![]() 886
886
![]()
![]() 财经资讯
财经资讯
搜索相关性函数__应用高级配置_产品使用手册_开放搜索-阿里云
插件function可以用在filter子句作为过滤和筛选条件,而返回值为数值型的fuction在sort子句中,用来做排序。其中函数参数出现的文档字段必须配置为属性字段。
功能feature可以用到排序表达式中(出于性能的考虑,大部分仅支持精排表达式),可以通过各种语法及语句的组合得到强大的排序功能。其中函数参数出现的文档字段必须勾选可搜索.
兼容特征及函数项
兼有function及feature的功能,可以同时在filter、sort及formula表达式中使用。其中函数参数出现的文档字段必须配置为属性字段
distance : 获取两个点之间的球面距离。一般用于LBS的距离计算。
详细用法
distance(longitude_a, latitude_a, longtitude_b, latitude_b, output_name)参数
longitude_a:点A的经度值。支持的参数类型为浮点型的字段名
latitude_a:点A的纬度值。支持的参数类型为浮点型的字段名
longtitude_b:点B的经度值。支持的参数类型为浮点型的字段名;或者为用户查询串中kvpairs子句中设置的一个字段名(其值需要为浮点数)
latitude_b:点B的纬度值。支持的参数类型为浮点型的字段名;或者为用户查询串中kvpairs子句中设置的一个字段名(其值需要为浮点数)
outputname:如果需要在结果中返回距离值,可以通过制定outputname值得到,如果不需要,可以不指定。返回值
float。实际距离值,单位为千米。适用场景
场景1:查找距离用户(120.34256,30.56982)10公里内的外婆家(lon,lat为文档中记录商家的经纬度值,需要配置为属性字段),并按照距离由近及远排序;
query=default:’外婆家’&&filter=distance(lon,lat,”120.34256”,”30.56982”)<10&&sort=+distance(lon,lat,"120.34256","30.56982") 其中距离排序也可以采用如下方式实现,用户坐标通过kvpairs传递。
kvpairs=longtitude_in_query:120.34256, latitude_in_query:30.56982
精排表达式为:distance(longitude_in_doc, latitude_in_doc, longtitude_in_query, latitude_in_query, distance_value)注意事项
- outputname参数仅限于精排表达式中使用,filter及sort子句不支持。设置outputname参数后,实际的距离值将展示到variableValue节点中,该节点只能在返回格式为xml或者fulljson中(config子句中format参数可以设置)才能得到。
tag_match : 用于对查询语句和文档做标签匹配,使用匹配结果对文档进行算分加权
场景概述
涉及query和文档匹配的很多需求都可以使用或者转化为tag_match来满足,对实现搜索个性化需求尤其有用。例如优先出现用户点赞过的店铺优先出现,有限展现用户喜欢的体育和娱乐类新闻等。tag_match最基本的功能是在文档的某个ARRAY字段中存储一系列的key-value信息。然后在查询query中通过kvpairs子句传递对应的key-value信息,tag_match就会去文档中寻找查询query中的key, 然后为每个匹配的key计算得到一个分数,再合并所有匹配的key的分数得到一个最终分。这个结果就可以用来做算分加权或者过滤。计算过程如下:
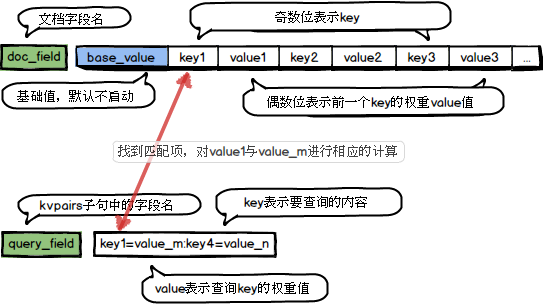
详细用法
常见用法:
tag_match(query_key, doc_field, kv_op, merge_op)
高级用法:
tag_match(query_key, doc_field, kv_op, merge_op, has_default, doc_kv, max_kv_count)参数
query_key:指定查询语句中用于匹配的字段key-value值,该字段需要通过kvpairs子句传递,key与value通过英文等号‘=’分隔,多个key-value通过英文冒号‘:’分隔,如:
kvpairs=query_tags:10=0.67:960=0.85:1=48//表示参数query_tags中包含3个元素:10、960、1,其对应的value分别是:0.67、0.85、48。其中query也可以只为key的列表,如:kvpairs=cats:10:960:1。doc_field:指定文档中存储key-value的字段名,该字段为整型或者浮点型的数组类型(如果是浮点型数组,则key的值匹配的时强转当int64来处理)。数组的奇数位置是key,下一个相邻的偶数位置为key的value。即 [key0 value0 key1 value1 …]
