称 | 参数描述 | 参数值可选项 | 默认值 |
|---|---|---|---|
| inputTable | 必选,输入表的表名 | - | - |
| inputTablePartitions | 可选,输入表中指定哪些分区参与训练,格式为: partition_name=value。如果是多级,格式为name1=value1/name2=value2;如果指定多个分区,中间用’,’分开 | - | 输入表的所有partition |
| outputTable | 必选,尺度缩放后结果表 | - | - |
| scaleCols | 必选,勾选需要缩放的特征,稀疏特征自动化筛选,只能勾选数值类特征 | - | |
| labelCol | 可选, 标签字段,如果设该签列,可视化特征到目标变量的x-y分布直方图 | - | - |
| categoryCols | 可选,将勾选的字段视作枚举特征处理,不支持缩放 | “” | |
| scaleMethod | 可选,缩放方法,默认log2, 支持 log2,log10,ln,abs,sqrt | SameDistance | |
| scaleTopN | 当scaleCols没有勾选时,自动挑选的TopN个需要缩放特征特征,默认10 | 10 | |
| isSparse | 是否是k:v的稀疏特征,可选,默认稠密数据 | 100 | |
| itemSpliter | 稀疏特征item分隔符,可选,默认逗号 | “,” | |
| kvSpliter | 稀疏特征item分隔符,可选,默认冒号 | “:” | |
| lifecycle | 结果表生命周期,可选,默认7 | 7 |
实例
输入数据
create table if not exists pai_dense_10_1 asselectnr_employedfrom bank_data limit 10;
参数配置
勾选nr_employed 做特征尺度变化的特征,只支持数值类特征尺度变化函数,勾选log2
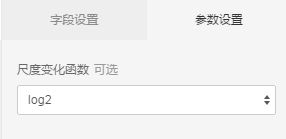
运行结果
| nr_employed |
|---|
| 12.352071021075528 |
| 12.34313018339218 |
| 12.285286613666395 |
| 12.316026916036957 |
| 12.309533196497519 |
| 12.352071021075528 |
| 12.316026916036957 |
| 12.316026916036957 |
| 12.309533196497519 |
| 12.316026916036957 |
特征离散
离散模块功能介绍
- 支持 稠密或稀疏的 数值类特征 离散
- 支持 等频离散 和 等距离离散(默认)
pai 命令
PAI -name fe_discrete_runner -project algo_public-DdiscreteMethod=SameFrequecy-Dlifecycle=28-DmaxBins=5-DinputTable=pai_dense_10_1-DdiscreteCols=nr_employed-DoutputTable=pai_temp_2262_20382_1;
算法参数
| 参数名称 | 参数描述 | 参数值可选项 | 默认值 |
|---|---|---|---|
| inputTable | 必选,输入表的表名 | - | - |
| inputTablePartitions | 可选,输入表中指定哪些分区参与训练,格式为: partition_name=value。如果是多级,格式为name1=value1/name2=value2;如果指定多个分区,中间用’,’分开 | - | 输入表的所有partition |
| outputTable | 必选,离散后结果表 | - | - |
| discreteCols | 必选,勾选需要离散的特征,如果是稀疏特征自动化筛选 | “” | |
| labelCol | 可选, 标签字段,如果设该签列,可视化特征到目标变量的x-y分布直方图 | - | - |
| categoryCols | 可选,将勾选的字段视作枚举特征处理,不支持离散 | “” | |
| discreteMethod | 可选,离散方法,默认SameDistance 目前支持:SameDistance(等距离散), SameFrequecy(等频离散) | SameDistance | |
| discreteTopN | 当discreteCols没有勾选时,自动挑选的TopN个需要离散特征特征,默认10 | 10 | |
| maxBins | 离散区间大小,默认100 | 100 | |
| isSparse | 是否是k:v的稀疏特征,可选,默认稠密数据 | 100 | |
| itemSpliter | 稀疏特征item分隔符,可选,默认逗号 | “,” | |
| kvSpliter | 稀疏特征item分隔符,可选,默认冒号 | “:” | |
| lifecycle | 结果表生命周期,可选,默认7 | 7 |
建模示例
输入数据
create table if not exists pai_dense_10_1 asselectnr_employedfrom bank_data limit 10;
参数配置
输入数据为pai_dense_10_1离散特征勾选 nr_employed,用 等距离离散 方法离散成5个区间, 结果如下

运行结果
| nr_employed |
|---|
| 4.0 |
| 3.0 |
| 1.0 |
| 3.0 |
| 2.0 |
| 4.0 |
| 3.0 |
| 3.0 |
| 2.0 |
| 3.0 |
特征异常平滑
组件功能介绍
- 功能:将输入特征中含有异常的数据平滑到一定区间,支持稀疏和稠密
ps: 特征平滑组件只是将异常取值的特征值修正成正常值,本身不过滤或删除任何记录,输入数据维度和条数都不变.
