![]() 304
304
![]()
![]() 财经资讯
财经资讯
数据预处理__使用手册(new)_机器学习-阿里云
目录
加权采样
以加权方式生成采样数据;权重列必须为double或int类型,按照该列的value大小采样;如col的值是1.2和1.0;则value=1.2所属样本的被采样的概率就大一些。
参数设置
参数框
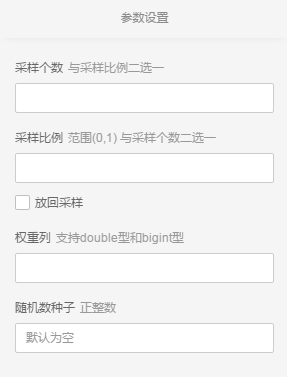
- 可手动输入采样个数(或者采样比例)
- 可以选择放回采样或者不放回采样,默认为不放回,勾选后变为放回
- 下拉框选择加权列,加权列支持double型和bigint型
- 可配置随机数种子,默认系统自动分配
PAI 命令
PAI -name WeightedSample -project algo_public -DprobCol="previous" -DsampleSize="500"-DoutputTableName="test2" -DinputPartitions="pt=20150501" -DinputTableName="bank_data_partition";
算法参数
| 参数名称 | 参数描述 | 参数值可选项 | 默认值 |
|---|---|---|---|
| inputTableName | 必选,输入表的表名 | - | - |
| inputTablePartitions | 可选,输入表中指定哪些分区参与训练,格式为: partition_name=value。如果是多级,格式为name1=value1/name2=value2;如果指定多个分区,中间用’,’分开 | - | 输入表的所有partition |
| outputTableName | 必选,输出结果表 | - | - |
| sampleSize | 可选,采样个数 | 正整数 | 默认为空 |
| sampleRatio | 可选,采样比例 | 浮点数,范围(0,1) | 默认为空 |
| probCol | 必选,选择的要加权的列,每个值代表所在record出现的权重,不需要归一化 | - | - |
| replace | 可选,是否放回,boolean类型 | true / false | false(默认不放回) |
| randomSeed | 可选,随机数种子 | 正整数 | 默认系统自动生成 |
| lifecycle | 可选,指定输出表生命周期 | 正整数,[1,3650] | 输出表没有生命周期 |
| coreNum | 可选,计算的核心数目 | 正整数 | 系统自动分配 |
| memSizePerCore | 可选,每个核心的内存(单位是兆) | 正整数,(1, 65536) | 系统自动分配 |
注:当sampleSize 与 sampleRatio都为空时,报错; 当sampleSize 与 sampleRatio都不为空时,以sampleSize为准。
随机采样
以随机方式生成采样数据,每次采样是各自独立的。
参数设置
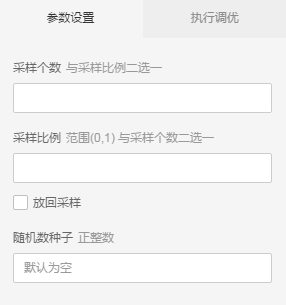
- 可手动输入采样个数(或者采样比例)
- 可以选择放回采样或者不放回采样,默认为不放回,勾选后变为放回
- 可配置随机数种子,默认系统自动分配
- 可以自己配置并发计算核心数目与内存,默认系统自动分配
PAI 命令
pai -name RandomSample -project algo_public-DinputTableName=wbpc-DoutputTableName=wpbc_sample-DsampleSize=100-Dreplace=false-DrandomSeed=1007;
算法参数
| 参数名称 | 参数描述 | 参数值可选项 | 默认值 |
|---|---|---|---|
| inputTableName | 必选,输入表的表名 | - | - |
| inputTablePartitions | 可选,输入表中指定哪些分区参与训练,格式为: partition_name=value。如果是多级,格式为name1=value1/name2=value2;如果指定多个分区,中间用’,’分开 | - | 输入表的所有partition |
| outputTableName | 必选,输出结果表 | - | - |
| sampleSize | 可选,采样个数 | - | 默认为空 |
| sampleRatio | 可选,采样比例,范围(0,1) | - | 默认为空 |
| replace | 可选,是否放回,boolean类型 | true / false | false(默认不放回) |
| randomSeed | 可选,随机数种子 | 正整数 | 默认系统自动生成 |
| lifecycle | 可选,指定输出表生命周期 | 正整数,[1,3650] | 输出表没有生命周期 |
| coreNum | 可选,计算的核心数目 | 正整数 | 系统自动分配 |
| memSizePerCore | 可选,每个核心的内存(单位是兆) | 正整数,(1, 65536) | 系统自动分配 |
注:当sampleSize 与 sampleRatio都为空时,报错; 当sampleSize 与 sampleRatio都不为空时,以sampleSize为准。
过滤与映射
对数据按照过滤表达式进行筛选;可以重命名字段名;
参数设置
1、通过where条件实现数据过滤,与SQL类似,如: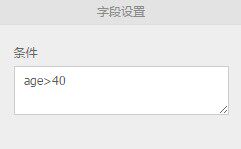
- 筛选条件:目前操作符支持”=”,”!=”,”>”,”<”, “>=”和“<=”,like,rlike
2、重命名字段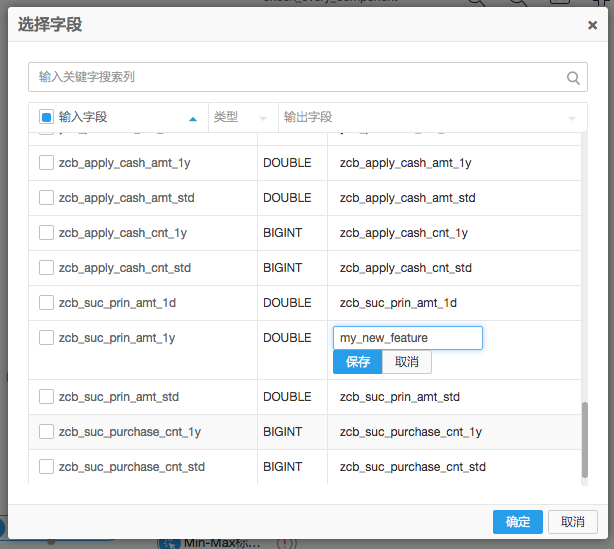
PAI命令
PAI -name Filter -project algo_public -DoutTableName="test_9" -DinputPartitions="pt=20150501"-DinputTableName="bank_data_partition" -Dfilter="age>=40";
- name: 组件名字
- project: project名字,用于指定算法所在空间。系统默认是algo_public,用户自己更改后系统会报错
- outTableName: 输出表的名字
- inputPartitions:(可选)训练输入表分区。输入表对应的输入分区,选中全表则为None
- inputTableName: 输入表的名字
- filter: where筛选条件,目前操作符支持”=”,”!=”,”>”,”<”, “>=”,“<=”,“like”和“rlike”
分层采样
数据集分层抽取一定比例或者一定数据的随机样本
参数设置
参数框
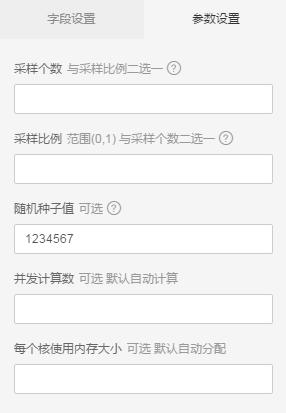
- 下拉框选择分组列(最大支持100个分组)
- 可手动输入分组的采样个数(或者采样比例)
- 可配置随机数种子,默认1234567
- 可以自己配置并发计算核心数目与内存,默认系统自动分配
pai 命令
PAI -name StratifiedSample -project algo_public-DinputTableName="test_input"-DoutputTableName="test_output"-DstrataColName="label"-DsampleSize="A:200,B:300,C:500"-DrandomSeed=1007-Dlifecycle=30
算法参数
| 参数名称 | 参数描述 | 参数值可选项 | 默认值 |
|---|---|---|---|
| inputTableName | 必选,输入表 | - | - |
| inputTablePartitions | 可选,训练输入表分区。 | - | 默认选中全表 |
| outputTableName | 必选,输出表 | - | - |
| strataColName | 必选,层次列,分层就是按照此列作为key分层的 | - | - |
| sampleSize | 可选,采样大小,整数时:表示每个stratum的采样个数;字符串时:格式为strata0:n0,strata1:n1 表示每个stratum分别配置采样个数 | - | - |