kv_op:当query_key中的值与doc_field中的key匹配时对二者的value所采取的操作,目前支持的操作符如下:max(最大值)、min(最小值)、sum(求和)、avg(平均数)、mul(乘积)、query_value(query_key中该key对应的value值)、doc_value(文档中该key对应的value值)、number(常数)。
merge_op:多个key匹配后会产生多个结果,merge_op指定了将这些结果进行如何操作,目前支持的操作类型如下:max(最大值)、min(最小值)、sum(求和)、avg(平均值)、null(取第一个kv_op的计算结果,忽略其他结果)。
has_default:默认是false,表示不启动初始分值;为true时说明doc_field的第一个值为默认值,[init_score k0 v0 k1 v1…]。(类似base分值的概念)
doc_kv:默认是true。表明doc_field字段中的值是以key-value对的形式存在;为false则表示doc_field中只包含key信息,这种场景对doc需要存储标签,但是标签没有权重很方便。
max_kv_count:因为查询中的key-value结构需要通过query传递,所有tag_match对query中能传递多少key-value有限制。默认为50,可以通过这个参数将这个限制调大,但是最大不能超过5120。
返回值
double,返回具体的分值,如果has_default为false并且没有配额的内容则为0.如果需要返回int64的结果,需要使用int_tag_match,该函数功能与参数与int_tag_match完全一致,但int_tag_match不能在排序表达式中使用。适用场景
场景1:一个大型的综合性论坛,帖子可以被打上各种各样的标签(搞笑,体育,新闻,音乐,科普..)。我们在推送给open_search的文档中,可以为每个标签赋予一个标签id(例如搞笑-1, 体育-5, 新闻-3, 音乐-6..), 然后通过一个tag字段存储这些标签。 如果我们对帖子做过预处理,甚至能得到每个帖子每个标签的权重,例如一个搞笑体育新闻的帖子可以得到搞笑的权重为0.5,体育的权重为0.5,新闻权重为0.1,则这个帖子的tag字段的值为[1 0.5 5 0.5 3 0.1]对会员用户,通过长时间的积累,我们能获知每个用户的兴趣标签。
例如用户nba_fans对体育和搞笑很感兴趣,他对应的体育和搞笑标签的权重分别为0.6和0.3。那么这个用户查询时,我们就可以通过kv_pairs子句把这个信息加到query里面。假如这个kv_pairs子句名字为user_tag, 那么nba_fans的user_tag的值5=0.6:1=0.3。这样,我们只要在精排表达式中配置了tag_match(user_tag, tag, mul, sum), 我们就能够实现对用户感兴趣的帖子加权,把用户更感兴趣的帖子排到前面。例如nba_fans搜索到上面那个帖子时,搞笑和体育这两个标签能够匹配到。通过指定kv_op参数为mul,我们会把query和doc中的值相乘,他们各自的计算分数分别为(体育:0.5 * 0.6 = 0.3, 搞笑:0.5 * 0.3 = 0.15)。通过指定merge_op参数为sum,我们会把体育和搞笑的分数加和(0.3+0.15 = 0.45),这个加和的分数会加到最终的排序分数上。这样,我们就能够实现了对这个用户感兴趣帖子的排序加权。
场景2:商品可以具有多个属性标签,如1表示年轻人(年龄)、2表示中年人(年龄)、3表示小清新(风格)、4表示时尚(风格)、5表示女性(性别)、6表示男性(性别)等。
假设我们只想表示商品有没有某个标签,不想区分哪个标签更重要。这个标签通过options字段来保存。那么年轻时尚女性的衣服的options字段可以表示为[1 4 5], 注意这里只有标签key,没有value。用户也都有自己的属性标签,和商品标签对应。例如年轻女性用户,历史成交中多购买小清新风格衣服。这该用户的查询可以写为user_options=1:3:5。注意这里kv_pair中也是只有标签key,没有value的。要实现对符合用户标签喜好的商品加权,我们可以在formula中使用tag_match(user_options, options, 10, sum, false, false)。这里我们通过user_options和options指定了query和doc的标签信息。kv_op设为常数10,表示只要有标签匹配到,那么匹配的计算结果就是10。has_default为false,表示我们不需要初始值。doc_kv为false,表示我们doc中只存储了key信息,没有value。