平滑方法介绍
- Zscore平滑:如果特征分布遵循正态分布,考虑噪音一般集在-3xalpha 和 3xalpha 之外,ZScore是将该范围数据平滑到[-3xalpha,3xalpha]。
eg: 某个特征遵循特征分布,均值为0,标准差为3,因此-10的特征值会被识别为异常而修正为-3x3+0=-9,同理,10会被修正为3x3+0
- 百分位平滑: 将数据分布在[minPer, maxPer]分位之外的数据平滑平滑到minPer/maxPer这两个分位点
eg: age特征取值0-200,设置minPer为0,maxPer为50%,那么在0-100之外的特征取值都会被修正成0或者100
- 阈值平滑: 将数据分布在[minThresh, maxThresh]之外的数据平滑到minThresh和maxThresh这两个数据点.
eg: age特征取值0-200,设置minThresh=10,maxThresh=80,那么在0-80之外的特征取值都会被修正成0或者80
三 pai 命令
PAI -name fe_soften_runner -project algo_public-DminThresh=5000 -Dlifecycle=28-DsoftenMethod=min-max-thresh-DsoftenCols=nr_employed-DmaxThresh=6000-DinputTable=pai_dense_10_1-DoutputTable=pai_temp_2262_20381_1;
四 算法参数
| 参数名称 | 参数描述 | 参数值可选项 | 默认值 |
|---|---|---|---|
| inputTable | 必选,输入表的表名 | - | - |
| inputTablePartitions | 可选,输入表中指定哪些分区参与训练,格式为: partition_name=value。如果是多级,格式为name1=value1/name2=value2;如果指定多个分区,中间用’,’分开 | - | 输入表的所有partition |
| outputTable | 必选,平滑后结果表 | - | - |
| labelCol | 可选, 标签字段,如果设该签列,可视化特征到目标变量的x-y分布直方图 | - | - |
| categoryCols | 可选,将勾选的字段视作枚举特征处理 | “” | |
| softenCols | 必选,勾选需要平滑的特征,但特征是稀疏特征时自动化筛选 | - | |
| softenMethod | 可选,平滑方法,默认zscore 目前支持:min-max-thresh(阈值平滑), min-max-per(百分位平滑) | zscore | |
| softenTopN | 当softenCols没有勾选时,自动挑选的TopN个需要的平滑特征特征,默认10 | 10 | |
| cl | 置信水平,当平滑方法是zscore方生效 | 10 | |
| minPer | 最低百分位,当平滑方法是min-max-thresh方生效 | 0.0 | |
| maxPer | 最高百分位,当平滑方法是min-max-thresh方生效 | 1.0 | |
| minThresh | 阈值最小值,默认-9999,表示不设置, 当平滑方法是min-max-per方生效 | -9999 | |
| maxThresh | 阈值最大值,默认-9999,表示不设置,当平滑方法是min-max-per方生效 | -9999 | |
| isSparse | 是否是k:v的稀疏特征,可选,默认稠密数据 | 100 | |
| itemSpliter | 稀疏特征item分隔符,可选,默认逗号 | “,” | |
| kvSpliter | 稀疏特征item分隔符,可选,默认冒号 | “:” | |
| lifecycle | 结果表生命周期,可选,默认7 | 7 |
五 实例
1. 输入数据
输入数据
create table if not exists pai_dense_10_1 asselectnr_employedfrom bank_data limit 10;
| nr_employed |
|---|
| 5228.1 |
| 5195.8 |
| 4991.6 |
| 5099.1 |
| 5076.2 |
| 5228.1 |
| 5099.1 |
| 5099.1 |
| 5076.2 |
| 5099.1 |
参数配置
平滑特征列勾选nr_employed,参数配置中选择阈值平滑,下限5000,上限6000

运行结果
| nr_employed |
|---|
| 5228.1 |
| 5195.8 |
| 5000.0 |
| 5099.1 |
| 5076.2 |
| 5228.1 |
| 5099.1 |
| 5099.1 |
| 5076.2 |
| 5099.1 |
随机森林特征重要性
组件功能
使用原始数据和随机森林模型,计算特征重要性.