| sampleRatio | 可选,采样比例,数字时:范围(0,1)表示每个stratum的采样比例;字符串时:格式为strata0:r0,strata1:r1 表示每个stratum分别配置采样比例。 | - | - |
| randomSeed | 可选, 随机种子 | - | 默认123456 |
| lifecycle | 可选,输出表生命周期 | - | 默认不设置 |
| coreNum | 可选,核心个数 | - | 默认不设置,系统自动分配 |
| memSizePerCore | 可选,单个核心使用的内存数 | - | 默认不设置,系统自动分配 |
注:当sampleSize 与 sampleRatio都为空时,报错; 当sampleSize 与 sampleRatio都不为空时,以sampleSize为准。
示例
源数据
| id | outlook | temperature | humidity | windy | play |
|---|---|---|---|---|---|
| 0 | Sunny | 85 | 85 | false | No |
| 1 | Sunny | 80 | 90 | true | No |
| 2 | Overcast | 83 | 86 | false | Yes |
| 3 | Rainy | 70 | 96 | false | Yes |
| 4 | Rainy | 68 | 80 | false | Yes |
| 5 | Rainy | 65 | 70 | true | No |
| 6 | Overcast | 64 | 65 | true | Yes |
| 7 | Sunny | 72 | 95 | false | No |
| 8 | Sunny | 69 | 70 | false | Yes |
| 9 | Rainy | 75 | 80 | false | Yes |
| 10 | Sunny | 75 | 70 | true | Yes |
| 11 | Overcast | 72 | 90 | true | Yes |
| 12 | Overcast | 81 | 75 | false | Yes |
| 13 | Rainy | 71 | 91 | true | No |
1. 创建实验
2. 选取分组列
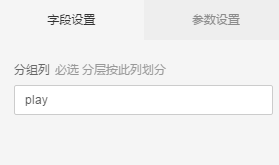
- 选择play列,做为分组列
3. 配置采样个数
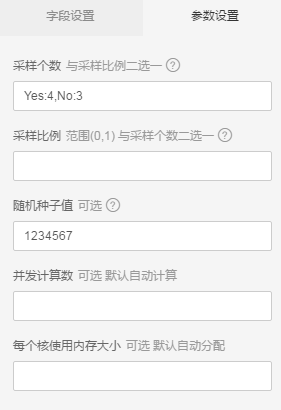
- play=Yes的分组采4条;play=No有分组采3条
4. 采样结果
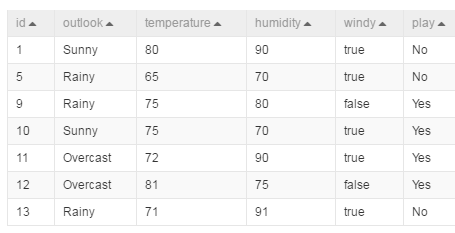
join
两张表通过关联信息,合成一张表,并决定输出的字段;与SQL的join语句功能类似
参数设置
填写参数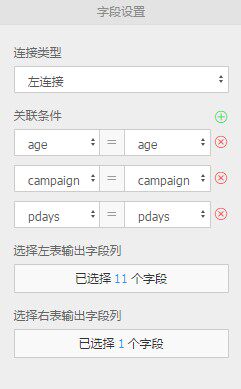
- 连接类型支持:左连接,内连接,右连接,全连接
- 关联条件目前只支持等式
- 可手动添加或删除关联条件
PAI 命令
不提供pai命令
合并列
将两张表的数据按列合并,需要表的行数保持一致
参数设置
如图: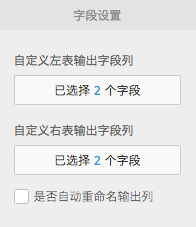 左表选择输入列
左表选择输入列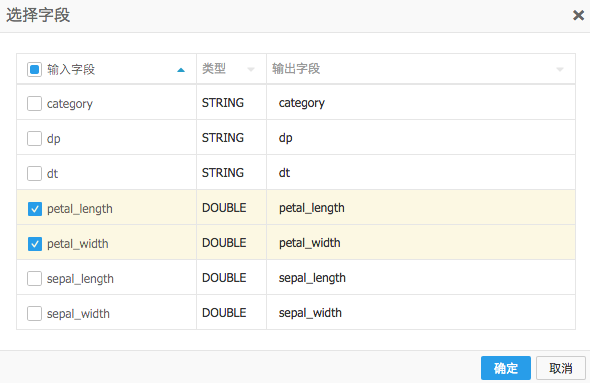 右表选择输入列
右表选择输入列
选择的两张表行数需保持一致
左表与右表选择的输出列名不能重复
选择输出字段列时可手动更改输出字段名
若左表右表均不选择输出列,则默认输出全表。此时勾选‘是否自动重命名输出列’,会将重复列重命名后输出
PAI 命令
PAI -name AppendColumns -project algo_public -DoutputTableColNames="petal_length,petal_width,petal_length2,petal_width2"-DautoRenameCol="false" -DoutputTableName="pai_temp_770_6840_1" -DinputTableNames="iris_twopartition,iris_twopartition"-DinputPartitionsInfoList="dt=20150125/dp=20150124;dt=20150124/dp=20150123"-DselectedColNamesList="petal_length,petal_width;sepal_length,sepal_width";
- name: 组件名字
- project: project名字,用于指定算法所在空间。系统默认是algo_public,用户自己更改后系统会报错
- outputTableColNames: 新表中各列的列名。逗号分隔,如果autoRenameCol为true,则此参数无效
- autoRenameCol: (可选)输出表是否自动重命名列,true为重命名,false不进行重命名,默认false
- outputTableName: 输出的表名
- inputTableNames:输入的表名,如果有多个,逗号分隔
- inputPartitionsInfoList:(可选)输入表对应选择的partition列表,同一个表的各partition按逗号分隔,不同表的partition分号分隔
- selectedColNamesList:选择输入的列名,同张表之间列名用逗号分隔,不同表之间用分号分隔
UNION
将两张表的数据按行合并,左表及右表选择输出的字段个数以及类型应保持一致。整合了union和union all的功能。
参数设置
调整参数,如下: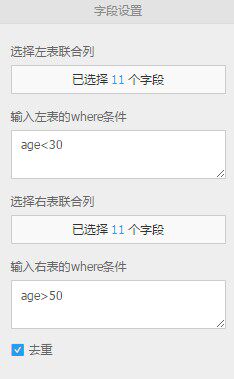
- 进行联合操作时,左右表选择的列数需相同,对应列的类型需保证一致
- 可根据实际情况在条件框中手动输入已选字段的过滤条件,默认情况下全表,目前操作符支持”=”,”!=”,”>”,”<”, “>=”,“<=”,“like” 和 “rlike”
- 系统默认勾选去重。勾选后将会对生成的数据表的重复行进行去重操作(distinct)左表联合列
 右表联合列
右表联合列
PAI 命令
不提供pai命令
增加序号列
在数据表第一列追加ID列,并将append id后的内容存为新表
参数设置
略
PAI命令
PAI -name AppendId -project algo_public -DIDColName="append_id" -DoutputTableName="test_11" -DinputTableName="bank_data"-DselectedColNames="age,campaign,cons_conf_idx,cons_price_idx,emp_var_rate,euribor3m,nr_employed,pdays,poutcome,previous,y";
- name: 组件名字
- project: project名字,用于指定算法所在空间。系统默认是algo_public,用户自己更改后系统会报错
- IDColName:追加的ID列列名,从0开始编号,依次为0,1,2,3…
- outputTableNames: 输出表的名字
- inputTableNmae: 输入表的名字
- selectedColNames: 要保留的字段名,多个用逗号分隔
拆分
背景
- 对输入表或分区进行按比例拆分,分别写入两张输出表。
算法组件
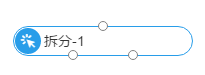
- 拆分组件,对应两个输出桩
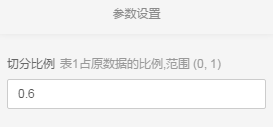
- 如图所示配置0.6,则左边的输出桩对应60%的数据,右边对应40%的数据
PAI命令
pai -name split -project algo_public-DinputTableName=wbpc-Doutput1TableName=wpbc_split1-Doutput2TableName=wpbc_split2-Dfraction=0.25;
参数设置
| 参数名称 | 参数描述 | 参数值可选项 | 默认值 |
|---|---|---|---|
| inputTableName | 必选,输入表的表名 | - | - |