这样,上面的年轻女用户查询到上面的衣服时,女性和年轻两个标签能够匹配上,这两个标签的计算结果都是10。通过sum这个merge_op,能够得到这件商品的最终加权分数为20。通过这种方式,即使我们没有标签的权重信息,也能够实现对匹配到的文档做排序加权。
注意事项
- 如果是用在filter或者sort子句中,则query_key、kv_op、merge_op、has_default、doc_kv必须使用双引号括起来,如:sort=-tag_match(“user_options”, options, “mul”, “sum”, “false”, “true”, 100)。
- tag_match的key匹配都是通过整数比较来完成的。因此query和doc中的key都应该转换为整数形式,如果是浮点类型,tag_match在比较时,会强制转换为整数类型

函数function项
插件function可以用在filter子句作为过滤和筛选条件,而返回值为数值型的fuction在sort子句中,用来做排序。其中函数参数出现的文档字段必须配置为属性字段。
in/notin : 判断字段值是否(不)在指定列表中
详细用法
in(field, “number1|number2”)
notin(field, “number1|number2”)参数
field:要判断的字段名,只支持INT及FLOAT类型,ARRAY及LITERAL、TEXT、模糊分词系列类型不支持
number列表:集合元素,多个值用’|’分隔,参数以字符串形式传入返回值
true/false适用场景
场景1:查询文档中包含“iphone”且type(int32类型)为1或2或3的文档;
query=default:’iphone’&&filter=in(type, “1|2|3”)场景2:查询文档中包含“iphone”且type(int32类型)不为1或2或3的文档;
query=default:’iphone’&&filter=notin(type, “1|2|3”)注意事项
- in(field, “number1|number2”)函数也等价于(field = number1) OR (field = number2),但是前者的性能会更好,同理notin也类似。
fieldlen : 获取literal类型字段长度
详细用法
fieldlen(field_name)参数
field_name:要判断的字段名,可以为literal或者array类型。返回值
字段内容长度,类型为int64。如果字段为array类型,则返回数组元素个数。适用场景
场景1:返回用户名usr_name不为空的文档
query=default:’关键词’&&filter=fieldlen(usr_name)>0
in_polygon : 判断某个点是否在某个多边形范围内,一般用于配送范围判断
详细用法
in_polygon(polygon_field, user_x_coordinate, user_y_coordinate, has_multi_polygons=”false”)参数
polygon_field: 表示商家配送范围的字段名,类型必须为DOUBLE_ARRAY, 字段值依次为配送多边形有序定点的x,y坐标(先x后y),顶点务必保证有序(顺时针、逆时针均可)!!如果有多个(N个)配送多边形,则第一个值表示多边形个数,第2~N+1的值表示后续每个多边形的顶点数(不是坐标数哦!!),第N+2值开始依次表示各多边形的顶点x,y坐标(N的值域为[1,50])
user_x_coordinate: 用户的x坐标, double类型
user_y_coordinate: 用户的y坐标, double类型
has_multi_polygons:表示polygon_filed是否包含多个独立的多边形需要判断。默认为false,表示只有单一的多边形。返回值
int,在多边形内返回第几个多边形匹配, 否则返回0。适用场景
场景1:判断用户是否在商家的配送范围。如商家配送范围的字段为coordinates, 用户位置坐标为 (120.307234, 39.294245),则过滤在配送范围内的商家查询可写为:
query=default:’美食’&&filter=in_polygon(coordinates, 120.307234, 39.294245)>0注意事项
- 最多支持50个多边形,超过则跳过该文档的计算;
- 不支持有孔多边形,如环;
- 不支持多个分离部分的多边形;
- 坐标个数为0,表示没有坐标,返回0;
- 坐标个数为奇数个,则认为数据有误,返回0;
- 用户点位于多边形边上,则认为匹配成功,返回为1(或具体多边形下标)。
- 多边形插件计算量较大,对查询性能有影响,建议尽量控制顶点个数,具体值请根据自己实际情况进行测试得出。
in_query_polygon : 判断文档中指定的点是否在用户指定的多边形范围内
详细用法
in_query_polygon(polygon_key, doc_point)参数