PAI 命令
pai -name feature_importance -project algo_public-DinputTableName=pai_dense_10_10-DmodelName=xlab_m_random_forests_1_20318_v0-DoutputTableName=erkang_test_dev.pai_temp_2252_20319_1-DlabelColName=y- DfeatureColNames="pdays,previous,emp_var_rate,cons_price_idx,cons_conf_idx,euribor3m,nr_employed,age,campaign,poutcome"-Dlifecycle=28 ;
算法参数
| 参数名称 | 参数描述 | 参数值可选项 | 默认值 |
|---|---|---|---|
| inputTableName | 必选,输入表 | - | - |
| outputTableName | 必选,输出表 | - | - |
| labelColName | 必选,label所在的列 | - | - |
| modelName | 必选,输入的模型名 | - | - |
| featureColNames | 可选,输入表选择的特征 | - | 默认除label外的其他列 |
| inputTablePartitions | 可选,输入表选择的分区 | - | 默认选择全表 |
| lifecycle | 可选,输出表的生命周期 | - | 默认不设置 |
| coreNum | 可选,核心数 | - | 默认自动计算 |
| memSizePerCore | 可选,内存数 | - | 默认自动计算 |
实例
训练数据
drop table if exists pai_dense_10_10;creat table if not exists pai_dense_10_10 asselectage,campaign,pdays, previous, poutcome, emp_var_rate, cons_price_idx, cons_conf_idx, euribor3m, nr_employed, yfrom bank_data limit 10;
参数配置
实例流程图如下,数据源为pai_dense_10_10, y列为随机森林的标签列,其他列为特征列,强制转换列勾选age和campaign,表示这两个特征当做枚举特征处理,其他采用默认参数。 运行成功如下
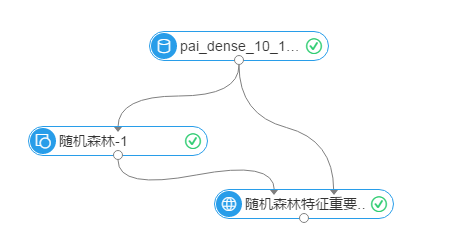
运行结果
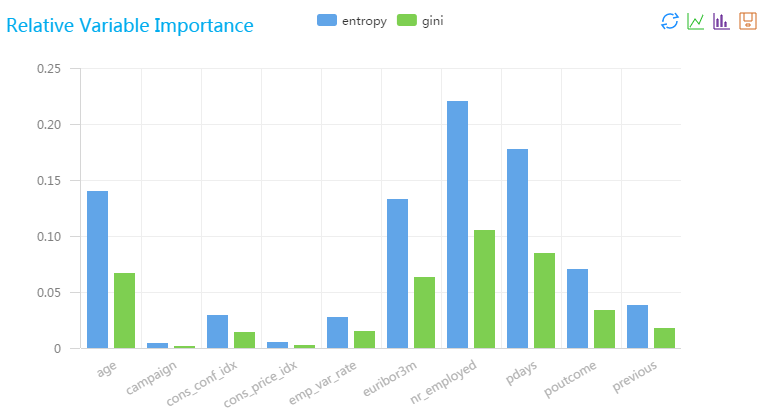
| colname | gini | entropy |
|---|---|---|
| age | 0.06625000000000003 | 0.13978726292803723 |
| campaign | 0.0017500000000000003 | 0.004348515545596772 |
| cons_conf_idx | 0.013999999999999999 | 0.02908409497018851 |
| cons_price_idx | 0.002 | 0.0049804499913461255 |
| emp_var_rate | 0.014700000000000003 | 0.026786360680260933 |
| euribor3m | 0.06300000000000003 | 0.1321936348846039 |
| nr_employed | 0.10499999999999998 | 0.2203227248076733 |
| pdays | 0.0845 | 0.17750329234397513 |
| poutcome | 0.03360000000000001 | 0.07050327193845542 |
| previous | 0.017700000000000004 | 0.03810381005801592 |
随机森林特征重要性组件上 右键查看可视化分析,效果如下所示
GBDT特征重要性
组件功能
计算梯度渐进决策树(GBDT)特征重要性
PAI 命令
pai -name gbdt_importance -project algo_public-DmodelName=xlab_m_GBDT_LR_1_20307_v0-Dlifecycle=28 -DoutputTableName=pai_temp_2252_20308_1 -DlabelColName=y-DfeatureColNames=pdays,previous,emp_var_rate,cons_price_idx,cons_conf_idx,euribor3m,nr_employed,age,campaign-DinputTableName=pai_dense_10_9;
算法参数
| 参数名称 | 参数描述 | 参数值可选项 | 默认值 |
|---|---|---|---|
| inputTableName | 必选,输入表 | - | - |
| outputTableName | 必选,输出表 | - | - |
| labelColName | 必选,label所在的列 | - | - |
| modelName | 必选,输入的模型名 | - | - |
| featureColNames | 可选,输入表选择的特征 | - | 默认除label外的其他列 |
| inputTablePartitions | 可选,输入表选择的分区 | - | 默认选择全表 |
| lifecycle | 可选,输出表的生命周期 | - | 默认不设置 |
| coreNum | 可选,核心数 | - | 默认自动计算 |
| memSizePerCore | 可选,内存数 | - | 默认自动计算 |
实例
输入数据