| inputTablePartitions | 可选,输入表中指定哪些分区参与训练,格式为: partition_name=value。如果是多级,格式为name1=value1/name2=value2;如果指定多个分区,中间用’,’分开 | - | 输入表的所有partition |
| output1TableName | 必选,输出结果表1 | - | - |
| output1TablePartition | 可选,输出结果表1分区名 | - | 输出表1为非分区表 |
| output2TableName | 必选,输出结果表2 | - | - |
| output2TablePartition | 可选,输出结果表2分区名 | - | 输出表2为非分区表 |
| fraction | 必选,切分至输出表1的数据比例 | (0,1) | - |
| lifecycle | 可选,指定输出表生命周期 | 正整数,[1,3650] | 输出表没有生命周期 |
缺失值填充
缺失值填充用来将空值或者一个指定的值替换为最大值,最小值,均值或者一个自定义的值。可以通过给定一个缺失值的配置列表,来实现将输入表的缺失值用指定的值来填充。
- 可以将数值型的空值替换为最大值,最小值,均值或者一个自定义的值
- 可以将字符型的空值,空字符串,空值和空字符串,指定值替换为一个自定义的值
- 待填充的缺失值可以选择空值或空字符,也可以自定义
- 缺失值若选择空字符,则填充的目标列应是string型
- 数值型替换可以自定义,也可以直接选择替换成数值最大值,最小值或者均值
缺失值填充界面
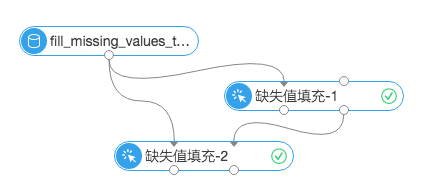
两个输入桩依次对应参数为:
inputTableName 输入表,即要填充的表
inputParaTableName 配置输入表,即缺失值填充节点生成的参数列表,通过此参数,可以将一张表的配置参数应用到一张新的表
两个输出桩依次对应参数为:
outputTableName 输出表,即填充完成的表
outputParaTableName 输出配置表,用于应用到其他的数据集上
缺失值填充参数界面
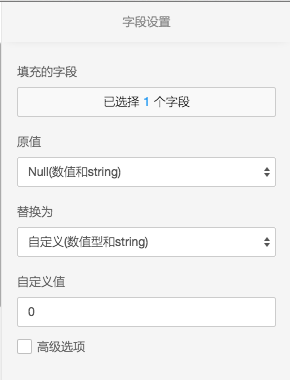
- 填充的字段,原值,替换为三个部分组成了config参数,分别对应config参数的三个部分:列名,原值,替换值
PAI 命令
PAI -name FillMissingValues -project algo_public -Dconfigs="poutcome,null-empty,testing"-DoutputTableName="test_3" -DinputPartitions="pt=20150501" -DinputTableName="bank_data_partition";
算法参数
| 参数名称 | 参数描述 | 参数值可选项 | 默认值 |
|---|---|---|---|
| inputTableName | 必选,输入表 | - | - |
| inputTablePartitions | 可选,训练输入表分区。 | - | 默认选中全表 |
| outputTableName | 必选,输出表 | - | - |
| configs | 必选,缺失值填充的配置。格式如 “col1, null, 3.14; col2, empty, hello; col3, empty-null, world”,其中null表示空值,empty表示空字符。缺失值若选择空字符,则填充的目标列应是string型。若采用最大值、最小值、均值,可以采用变量,其命名规范形如:min, max, mean。若用户自定义替换值,则使用user-defined,格式如”col4,user-defined,str,str123” | - | - |
| outputParaTableName | 必选,配置输出表 | - | - |
| inputParaTableName | 可选,配置输入表 | - | 默认不输入 |
| lifecycle | 可选,输出表生命周期 | - | 默认不设置 |
| coreNum | 可选,核心个数 | - | 默认不设置,系统自动分配 |
| memSizePerCore | 可选,单个核心使用的内存数 | - | 默认不设置,系统自动分配 |
实例
测试数据
新建数据SQL
drop table if exists fill_missing_values_test_input;create table fill_missing_values_test_input(col_string string,col_bigint bigint,col_double double,col_boolean boolean,col_datetime datetime);insert overwrite table fill_missing_values_test_inputselect*from(select'01' as col_string,10 as col_bigint,10.1 as col_double,True as col_boolean,cast('2016-07-01 10:00:00' as datetime) as col_datetimefrom dualunion allselectcast(null as string) as col_string,11 as col_bigint,10.2 as col_double,False as col_boolean,cast('2016-07-02 10:00:00' as datetime) as col_datetimefrom dualunion allselect'02' as col_string,cast(null as bigint) as col_bigint,10.3 as col_double,True as col_boolean,cast('2016-07-03 10:00:00' as datetime) as col_datetimefrom dualunion allselect'03' as col_string,12 as col_bigint,cast(null as double) as col_double,False as col_boolean,cast('2016-07-04 10:00:00' as datetime) as col_datetimefrom dualunion allselect'04' as col_string,13 as col_bigint,10.4 as col_double,cast(null as boolean) as col_boolean,cast('2016-07-05 10:00:00' as datetime) as col_datetimefrom dualunion allselect'05' as col_string,14 as col_bigint,10.5 as col_double,True as col_boolean,cast(null as datetime) as col_datetimefrom dual) tmp;
输入数据说明
+------------+------------+------------+-------------+--------------+| col_string | col_bigint | col_double | col_boolean | col_datetime |+------------+------------+------------+-------------+--------------+| 04 | 13 | 10.4 | NULL | 2016-07-05 10:00:00 || 02 | NULL | 10.3 | true | 2016-07-03 10:00:00 || 03 | 12 | NULL | false | 2016-07-04 10:00:00 || NULL | 11 | 10.2 | false | 2016-07-02 10:00:00 || 01 | 10 | 10.1 | true | 2016-07-01 10:00:00 || 05 | 14 | 10.5 | true | NULL |+------------+------------+------------+-------------+--------------+