polygon_key:kvpairs子句中定义的用户参数key,多边形顶点存储在对应的value中。类型必须为DOUBLE_ARRAY,字段值依次为配送多边形有序定点的x,y坐标(先x后y),顶点务必保证有序(顺时针、逆时针均可)!!坐标之间用逗号分隔,格式为:xA,yA,xB,Yb。支持多个多边形,多边形与多边形之间通过分号(;)分隔。doc_point:类型必须为DOUBLE_ARRAY,表示需要判断的点。只包含两个值,依次为点的x,y坐标返回值
int,返回匹配到的第一个多边形的下标,没有匹配则返回0适用场景
场景1:搜索银泰商圈(xA,yA,xB,Yb,xC,Yc;xD,yD,xE,yE,xF,yF,xG,yG)的外婆家,商家位置存放在point字段中
query=default:’外婆家’&&filter=in_query_polygon(“polygons”, point)>0&&kvpairs=polygons:xA,yA,xB,Yb,xC,Yc;xD,yD,xE,yE,xF,yF,xG,yG
multi_attr : 返回数组字段指定位置的值
详细用法
multi_attr(field, pos, default_value=0|””)参数
field: 查询的字段名,必须为ARRAY数组类型,且必须配置为属性字段
pos: 整形常数或整形字段,需要配置为属性字段,,下标从0开始
default_value: 可选,字符串常量。表示如果指定pos的值不存在时,返回default_value返回值
类型和field保持一致适用场景
场景1:商品有多个价格[市场价、折扣价、销售价],存到prices字段中。查询销售价小于1000的手机 query=deault:’手机’&&filter=multi_attr(price,2)<1000
bit_struct: 将INT_ARRAY字段值进行自定义分组并允许对分组值进行指定operation计算
详细用法
bit_struct(doc_field, “$struct_definition”, operation, …)参数
doc_field: 是一个INT64_ARRAY类型的字段名。“$struct_definition”:用于把int64的值拆分成多个维度的信息。每一维的分组用int64中的起始bit位置和结束bit位置指定,使用横线“-”分隔,bit位置从值的高端开始算起,从0开始,最大不能超过63。多个分组用逗号”,”分隔。每个分组有一个编号,编号从1开始算起。
举例:假设用户需要把int64拆分成3个维度的信息, bit0到bit9代表一个值(用$1表示), bit10到bit48代表一个值(用$2表示), bit49到bit60代表一个值(用$3表示), 则该参数可写成: ”0-9,10-48,49-60”。operation:定义计算过程,最少定义1个,最多定义5个,每个operation会有一个编号,这个编号是接着struct_definition中的编号开始递增,当需要定义多个operation时,后面的operation要用到前面计算过的operatoin的返回值,这时候就可以用到给operation分配的编号了。
operation 可以定义的操作有:
“equal,$m,$n”: 判断$m代表的值和$n代表的值是否相等,相等返回true,否则返回false。
“overlap,$m,$n,$k,$p”:判断($m,$n)和($k,$p)定义的范围在数轴上是否相交。相交时返回true,否则返回false
“and,$m,$n,…”:返回$m, $n,..等做and(&&)的结果。
注:上面的这3个操作的参数也可以是整数数字。 例如 “equal,$1,1”返回值
int64,返回最后一个operation第一次为true时对应的doc_field中的数组下标(从0开始)。若doc_field中没有满足operation指定的要求的值,则返回-1。场景举例
查询给定时间段在营业的店铺有哪些
假定用户文档中有一个int64_array类型的字段open_time,每个值表示一段营业时间,将int64的高32位表示起始时间,低32位表示结束时间,如果要查询下午14点到15:30点营业的店铺,可以将时间转换为从当天0点开始,按分钟为单位的时间段, 则下午14点到15:30表示为(840,930),则查询中filter子句可以写为:
filter=bit_struct(open_time, “0-31,32-63”,”overlap,$1,$2,840,930”)!=-1查询未来某一天,某个餐点(早,中,晚),可以提供Pmin到Pmax人数就餐的店铺
假设用户文档中有一个int64_array类型的字段book_info,对于该字段中的一个值,0-7位表示日期,8-15位餐点,16-41位表示最小人数,42-63位表示最大人数。查询明天(用1表示)晚上(用3表示)能服务3-5个人的店铺,则filter子句可以写为:
filter=bit_struct(book_info,”0-7,8-15,16-41,42-63”,
“equal,$1,1”,”equal,$2,3”,”overlap,$3,$4,3,5”,”and,$5,$6,$7”)!=-1
这里$1表示book_info中0-7位代表的值,
$2表示book_info中8-15位代表的值
$3表示book_info中16-41位代表的值
$4表示book_info中42-63位代表的值
$5代表operation “equal,$1,1”的返回值
$6代表 operation”equal,$2,3”的返回值
$7代表operation “overlap,$3,$4,3,5”的返回值
返回$5,$6,$7代表的值做and(逻辑与)后第一次为true时候的值 在book_info中对应的数组下标查询下午14点到15:30表示为(840,930)之间,库存>10的店铺有哪些?
因为bit_struct返回的是下标,所以他可以和multi_attr函数一起配合使用,取另外一个array类型字段对应下标的值。如该例,可以在查询语句中使用:
filter=multi_attr(store, bit_struct(dispatch_time,”0-31,32-63”, “equal,$1,840”, “equal,$2,930”, “and,$3,$4”))>10
dispatch_time是文档中有一个多值INT64的字段,用于存储商户的配送时间。将时间转换为从当天0点开始,按分钟为单位的时间段, 则下午14点到15:30表示为(840,930)
store是一个int64_array字段,与dispatch_time的时间段分别对应,表示该时间段的库存量。
注意事项
- 更多介绍请参考 这里
特征feature项
功能feature可以用到排序表达式中(大部分仅支持精排表达式),可以通过各种语法及语句的组合得到强大的排序功能。其中函数参数出现的文档字段必须勾选可搜索.
static_bm25 : 静态文本相关性,用于衡量query与文档的匹配度
详细用法
static_bm25()参数
无返回值
float,值域为[0,1]适用场景
场景1:在粗排中指定文本分;
在粗排表达式中指定static_bm25()注意事项
- 可以用在粗排表达式
timeliness : 时效分,用于衡量文档的新旧程度
详细用法
timeliness(pubtime)参数
pubtime:要评估的字段,类型必须为int32或int64,单位为秒。返回值
float,值域为[0,1],值越大表示时效性越好。若大于当前时间则返回0。适用场景
场景1:在精排中指定create_timestamp字段的时效性;
在粗排表达式中指定timeliness(create_timestamp)注意事项
- pubtime字段必须配置为属性字段;
- 可以用在粗排和精排表达式。
timeliness_ms : 时效分,用于衡量文档的新旧程度
详细用法
timeliness_ms(pubtime)参数
pubtime:要评估的字段,类型必须为int32或int64,单位为毫秒。返回值
float,值域为[0,1],值越大表示时效性越好。若大于当前时间则返回0。适用场景
场景1:在精排中指定create_timestamp字段的时效性;
在粗排表达式中指定timeliness_ms(create_timestamp)注意事项
- pubtime字段必须配置为属性字段;
- 可以用在粗排和精排表达式
normalize :归一化函数,根据不同的算分将数值归一化至[0, 1]
场景概述
相关性计算过程中,一篇doc的好坏需要从不同的维度衡量。而各个维度的分数值域可能不同,比如网页点击数可能是成百上千万,网页的文本相关性分数在[0, 1]之间,它们之间没有可比性。为了在公式中使用这些元素,需要将不同的分数归一化至同一个值域区间,而normalize为这种归一化提供了一种简便的方法。normlize支持三种归一化方法:线性函数转化、对数函数转化、反正切函数转化。根据传入参数的不同,normalize自动选择不同的归一化方法。如果只指定value参数,normalize使用反正切函数转化,如果指定了value和max参数,normalize使用对数函数转化,如果指定了value、max和min,normalize使用线性函数转化。详细用法:
normalize(value, max, min)参数
value:需要做归一化的值,支持double类型的浮点数,该值可以来自文档中的字段或者其他表达式
max:value的最大值,可选,支持double类型的浮点数
min:value的最小值,可选,支持double类型的浮点数返回值
double,[0, 1]之间的值。适用场景
场景1:对price字段做归一化,但是不知道price的值域,可以使用如下公式进行归一化
normalize(price)场景2:对price字段做归一化,但是只知道price的最大值为100,可以使用如下公式进行归一化