drop table if exists pai_dense_10_9;create table if not exists pai_dense_10_9 asselectage,campaign,pdays, previous, emp_var_rate, cons_price_idx, cons_conf_idx, euribor3m, nr_employed, yfrom bank_data limit 10;
参数配置
实例流程图如下,输入数据为pai_dense_10_9, GBDT二分类组件选择标签列y,其他字段作为特征列,组件参数配置中叶节点最小样本数配置为1,运行
运行结果
| colname | feature_importance |
|---|---|
| age | 0.004667214954427797 |
| campaign | 0.001962038566773853 |
| cons_conf_idx | 0.04857761873887033 |
| cons_price_idx | 0.01925292649801252 |
| emp_var_rate | 0.044881269590771274 |
| euribor3m | 0.025034606434306696 |
| nr_employed | 0.036085457464908766 |
| pdays | 0.639121250405536 |
| previous | 0.18041761734639272 |
右键查看可视化分析报告

线性模型特征重要性
组件功能
计算线性模型的特征重要性,包括线性回归和二分类逻辑回归。 支持稀疏和稠密。
PAI 命令
PAI -name regression_feature_importance -project algo_public-DmodelName=xlab_m_logisticregressi_20317_v0-DoutputTableName=pai_temp_2252_20321_1-DlabelColName=y-DfeatureColNames=pdays,previous,emp_var_rate,cons_price_idx,cons_conf_idx,euribor3m,nr_employed,age,campaign-DenableSparse=false -DinputTableName=pai_dense_10_9;
算法参数
| 参数名称 | 参数描述 | 参数值可选项 | 默认值 |
|---|---|---|---|
| inputTableName | 必选,输入表 | - | - |
| outputTableName | 必选,输出表 | - | - |
| modelName | 必选,输入的模型名 | - | - |
| labelColName | 必选,label所在列 | - | - |
| feaureColNames | 可选,输入表选择的特征 | - | 默认除label外的其他列 |
| inputTablePartitions | 可选,输入表选择的分区 | - | 默认选全表 |
| enableSparse | 可选,输入表数据是否为稀疏格式 | true, false | false |
| itemDelimiter | 可选,当输入表数据为稀疏格式时,kv间的分割符 | - | 空格 |
| kvDelimiter | 可选,当输入表数据为稀疏格式时,key和value的分割符 | - | 冒号 |
| lifecycle | 可选,输出表的生命周期 | - | 默认不设置 |
| coreNum | 可选,核心数 | - | 默认自动计算 |
| memSizePerCore | 可选,内存数 | - | 默认自动计算 |
实例
输入数据
create table if not exists pai_dense_10_9 asselectage,campaign,pdays, previous, emp_var_rate, cons_price_idx, cons_conf_idx, euribor3m, nr_employed, yfrom bank_data limit 10;
参数配置
建模流程如下图示, 逻辑回归多分类组件选择标签列为y,其他字段为特征列,其他参数默认,运行
运行效果
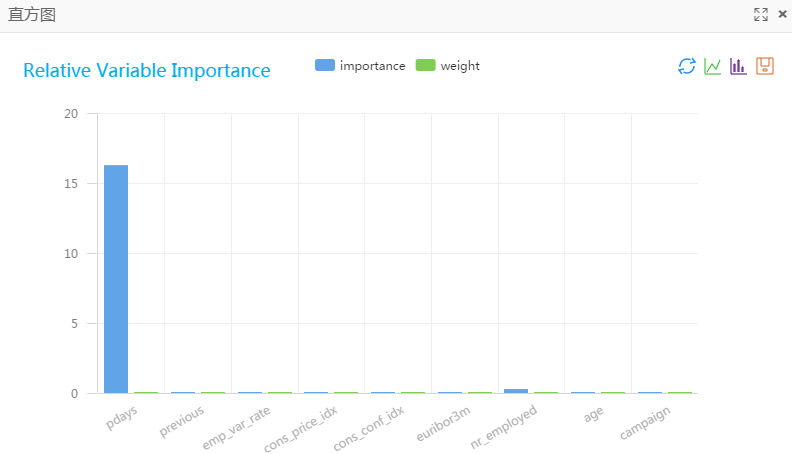
| colname | weight | importance |
|---|---|---|
| pdays | 0.033942600256583334 | 16.31387797440866 |
| previous | 0.00004248130342485344 | 0.000030038817725357177 |
| emp_var_rate | 0.00006720242617694611 | 0.00010554561260753949 |
| cons_price_idx | 0.00012311047229142307 | 0.00006581255124425219 |
| cons_conf_idx | 0.00017227965471819213 | 0.0008918770542818432 |
| euribor3m | 0.00006113758212679113 | 0.00010427128177450988 |
| nr_employed | 0.0034541377310490697 | 0.26048098230126043 |
| age | 0.00009618162708080744 | 0.0009267659744232966 |
| campaign | 0.000019142551785274455 | 0.000041793353660529855 |
指标计算公式
| 列名 | 公式 | |
|---|---|---|
| weight | abs(w_) | |
| importance | abs(w_j) * STD(f_i) |
在线性模型特征重要性组件上,右键查看可视化分析
偏好计算
功能介绍
- 给定用户的明细行为特征数据,自动计算用户对特征值的偏好得分.