运行命令
drop table if exists fill_missing_values_test_input_output;drop table if exists fill_missing_values_test_input_model_output;PAI -name FillMissingValues-project algo_public-Dconfigs="col_double,null,mean;col_string,null-empty,str_type_empty;col_bigint,null,max;col_boolean,null,true;col_datetime,null,2016-07-06 10:00:00"-DoutputParaTableName="fill_missing_values_test_input_model_output"-Dlifecycle="28"-DoutputTableName="fill_missing_values_test_input_output"-DinputTableName="fill_missing_values_test_input";drop table if exists fill_missing_values_test_input_output_using_model;drop table if exists fill_missing_values_test_input_output_using_model_model_output;PAI -name FillMissingValues-project algo_public-DoutputParaTableName="fill_missing_values_test_input_output_using_model_model_output"-DinputParaTableName="fill_missing_values_test_input_model_output"-Dlifecycle="28"-DoutputTableName="fill_missing_values_test_input_output_using_model"-DinputTableName="fill_missing_values_test_input";
运行结果
fill_missing_values_test_input_output
+------------+------------+------------+-------------+--------------+| col_string | col_bigint | col_double | col_boolean | col_datetime |+------------+------------+------------+-------------+--------------+| 04 | 13 | 10.4 | true | 2016-07-05 10:00:00 || 02 | 14 | 10.3 | true | 2016-07-03 10:00:00 || 03 | 12 | 10.3 | false | 2016-07-04 10:00:00 || str_type_empty | 11 | 10.2 | false | 2016-07-02 10:00:00 || 01 | 10 | 10.1 | true | 2016-07-01 10:00:00 || 05 | 14 | 10.5 | true | 2016-07-06 10:00:00 |+------------+------------+------------+-------------+--------------+
fill_missing_values_test_input_model_output
+------------+------------+| feature | json |+------------+------------+| col_string | {"name": "fillMissingValues", "type": "string", "paras":{"missing_value_type": "null-empty", "replaced_value": "str_type_empty"}} || col_bigint | {"name": "fillMissingValues", "type": "bigint", "paras":{"missing_value_type": "null", "replaced_value": 14}} || col_double | {"name": "fillMissingValues", "type": "double", "paras":{"missing_value_type": "null", "replaced_value": 10.3}} || col_boolean | {"name": "fillMissingValues", "type": "boolean", "paras":{"missing_value_type": "null", "replaced_value": 1}} || col_datetime | {"name": "fillMissingValues", "type": "datetime", "paras":{"missing_value_type": "null", "replaced_value": 1467770400000}} |+------------+------------+
fill_missing_values_test_input_output_using_model
+------------+------------+------------+-------------+--------------+| col_string | col_bigint | col_double | col_boolean | col_datetime |+------------+------------+------------+-------------+--------------+| 04 | 13 | 10.4 | true | 2016-07-05 10:00:00 || 02 | 14 | 10.3 | true | 2016-07-03 10:00:00 || 03 | 12 | 10.3 | false | 2016-07-04 10:00:00 || str_type_empty | 11 | 10.2 | false | 2016-07-02 10:00:00 || 01 | 10 | 10.1 | true | 2016-07-01 10:00:00 || 05 | 14 | 10.5 | true | 2016-07-06 10:00:00 |+------------+------------+------------+-------------+--------------+
fill_missing_values_test_input_output_using_model_model_output
+------------+------------+| feature | json |+------------+------------+| col_string | {"name": "fillMissingValues", "type": "string", "paras":{"missing_value_type": "null-empty", "replaced_value": "str_type_empty"}} || col_bigint | {"name": "fillMissingValues", "type": "bigint", "paras":{"missing_value_type": "null", "replaced_value": 14}} || col_double | {"name": "fillMissingValues", "type": "double", "paras":{"missing_value_type": "null", "replaced_value": 10.3}} || col_boolean | {"name": "fillMissingValues", "type": "boolean", "paras":{"missing_value_type": "null", "replaced_value": 1}} || col_datetime | {"name": "fillMissingValues", "type": "datetime", "paras":{"missing_value_type": "null", "replaced_value": 1467770400000}} |+------------+------------+