normalize(price, 100)场景3:对price字段做归一化,并且知道price的最大值为100,最小值为1,可以使用如下公式进行归一化
normalize(price, 100, 1)场景4:将distance函数的结果归一化至[0, 1]
normalize(distance(longitude_in_doc, latitude_in_doc, longtitude_in_query, latitude_in_query))注意事项
- 使用反正切函数进行归一化时,如果value小于0,归一化后的值为0
- 使用对数函数进行归一化时,max的值要大于1
- 使用线性函数进行归一化时,max要大于min
gauss_decay,使用高斯函数,根据数值和给定的起始点之间的距离,计算其衰减程度
详细用法
gauss_decay(origin, value, scale, decay, offset)参数
origin:衰减函数的起始点,支持double类型的浮点数
value:需要计算衰减程度的值,支持double类型的浮点数,该值可以来自用户字段或者其他表达式
scale:衰减程度,支持double类型的浮点数
decay:当距离为scale时的衰减程度,支持double类型的浮点数,可选,默认值为0.000001
offset:当距离大于offset时才开始计算衰减程度,支持double类型的浮点数,可选,默认值为0返回值
返回值为double,区间为[0, 1]适用场景
场景1:查找距离用户最近的酒店,按照距离由近到远排序,并且认为距离小于100m的酒店不用做区分, longitude_in_doc和latitude_in_doc为酒店的经纬度,longtitude_in_query和latitude_in_query为用户的经纬度
gauss_decay(0, distance(longitude_in_doc, latitude_in_doc, longtitude_in_query, latitude_in_query), 5, 0.000001, 0.1)场景2:查找2000元左右的手机,并且如果价格小于1500或者大于2500时,文档算分为0,文档中手机价格为price,kvpairs=price_key:2000,公式如下:
gauss_decay(kvpairs_value(price_key, FLOAT), price, 500)注意事项
- 如果scale小于或者等于0,衰减函数默认返回0
- 如果decay大于或者等于1,衰减函数默认返回1
- 如果decay小于或者等于0,默认将decay设置为0.000001
- 如果offset小于0,默认将offset设置为0
exp_decay,使用指数函数,根据数值和给定的起始点之间的距离,计算其衰减程度
详细用法
exp_decay(origin, value, scale, decay, offset)参数
origin:衰减函数的起始点,支持double类型的浮点数
value:需要计算衰减程度的值,支持double类型的浮点数,该值可以来自用户字段或者其他表达式
scale:衰减程度,支持double类型的浮点数
decay:当距离为scale时的衰减程度,支持double类型的浮点数,可选,默认值为0.000001
offset:当距离大于offset时才开始计算衰减程度,支持double类型的浮点数,可选,默认值为0返回值
返回值为double,区间为[0, 1]适用场景
同gauss_decay,只是衰减算法不同注意事项
- 如果scale小于或者等于0,衰减函数默认返回0
- 如果decay大于或者等于1,衰减函数默认返回1
- 如果decay小于或者等于0,默认将decay设置为0.000001
- 如果offset小于0,默认将offset设置为0
linear_decay,使用指数函数,根据数值和给定的起始点之间的距离,计算其衰减程度
详细用法
linear_decay(origin, value, scale, decay, offset)参数
origin:衰减函数的起始点,支持double类型的浮点数
value:需要计算衰减程度的值,支持double类型的浮点数,该值可以来自用户字段或者其他表达式
scale:衰减程度,支持double类型的浮点数
decay:当距离为scale时的衰减程度,支持double类型的浮点数,可选,默认值为0.000001
offset:当距离大于offset时才开始计算衰减程度,支持double类型的浮点数,可选,默认值为0返回值
返回值为double,区间为[0, 1]适用场景
同gauss_decay,只是衰减算法不同注意事项
- 如果scale小于或者等于0,衰减函数默认返回0
- 如果decay大于或者等于1,衰减函数默认返回1
- 如果decay小于或者等于0,默认将decay设置为0.000001