- 输入表包含用户id和用户明细行为特征输入,假设在口碑到店场景,某用户2088xxx1在3个月内吃了两次川菜,一次西式快餐,那么输入表形式如下:
| user_id | cate |
|---|---|
| 2088xxx1 | 川菜 |
| 2088xxx1 | 川菜 |
| 2088xxx1 | 西式快餐 |
- 输出表为用户对川菜和西式快餐的偏好得分,形式如下:
| user_id | cate |
|---|---|
| 2088xxx1 | 川菜:0.0544694,西式快餐:0.0272347 |
PAI命令示例
pai -name=preference-project=algo_public-DInputTableName=preference_input_table-DIdColumnName=user_id-DFeatureColNames=cate-DOutputTableName=preference_output_table-DmapInstanceNum=2-DreduceInstanceNum=1;
算法参数
| 参数key名称 | 参数描述 | 必/选填 | 默认值 |
|---|---|---|---|
| InputTableName | 输入表名 | 必填 | - |
| IdColumnName | 用户id列 | 必填 | - |
| FeatureColNames | 用户特征列 | 必填 | - |
| OutputTableName | 输出表名 | 必填 | - |
| OutputTablePartitions | 输出表分区 | 选填 | - |
| mapInstanceNum | mapper数量 | 选填 | 2 |
| reduceInstanceNum | reducer数量 | 选填 | 1 |
实例
测试数据
新建数据SQL
drop table if exists preference_input_table;create table preference_input_table asselect*from(select '2088xxx1' as user_id, '川菜' as cate from alipaydw.dualunion allselect '2088xxx1' as user_id, '川菜' as cate from alipaydw.dualunion allselect '2088xxx1' as user_id, '西式快餐' cate from alipaydw.dualunion allselect '2088xxx3' as user_id, '川菜' as cate from alipaydw.dualunion allselect '2088xxx3' as user_id, '川菜' as cate from alipaydw.dualunion allselect '2088xxx3' as user_id, '西式快餐' as cate from alipaydw.dual) tmp;
运行结果
+------------+------------+| user_id | cate |+------------+------------+| 2088xxx1 | 川菜:0.0544694,西式快餐:0.0272347 || 2088xxx3 | 川菜:0.0544694,西式快餐:0.0272347 |+------------+------------+
过滤式特征选择
组件功能
根据用户不同的特征选择方法,选择并过滤出TopN的特征数据,同时保存所有特征重要性表(右输出)。支持稀疏和稠密数据
PAI 命令
PAI -name fe_select_runner -project algo_public-DfeatImportanceTable=pai_temp_2260_22603_2-DselectMethod=iv-DselectedCols=pdays,previous,emp_var_rate,cons_price_idx,cons_conf_idx,euribor3m,nr_employed,age,campaign-DtopN=5-DlabelCol=y-DmaxBins=100-DinputTable=pai_dense_10_9-DoutputTable=pai_temp_2260_22603_1;
算法参数
| 参数名称 | 参数描述 | 参数值可选项 | 默认值 |
|---|---|---|---|
| inputTable | 必选,输入表的表名 | - | - |
| inputTablePartitions | 可选,输入表中指定哪些分区参与训练,格式为: partition_name=value。如果是多级,格式为name1=value1/name2=value2;如果指定多个分区,中间用’,’分开 | - | 输入表的所有partition |
| outputTable | 必选,过滤后的特征结果表 | - | - |
| featImportanceTable | 必选,存放所有输入特征的重要性权重值 | - | - |
| selectedCols | 必选,特征列 | - | - |
| labelCol | 必选,标签列/目标列 | - | - |
| categoryCols | 存在在Int或者Double字符的枚举特征,可选 | “” | |
| maxBins | 连续类特征划分最大区间数,可选 | 100 | |
| selectMethod | 特征选择方法,可选,默认iv 目前支持:iv(Information Value),Gini增益,信息增益,Lasso | iv,GiniGain,InfoGain,Lasso | iv |
| topN | 挑选的TopN个特征,如果topN答应输入特征数,则输出所有特征,可选,默认10 | 10 | |
| isSparse | 是否是k:v的稀疏特征,可选,默认稠密数据 | 100 | |
| itemSpliter | 稀疏特征item分隔符,可选,默认逗号 | “,” | |
| kvSpliter | 稀疏特征item分隔符,可选,默认冒号 | “:” | |
| lifecycle | 结果表生命周期,可选,默认7 | 7 |
实例
输入数据