归一化
- 对一个表的某一列或多列,进行归一化处理,产生的数据存入新表中。
- 目前支持的是线性函数转换,表达式如下:y=(x-MinValue)/(MaxValue-MinValue),MaxValue、MinValue分别为样本的最大值和最小值。
- 可以选择是否保留原始列,勾选后原始列会被保留,处理过的列重命名。
- 点击选择字段按钮可以选择想要归一化的列,目前支持double类型与bigint类型。
归一化界面
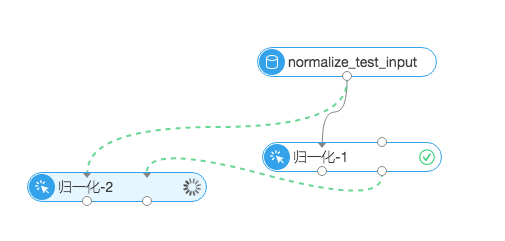
两个输入桩依次对应参数为:
inputTableName 输入表,即要归一化的表
inputParaTableName 配置输入表,即归一化节点生成的参数列表,通过此参数,可以将一张表的配置参数应用到一张新的表
两个输出桩依次对应参数为:
outputTableName 输出表,即归一化完成的表
outputParaTableName 输出配置表,用于应用到其他的数据集上
归一化参数界面

- 保留原始列对应参数keepOriginal
PAI 命令
PAI -name Normalize -project algo_public -DkeepOriginal="true" -DoutputTableName="test_4" -DinputPartitions="pt=20150501"-DinputTableName="bank_data_partition" -DselectedColNames="emp_var_rate,euribor3m";
算法参数
| 参数名称 | 参数描述 | 参数值可选项 | 默认值 |
|---|---|---|---|
| inputTableName | 必选,输入表 | - | - |
| selectedColNames | 可选,输入表选择列 | - | 默认选中全部列 |
| inputTablePartitions | 可选,训练输入表分区。 | - | 默认选中全表 |
| outputTableName | 必选,输出表 | - | - |
| outputParaTableName | 必选,配置输出表 | - | - |
| inputParaTableName | 可选,配置输入表 | - | 默认不输入 |
| keepOriginal | 可选,是否保留原始列(keepOriginal =true时,处理过的列重命名(”normalized_”前缀),原始列保留,keepOriginal=false时,全部列保留且不重命名) | - | 默认为false |
| lifecycle | 可选,输出表生命周期 | - | 默认不设置 |
| coreNum | 可选,核心个数 | - | 默认不设置,系统自动分配 |
| memSizePerCore | 可选,单个核心使用的内存数 | - | 默认不设置,系统自动分配 |
实例
测试数据
新建数据SQL
drop table if exists normalize_test_input;create table normalize_test_input(col_string string,col_bigint bigint,col_double double,col_boolean boolean,col_datetime datetime);insert overwrite table normalize_test_inputselect*from(select'01' as col_string,10 as col_bigint,10.1 as col_double,True as col_boolean,cast('2016-07-01 10:00:00' as datetime) as col_datetimefrom dualunion allselectcast(null as string) as col_string,11 as col_bigint,10.2 as col_double,False as col_boolean,cast('2016-07-02 10:00:00' as datetime) as col_datetimefrom dualunion allselect'02' as col_string,cast(null as bigint) as col_bigint,10.3 as col_double,True as col_boolean,cast('2016-07-03 10:00:00' as datetime) as col_datetimefrom dualunion allselect'03' as col_string,12 as col_bigint,cast(null as double) as col_double,False as col_boolean,cast('2016-07-04 10:00:00' as datetime) as col_datetimefrom dualunion allselect'04' as col_string,13 as col_bigint,10.4 as col_double,cast(null as boolean) as col_boolean,cast('2016-07-05 10:00:00' as datetime) as col_datetimefrom dualunion allselect'05' as col_string,14 as col_bigint,10.5 as col_double,True as col_boolean,cast(null as datetime) as col_datetimefrom dual) tmp;
输入数据说明
+------------+------------+------------+-------------+--------------+| col_string | col_bigint | col_double | col_boolean | col_datetime |+------------+------------+------------+-------------+--------------+| 01 | 10 | 10.1 | true | 2016-07-01 10:00:00 || NULL | 11 | 10.2 | false | 2016-07-02 10:00:00 || 02 | NULL | 10.3 | true | 2016-07-03 10:00:00 || 03 | 12 | NULL | false | 2016-07-04 10:00:00 || 04 | 13 | 10.4 | NULL | 2016-07-05 10:00:00 || 05 | 14 | 10.5 | true | NULL |+------------+------------+------------+-------------+--------------+
运行命令
drop table if exists normalize_test_input_output;drop table if exists normalize_test_input_model_output;PAI -name Normalize-project algo_public-DoutputParaTableName="normalize_test_input_model_output"-Dlifecycle="28"-DoutputTableName="normalize_test_input_output"-DinputTableName="normalize_test_input"-DselectedColNames="col_double,col_bigint"-DkeepOriginal="true";drop table if exists normalize_test_input_output_using_model;drop table if exists normalize_test_input_output_using_model_model_output;PAI -name Normalize-project algo_public-DoutputParaTableName="normalize_test_input_output_using_model_model_output"-DinputParaTableName="normalize_test_input_model_output"-Dlifecycle="28"-DoutputTableName="normalize_test_input_output_using_model"-DinputTableName="normalize_test_input";
运行结果
normalize_test_input_output
+------------+------------+------------+-------------+--------------+-----------------------+-----------------------+| col_string | col_bigint | col_double | col_boolean | col_datetime | normalized_col_bigint | normalized_col_double |+------------+------------+------------+-------------+--------------+-----------------------+-----------------------+| 01 | 10 | 10.1 | true | 2016-07-01 10:00:00 | 0.0 | 0.0 || NULL | 11 | 10.2 | false | 2016-07-02 10:00:00 | 0.25 | 0.2499999999999989 || 02 | NULL | 10.3 | true | 2016-07-03 10:00:00 | NULL | 0.5000000000000022 || 03 | 12 | NULL | false | 2016-07-04 10:00:00 | 0.5 | NULL || 04 | 13 | 10.4 | NULL | 2016-07-05 10:00:00 | 0.75 | 0.7500000000000011 || 05 | 14 | 10.5 | true | NULL | 1.0 | 1.0 |+------------+------------+------------+-------------+--------------+-----------------------+-----------------------+
normalize_test_input_model_output
+------------+------------+| feature | json |+------------+------------+| col_bigint | {"name": "normalize", "type":"bigint", "paras":{"min":10, "max": 14}} || col_double | {"name": "normalize", "type":"double", "paras":{"min":10.1, "max": 10.5}} |+------------+------------+
normalize_test_input_output_using_model
+------------+------------+------------+-------------+--------------+| col_string | col_bigint | col_double | col_boolean | col_datetime |+------------+------------+------------+-------------+--------------+| 01 | 0.0 | 0.0 | true | 2016-07-01 10:00:00 || NULL | 0.25 | 0.2499999999999989 | false | 2016-07-02 10:00:00 || 02 | NULL | 0.5000000000000022 | true | 2016-07-03 10:00:00 || 03 | 0.5 | NULL | false | 2016-07-04 10:00:00 || 04 | 0.75 | 0.7500000000000011 | NULL | 2016-07-05 10:00:00 || 05 | 1.0 | 1.0 | true | NULL |+------------+------------+------------+-------------+--------------+
normalize_test_input_output_using_model_model_output
+------------+------------+| feature | json |+------------+------------+| col_bigint | {"name": "normalize", "type":"bigint", "paras":{"min":10, "max": 14}} || col_double | {"name": "normalize", "type":"double", "paras":{"min":10.1, "max": 10.5}} |+------------+------------+
标准化
- 对一个表的某一列或多列,进行标准化处理,产生的数据存入新表中。
- 标准化所使用的公式 :(X - Mean)/(standard deviation)。
- Mean:样本平均值。
- standard deviation:样本标准偏差,针对从总体抽样,利用样本来计算总体偏差,为了使算出的值与总体水平更接近,就必须将算出的标准偏差的值适度放大,即,
。
- 样本标准偏差公式:
代表所采用的样本X1,X2,…,Xn的均值。
- 可以选择是否保留原始列,勾选后原始列会被保留,处理过的列重命名
- 点击选择字段按钮可以选择想要标准化的列,目前支持double类型与bigint类型
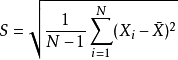
标准化界面
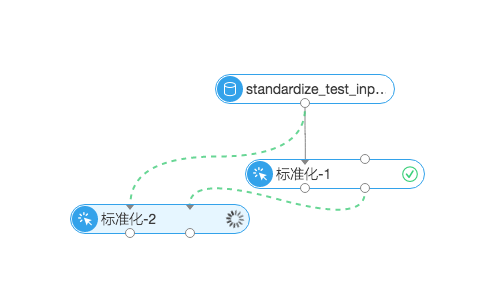
两个输入桩依次对应参数为:
inputTableName 输入表,即要标准化的表
inputParaTableName 配置输入表,即标准化节点生成的参数列表,通过此参数,可以将一张表的配置参数应用到一张新的表
两个输出桩依次对应参数为:
outputTableName 输出表,即标准化完成的表
outputParaTableName 输出配置表,用于应用到其他的数据集上
标准化参数界面
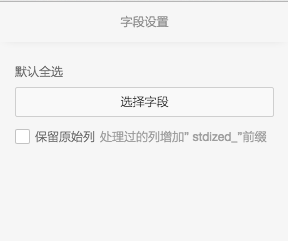
- 保留原始列对应参数keepOriginal
PAI 命令
PAI -name Standardize -project algo_public -DkeepOriginal="false" -DoutputTableName="test_5"-DinputPartitions="pt=20150501" -DinputTableName="bank_data_partition" -DselectedColNames="euribor3m,pdays";
算法参数
| 参数名称 | 参数描述 | 参数值可选项 | 默认值 |
|---|---|---|---|
| inputTableName | 必选,输入表 | - | - |