create table if not exists pai_dense_10_9 asselectage,campaign,pdays, previous, emp_var_rate, cons_price_idx, cons_conf_idx, euribor3m, nr_employed, yfrom bank_data limit 10;
参数配置
标签列勾选y字段,其他字段勾选为特征列, 特征选择方法选IV,topN特征为5,表示过滤top5的特征
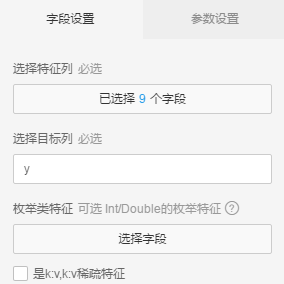
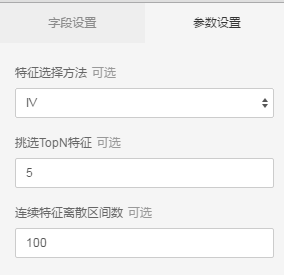
运行结果
左输出是过滤后的数据
| pdays | nr_employed | emp_var_rate | cons_conf_idx | cons_price_idx | y |
|---|---|---|---|---|---|
| 999.0 | 5228.1 | 1.4 | -36.1 | 93.444 | 0.0 |
| 999.0 | 5195.8 | -0.1 | -42.0 | 93.2 | 0.0 |
| 6.0 | 4991.6 | -1.7 | -39.8 | 94.055 | 1.0 |
| 999.0 | 5099.1 | -1.8 | -47.1 | 93.075 | 0.0 |
| 3.0 | 5076.2 | -2.9 | -31.4 | 92.201 | 1.0 |
| 999.0 | 5228.1 | 1.4 | -42.7 | 93.918 | 0.0 |
| 999.0 | 5099.1 | -1.8 | -46.2 | 92.893 | 0.0 |
| 999.0 | 5099.1 | -1.8 | -46.2 | 92.893 | 0.0 |
| 3.0 | 5076.2 | -2.9 | -40.8 | 92.963 | 1.0 |
| 999.0 | 5099.1 | -1.8 | -47.1 | 93.075 | 0.0 |
右输出是特征重要性表
特征重要性表字段结构如下,featureName存放特征名称,weight表示特征选择方法计算出来的权重。
| featname | weight |
|---|---|
| pdays | 30.675544191232486 |
| nr_employed | 29.08332850085075 |
| emp_var_rate | 29.08332850085075 |
| cons_conf_idx | 28.02710269740324 |
| cons_price_idx | 28.02710269740324 |
| euribor3m | 27.829058450563718 |
| age | 27.829058450563714 |
| previous | 14.319325030742775 |
| campaign | 10.658129656314467 |
weight计算公式
| 选择方法 | weght含有 |
|---|---|
| IV | 信息价值 |
| GiniGain | Gini增益 |
| InfoGain | 信息熵增益 |
| Lasso | 线性模型权重绝对值 |
窗口变量统计
功能介绍
- 给定时间窗口,计算相应用户在相应时间窗内的行为次数和金额。如时间窗口为’1,7,30,90,180’,则计算用户相应天数内的行为次数和金额。
PAI命令示例
pai -name=rfm-project=algo_public-DinputTableName=window_input_table-DuserName=user_id-DdtName=dt-DcntName=cnt-DamtName=amt-Dwindow=1,7,30,90-DoutputTableName=window_output_table-DmapInstanceNum=2-DreduceInstanceNum=2;
算法参数
| 参数key名称 | 参数描述 | 必/选填 | 默认值 |
|---|---|---|---|
| inputTableName | 输入表名 | 必填 | - |
| userName | 用户id列 | 必填 | - |
| dtName | 时间列(格式’20160101’) | 必填 | - |
| cntName | 次数列 | 必填 | - |
| amtName | 金额列 | 必填 | - |
| window | 时间窗口(格式为1,7,30,90…) | 必填 | - |
| outputTableName | 输出表名 | 必填 | - |
| outputTablePartitions | 输出表分区 | 选填 | - |
| mapInstanceNum | mapper数量 | 选填 | 2 |
| reduceInstanceNum | reducer数量 | 选填 | 2 |
实例
测试数据
新建数据SQL
drop table if exists window_input_table;create table window_input_table asselect*from(select 'a' as user_id, '20151201' as dt, 2 as cnt, 32.0 as amt from dualunion allselect 'a' as user_id, '20160201' as dt, 3 as cnt, 37.0 as amt from dualunion allselect 'a' as user_id, '20160223' as dt, 1 as cnt, 22.0 as amt from dualunion allselect 'b' as user_id, '20151212' as dt, 1 as cnt, 12.0 as amt from dualunion allselect 'b' as user_id, '20160110' as dt, 2 as cnt, 30.0 as amt from dualunion allselect 'c' as user_id, '20151001' as dt, 3 as cnt, 60.0 as amt from dualunion allselect 'c' as user_id, '20151201' as dt, 2 as cnt, 39.0 as amt from dual) tmp;
运行结果
+------------+------------+------------+------------+------------+-------------+-------------+-------------+-------------+| user_id | cnt_1d_sum | amt_1d_sum | cnt_7d_sum | amt_7d_sum | cnt_30d_sum | amt_30d_sum | cnt_90d_sum | amt_90d_sum |+------------+------------+------------+------------+------------+-------------+-------------+-------------+-------------+| a | 1 | 22.0 | 1 | 22.0 | 4 | 59.0 | 6 | 91.0 || c | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 2 | 39.0 || b | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 3 | 42.0 |+------------+------------+------------+------------+------------+-------------+-------------+-------------+-------------+
one-hot编码
一 功能组件
one-hot编码,也称独热编码,对于每一个特征,如果它有m个可能值,那么经过独热编码后,就变成了m个二元特征。并且,这些特征互斥,每次只有一个激活。因此,数据会变成稀疏的,输出结果也是k:v的稀疏结构。
二 PAI命令
PAI -name fe_binary_runner -project algo_public-DinputTable=one_hot-DbinaryCols=edu_num-DlabelCol=income-DbinaryReserve=false-DbinStrategy=noDealStrategy-DbinaryIndexTable=pai_temp_2458_23436_3-DmodelTable=pai_temp_2458_23436_2-DoutputTable=pai_temp_2458_23436_1-Dlifecycle=28;
三 参数说明
| 参数名称 | 参数描述 | 参数值可选项 | 默认值 |
|---|---|---|---|
| inputTable | 必选,输入表的表名 | - | - |
| inputTablePartitions | 可选,输入表中指定哪些分区参与训练,格式为: partition_name=value。如果是多级,格式为name1=value1/name2=value2;如果指定多个分区,中间用’,’分开 | - | 输入表的所有partition |
| binaryCols | 必选 one-hot编码字段,必须是枚举类特征,字段类型可以是任意类型 | - | |
| binStrategy | 必选,编码策略,本组件提供2种编码策略:简单二值化(noDealStrategy),自动二值化(autoStrategy),分类标签必须设置 | - | |
| labelCol | 分类标签类. 按纯度二值化策略下必选,其他策略下可选 | - | - |
| impurityMergeThresh | 可选,按纯度二值化策略中,前后二值化特征合并,纯度提升阈值 | 0.1 | |
| densityMergeThresh | 可选,按密度二值化策略中,二值化特征密度(占比)合并的阈值 | 0.1 | |
| binaryReserve | 可选, 是否输出表中保留原独热编码特征 | - | - |
| outputTable | 必选,one-hot后的结果表,编码结果保存在kv字段里 | - | - |
| binaryIndexTable | 必选, kv序列化表,编码特征名与kv中Key的映射关系 | - | - |
| modelTable | 必选, one-hot编码的映射逻辑,Json格式存放 | - | - |
| lifecycle | 结果表生命周期,可选,默认7 | 7 |
编码策略
- noDealStrategy: 简单二值化,比如sex特征取值 Female|Male|Unknowed. 那么二值化出来特征是sex_female, sex_male 和 sex_Unknowed
- autoStrategy:自动二值化. 在简单二值化的基础上,利用逻辑回归算法计算每个one-hot特征,将one-hot特征权重为0的特征合并成独立一项,命名other
实例
1 输入数据
| edu_num | income |
|---|---|
| 13 | <=50K |
| 13 | <=50K |
| 9 | <=50K |
| 7 | <=50K |
| 13 | <=50K |
| 14 | <=50K |
| 5 | <=50K |
| 9 | >50K |
| 14 | >50K |
| 13 | >50K |
2. 组件参数
勾选edu_num作为二值化特征, 其他全部采用默认参数,即简单二值化策略,
3. 结果
编码后结果(outputTable)
| income | kv |
|---|---|
| <=50K | 0:1 |
| <=50K | 0:1 |
| <=50K | 4:1 |
| <=50K | 3:1 |
| <=50K | 0:1 |
| <=50K | 1:1 |
| <=50K | 2:1 |
| >50K | 4:1 |
| >50K | 1:1 |
| >50K | 0:1 |
kv的序列列表(binaryIndexTable)
| featname | featindex |
|---|---|
| edu_num | 0 |
| 13 | 0 |
| 14 | 1 |
| 5 | 2 |
| 7 | 3 |
| 9 | 4 |
异常检测
一 组件功能
支持一下功能
针对连续值特征: 按箱线图最大值和最小值检测异常特征.