| selectedColNames | 可选,输入表选择列 | - | 默认选中全部列 |
| inputTablePartitions | 可选,训练输入表分区。 | - | 默认选中全表 |
| outputTableName | 必选,输出表 | - | - |
| outputParaTableName | 必选,配置输出表 | - | - |
| inputParaTableName | 可选,配置输入表 | - | 默认不输入 |
| keepOriginal | 可选,是否保留原始列(keepOriginal =true时,处理过的列重命名(”stdized_”前缀),原始列保留,keepOriginal=false时,全部列保留且不重命名) | - | 默认为false |
| lifecycle | 可选,输出表生命周期 | - | 默认不设置 |
| coreNum | 可选,核心个数 | - | 默认不设置,系统自动分配 |
| memSizePerCore | 可选,单个核心使用的内存数 | - | 默认不设置,系统自动分配 |
实例
测试数据
新建数据SQL
drop table if exists standardize_test_input;create table standardize_test_input(col_string string,col_bigint bigint,col_double double,col_boolean boolean,col_datetime datetime);insert overwrite table standardize_test_inputselect*from(select'01' as col_string,10 as col_bigint,10.1 as col_double,True as col_boolean,cast('2016-07-01 10:00:00' as datetime) as col_datetimefrom dualunion allselectcast(null as string) as col_string,11 as col_bigint,10.2 as col_double,False as col_boolean,cast('2016-07-02 10:00:00' as datetime) as col_datetimefrom dualunion allselect'02' as col_string,cast(null as bigint) as col_bigint,10.3 as col_double,True as col_boolean,cast('2016-07-03 10:00:00' as datetime) as col_datetimefrom dualunion allselect'03' as col_string,12 as col_bigint,cast(null as double) as col_double,False as col_boolean,cast('2016-07-04 10:00:00' as datetime) as col_datetimefrom dualunion allselect'04' as col_string,13 as col_bigint,10.4 as col_double,cast(null as boolean) as col_boolean,cast('2016-07-05 10:00:00' as datetime) as col_datetimefrom dualunion allselect'05' as col_string,14 as col_bigint,10.5 as col_double,True as col_boolean,cast(null as datetime) as col_datetimefrom dual) tmp;
输入数据说明
+------------+------------+------------+-------------+--------------+| col_string | col_bigint | col_double | col_boolean | col_datetime |+------------+------------+------------+-------------+--------------+| 01 | 10 | 10.1 | true | 2016-07-01 10:00:00 || NULL | 11 | 10.2 | false | 2016-07-02 10:00:00 || 02 | NULL | 10.3 | true | 2016-07-03 10:00:00 || 03 | 12 | NULL | false | 2016-07-04 10:00:00 || 04 | 13 | 10.4 | NULL | 2016-07-05 10:00:00 || 05 | 14 | 10.5 | true | NULL |+------------+------------+------------+-------------+--------------+
运行命令
drop table if exists standardize_test_input_output;drop table if exists standardize_test_input_model_output;PAI -name Standardize-project algo_public-DoutputParaTableName="standardize_test_input_model_output"-Dlifecycle="28"-DoutputTableName="standardize_test_input_output"-DinputTableName="standardize_test_input"-DselectedColNames="col_double,col_bigint"-DkeepOriginal="true";drop table if exists standardize_test_input_output_using_model;drop table if exists standardize_test_input_output_using_model_model_output;PAI -name Standardize-project algo_public-DoutputParaTableName="standardize_test_input_output_using_model_model_output"-DinputParaTableName="standardize_test_input_model_output"-Dlifecycle="28"-DoutputTableName="standardize_test_input_output_using_model"-DinputTableName="standardize_test_input";
运行结果
standardize_test_input_output
+------------+------------+------------+-------------+--------------+--------------------+--------------------+| col_string | col_bigint | col_double | col_boolean | col_datetime | stdized_col_bigint | stdized_col_double |+------------+------------+------------+-------------+--------------+--------------------+--------------------+| 01 | 10 | 10.1 | true | 2016-07-01 10:00:00 | -1.2649110640673518 | -1.2649110640683832 || NULL | 11 | 10.2 | false | 2016-07-02 10:00:00 | -0.6324555320336759 | -0.6324555320341972 || 02 | NULL | 10.3 | true | 2016-07-03 10:00:00 | NULL | 0.0 || 03 | 12 | NULL | false | 2016-07-04 10:00:00 | 0.0 | NULL || 04 | 13 | 10.4 | NULL | 2016-07-05 10:00:00 | 0.6324555320336759 | 0.6324555320341859 || 05 | 14 | 10.5 | true | NULL | 1.2649110640673518 | 1.2649110640683718 |+------------+------------+------------+-------------+--------------+--------------------+--------------------+