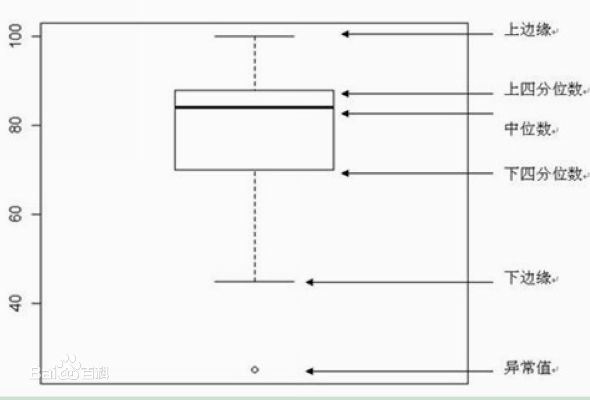
针对枚举值特征: 按照枚举特征的取值频率,按照阈值过滤异常特征
二 PAI 参数
PAI -name fe_detect_runner -project algo_public-DselectedCols="emp_var_rate,cons_price_rate,cons_conf_idx,euribor3m,nr_employed"-Dlifecycle="28"-DdetectStrategy="boxPlot"-DmodelTable="pai_temp_2458_23565_2"-DinputTable="pai_bank_data"-DoutputTable="pai_temp_2458_23565_1";
三 参数说明
| 参数名称 | 参数描述 | 参数值可选项 | 默认值 |
|---|---|---|---|
| inputTable | 必选,输入表的表名 | - | - |
| inputTablePartitions | 可选,输入表中指定哪些分区参与训练,格式为: partition_name=value。如果是多级,格式为name1=value1/name2=value2;如果指定多个分区,中间用’,’分开 | - | 输入表的所有partition |
| selectedCols | 必选 输入特征,字段类型可以是任意类型 | - | |
| detectStrategy | 必选,支持boxPlot和avf 选项,boxPlot是针对连续特征做检测,avf针对枚举类特征做检测 | boxPlot | |
| outputTable | 必选,过滤检测到的异常特征后数据集 | - | - |
| modelTable | 必选, 异常检测模型 | - | - |
| lifecycle | 结果表生命周期,可选,默认7 | 7 |
最后更新:2016-11-17 10:05:00
上一篇: 数据预处理__使用手册(new)_机器学习-阿里云
数据预处理__使用手册(new)_机器学习-阿里云
下一篇: 统计分析__使用手册(new)_机器学习-阿里云
- DescribeHealthStatus__BackendServer相关API_API 参考_负载均衡-阿里云
- Tunnel命令操作__常用命令_基本介绍_大数据计算服务-阿里云
- 批量数据通道概要__SDK介绍_批量数据通道_大数据计算服务-阿里云
- 创建快照__快照_用户指南_云服务器 ECS-阿里云
- 数据表管理__数据管理手册_用户操作指南_大数据开发套件-阿里云
- 签名密钥绑定API__后端签名密钥相关接口_API_API 网关-阿里云
- 事件订阅服务概览__事件订阅_用户指南_云监控-阿里云
- 新建集合__结构管理_DMS for MongoDB_用户指南(NoSQL)_数据管理-阿里云
- 日志服务监控__云服务监控_用户指南_云监控-阿里云
- 是否可以申请一个固定号码进行短信发送?__常见问题_短信服务-阿里云
相关内容
- 常见错误说明__附录_大数据计算服务-阿里云
- 发送短信接口__API使用手册_短信服务-阿里云
- 接口文档__Android_安全组件教程_移动安全-阿里云
- 运营商错误码(联通)__常见问题_短信服务-阿里云
- 设置短信模板__使用手册_短信服务-阿里云
- OSS 权限问题及排查__常见错误及排除_最佳实践_对象存储 OSS-阿里云
- 消息通知__操作指南_批量计算-阿里云
- 设备端快速接入(MQTT)__快速开始_阿里云物联网套件-阿里云
- 查询API调用流量数据__API管理相关接口_API_API 网关-阿里云
- 使用STS访问__JavaScript-SDK_SDK 参考_对象存储 OSS-阿里云