standardize_test_input_model_output
+------------+------------+| feature | json |+------------+------------+| col_bigint | {"name": "standardize", "type":"bigint", "paras":{"mean":12, "std": 1.58113883008419}} || col_double | {"name": "standardize", "type":"double", "paras":{"mean":10.3, "std": 0.1581138830082909}} |+------------+------------+
standardize_test_input_output_using_model
+------------+------------+------------+-------------+--------------+| col_string | col_bigint | col_double | col_boolean | col_datetime |+------------+------------+------------+-------------+--------------+| 01 | -1.2649110640673515 | -1.264911064068383 | true | 2016-07-01 10:00:00 || NULL | -0.6324555320336758 | -0.6324555320341971 | false | 2016-07-02 10:00:00 || 02 | NULL | 0.0 | true | 2016-07-03 10:00:00 || 03 | 0.0 | NULL | false | 2016-07-04 10:00:00 || 04 | 0.6324555320336758 | 0.6324555320341858 | NULL | 2016-07-05 10:00:00 || 05 | 1.2649110640673515 | 1.2649110640683716 | true | NULL |+------------+------------+------------+-------------+--------------+
standardize_test_input_output_using_model_model_output
+------------+------------+| feature | json |+------------+------------+| col_bigint | {"name": "standardize", "type":"bigint", "paras":{"mean":12, "std": 1.58113883008419}} || col_double | {"name": "standardize", "type":"double", "paras":{"mean":10.3, "std": 0.1581138830082909}} |+------------+------------+
类型转换
组件功能介绍
- 将表的字段类型转成另一个类型
PAI 命令实例
PAI -name type_transform-project algo_public-DinputTable="pai_dense"-DselectedCols="gail,loss,work_year"-Dpre_type="double"-Dnew_type="bigint"-DoutputTable="pai_temp_2250_20272_1"-Dlifecycle="28"
算法参数
| 参数名称 | 参数描述 | 参数值可选项 | 默认值 |
|---|---|---|---|
| inputTable | 必选,输入表的表名 | - | - |
| inputTablePartitions | 可选,输入表中指定哪些分区参与训练,格式为: partition_name=value。如果是多级,格式为name1=value1/name2=value2;如果指定多个分区,中间用’,’分开 | - | 输入表的所有partition |
| outputTable | 必选,类型转换的结果表 | - | - |
| selectedCols | 必选,需要类型转换特征列,必须是同一个类型 | - | - |
| pre_type | 原字段类型,必须与selectedCols勾选的字段类型一致,否则会报字段类型不一致错误 | - | - |
| new_type | 新的字段类型,用户设置 | 100 | |
| lifecycle | outputTable结果表生命周期,可选,默认7 | 7 |
使用DEMO
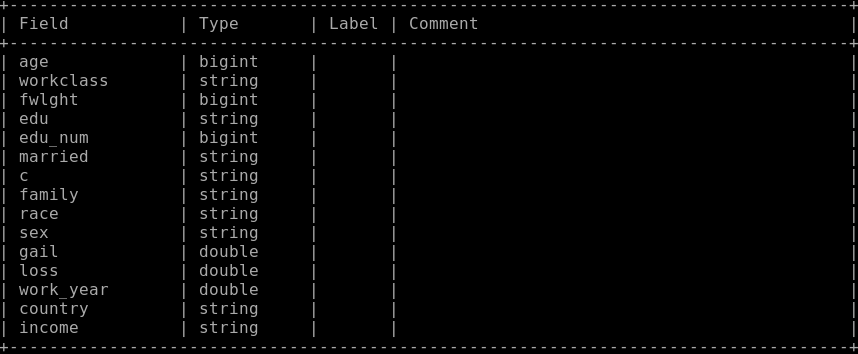
1. 拖拽一个读数据表组件,配置数据表pai_dense结构如下
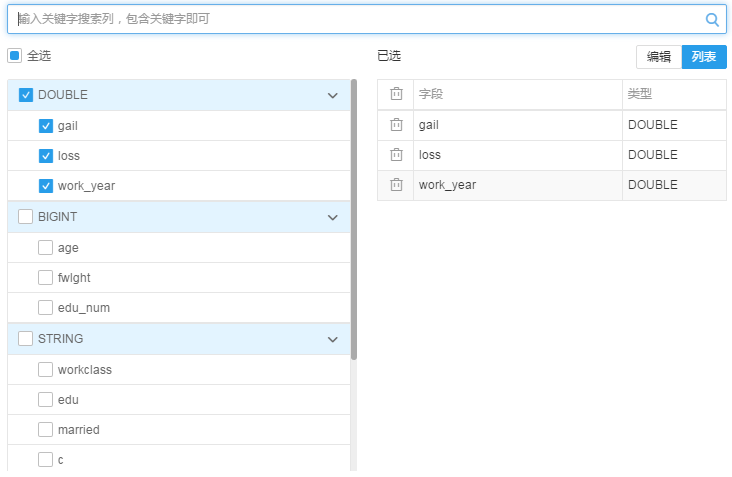
2. 拖拽一个类型转换组件, 在右侧参数配置栏中:勾选需要转换的特征,比如下图勾选了3个原数据类型为double的列(主要double类型必须与勾选的字段类型一致),转换成bigint类型

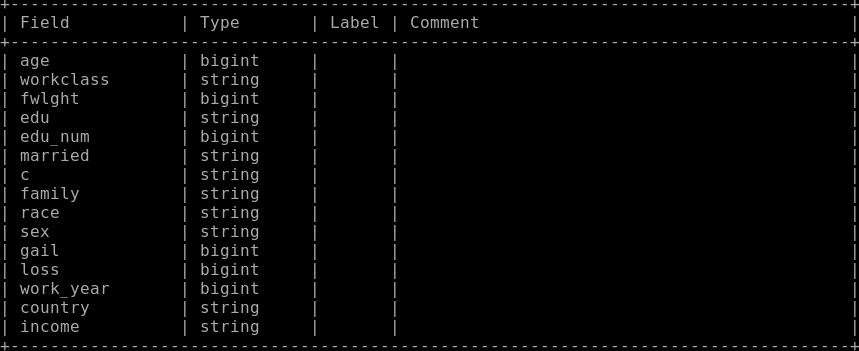
3. 右键点击运行后,可以看到输出结果表字段类型变化如下
最后更新:2016-11-23 16:04:15
上一篇: 源/目标__使用手册(new)_机器学习-阿里云
源/目标__使用手册(new)_机器学习-阿里云
下一篇: 特征工程__使用手册(new)_机器学习-阿里云
- 怎样授权子用户执行刷新缓存及预热操作___CDN授权问题_授权常见问题_访问控制-阿里云
- 获取API的定义文档__快速入门(调用API)_API 网关-阿里云
- 下载域名日志__日志信息接口_API 手册_CDN-阿里云
- 重置密码__帐号管理_用户指南_云数据库 RDS 版-阿里云
- 前言 极速自由的大数据OLAP体验__使用手册_分析型数据库-阿里云
- 权限查看__用户及授权管理_安全指南_大数据计算服务-阿里云
- GetUser__用户管理接口_RAM API文档_访问控制-阿里云
- 阿里云自研数据库下周将相,“去IOE”使命完成
- 发布订阅管理__控制台使用指南_消息队列 MQ-阿里云
- 手机和邮箱不可用如何在线转移__业务转移_产品管理_会员账号&实名认证-阿里云
相关内容
- 常见错误说明__附录_大数据计算服务-阿里云
- 发送短信接口__API使用手册_短信服务-阿里云
- 接口文档__Android_安全组件教程_移动安全-阿里云
- 运营商错误码(联通)__常见问题_短信服务-阿里云
- 设置短信模板__使用手册_短信服务-阿里云
- OSS 权限问题及排查__常见错误及排除_最佳实践_对象存储 OSS-阿里云
- 消息通知__操作指南_批量计算-阿里云
- 设备端快速接入(MQTT)__快速开始_阿里云物联网套件-阿里云
- 查询API调用流量数据__API管理相关接口_API_API 网关-阿里云
- 使用STS访问__JavaScript-SDK_SDK 参考_对象存储 OSS-阿里云