- 如果offset小于0,默认将offset设置为0
exact_match_boost :获取查询中用户指定的查询词权重最大值
详细用法
exact_match_boost()参数
无返回值
int,值域为[0, 99]适用场景
场景1:查询为query=default:’开放搜索’^60 OR default:’opensearch’^50,希望按照实际匹配词boost权重来排序。如如果文档A包含“开放搜索”,文档B包含“opensearch”,则文档A排到文档B前面。
粗排表达式为:exact_match_boost() 精排表达式为空。 //精排为空,默认按照粗排表达式分值来排序。注意事项
- 如果对于没有指定boost的查询词默认boost值为99。
first_phase_score : 获取粗排表达式最终计算分值
详细用法
first_phase_score()参数
无返回值
float适用场景
场景1:粗排表达式为exact_match_boost(),精排为exact_match_boost()与text_relevance(title),且二者权重为3:1。
粗排表达式:exact_match_boost()
精排表达式:first_phase_score()*0.01*3+text_relevance(title) //直接使用first_phase_score()而exact_match_boostce()可以减少计算量,提高检索性能。注意事项
- 多个OR查询情况下,OR个数及查询召回文档数都对性能影响很大,需要根据实际场景进行详细的测试和优化。
text_relevance : 关键词在字段上的文本匹配度。
详细用法
text_relevance(field_name)参数
field_name:字段名,该字段需要为中文基础分词、中文基础分词、自定义分词、单字分词等类型,并且配置了索引字段。返回值
float,值域为[0,1]适用场景
场景1:在精排中对title和body进行文本算分,权重比为3:1
text_relevance(title)*3+text_relevance(body)注意事项
- 主要衡量角度:命中词在query中所占比重;命中词在字段中所占比重;命中词在字段中出现的频率;字段中命中词之间的顺序关系与query中命中词之间的顺序关系。
- 该feature目前只用于精排排序。
fieldterm_proximity : 用来表示关键词分词词组在字段上的紧密程度
详细用法
fieldterm_proximity(field_name)参数
field_name:该字段需要为TEXT、中文基础分词、自定义分词、单字分词等类型,并且建立了可搜索返回值
float,值域为[0,1]适用场景
场景1:在精排阶段计算query在title和body的紧密度,并且title字段的紧密度在排序中起主导作用,则在创建精排公式时公式内容可以写为:
fieldterm_proximity(title)*10 + fieldterm_proximity(body)注意事项
- 主要衡量角度:命中词在字段中的距离,命中词在字段中的相互顺序。
- 该feature目前只用于精排排序,且包含在text_relevance()中,即普通场景下二者无需共用。
kvpairs_value : 获取查询串中kvpairs子句中指定字段的值
详细用法
kvpairs_value(query_key, type)参数
query_key:要返回的kvpairs子句中的字段名type:kvpairs中query_key字段值的类型,目前支持的类型如下:INT,FLOAT,DOUBlE。用法示例
场景1:查询串中kvpairs子句中设置了query_key:10,10是整数类型,期望公式中取出query_key的value,公式可以写为:
kvpairs_value(query_key, INT)场景2:查询串中kvpairs子句中设置了query_key:10.1, 10.1是float类型,期望公式中取出query_key的value,公式可以写为:
kvpairs_value(query_key, FLOAT)场景3:查询串中kvpairs子句中设置了query_key:10.12, 10.12是double类型,期望公式中取出query_key的value,公式可以写为:
kvpairs_value(query_key, DOUBLE)
query_term_count : 返回查询词分词后词组个数
详细用法:
query_term_count()参数:
无返回值:
int适用场景:
场景1:根据查询词中term的个数做不同的处理; if (query_term_count() > 10, 0.5, 1)注意事项:
- 仅用于精排表达式
query_term_match_count :获取查询词中(在某个字段上)命中文档的词组个数
详细用法:
query_term_match_count(field_name)参数:
field_name: 非必选参数,要统计的字段名,该字段类型可以是TEXT、中文基础分词、自定义分词、单字分词、英文分词、模糊分词类型,并且配置了索引字段。若不指定该参数,则默认返回全部字段命中的词组个数。返回值:
int适用场景:
场景1:根据查询词在文档中title字段上命中的词组个数做不同的处理;
if (query_term_match_count(title) > 10, 0.5, 1)场景2:根据查询词中命中的词组个数做不同的处理;
if (query_term_match_count() > 10, 0.5, 1)注意事项:
- 可以用于精排表达式
- 统计的时查询词中命中的分词词组个数,重复的词组会计算多次
field_term_match_count :获取文档中某个字段与查询词匹配的词组个数
详细用法:
field_term_match_count(field_name)参数:
field_name: 要统计的字段名,该字段类型可以是TEXT、中文基础分词、自定义分词、单字分词、英文分词、模糊分词类型,并且配置了索引字段。返回值:
int适用场景:
场景1:根据字段中匹配的分词词组的个数做不同的处理
if (field_term_match_count(title) > 5, 0.8, 0.6)注意事项:
- 可以用于精排表达式
- 统计的是字段中命中的分词词组的个数,重复的词组会计算多次
query_match_ratio :获取查询词中(在某个字段上)命中词组个数与总词组个数的比值
详细用法:
query_match_ratio(field_name)参数:
field_name, 非必选参数,要统计字段名,该字段需要为TEXT、中文基础分词、自定义分词、单字分词、英文分词、模糊分词类型,并且配置了索引字段返回值:
float,值域为[0, 1]适用场景:
场景1:判断查询词中的词组是否全部命中文档
if (query_match_ratio() > 0.999, 1, 0)场景2:判断查询词中的词组是否全部命中文档的title字段
if (query_match_ratio(title) > 0.999, 1, 0)注意事项:
- 可以用于精排表达式
field_match_ratio: 获取某字段上与查询词匹配的分词词组个数与该字段总词组个数的比值
详细用法:
field_match_ratio(field_name)参数:
field_name:要统计的字段名,该字段需要为TEXT、中文基础分词、自定义分词、单字分词、英文分词、模糊分词类型,并且配置了索引字段返回值:
float,值域为[0, 1]适用场景:
场景1:在精排阶段计算title和body与查询词的匹配程度
field_match_ratio(title)*10 + field_match_ratio(body)注意事项:
- 可以用于精排表达式
- 该feature可以从一定程度上反应出field与query的匹配程度。
field_length:获取某个字段上的分词词组个数
详细用法:
field_length(field_name)参数:
field_name:要获取的字段名,该字段需要为TEXT、中文基础分词、自定义分词、单字分词、英文分词、模糊分词类型,并且配置了索引字段。返回值:
int适用场景:
场景1:根据字段分词词组个数设置不同的权重
if (field_length(title) > 200, 0.3, 0.7)注意事项:
- 可以用于精排表达式
query_min_slide_window:查询词在某个字段上命中的分词词组个数与该词组在字段上最小窗口的比值
详细用法:
query_min_slide_window(field_name, in_order=false)参数:
field_name:要统计的字段,该字段需要为TEXT、中文基础分词、自定义分词、单字分词、英文分词、模糊分词类型,并且配置了索引字段。
in_order:true|false,默认为false。表示进行滑动窗口比较时,窗口中词组的顺序是否必须和查询词中的保持一致。返回值:
float,值域为[0, 1]适用场景:
场景1:计算查询词在title上的最小窗口
query_min_slide_window(title)场景2:判断title字段中是否存在于查询词中相同的子序列
if(query_min_slide_window(title, true) > 0.99, 1, 0)注意事项:
- 可以用于精排表达式;
- 从字面上衡量query在field_name字段上紧密度情况;
- 影响滑动窗口计算的有两个因素,query在field_name字段上命中的term的个数和包含这些term的最小窗口。
最后更新:2016-11-23 16:04:03
上一篇: 搜索相关性配置__应用高级配置_产品使用手册_开放搜索-阿里云
搜索相关性配置__应用高级配置_产品使用手册_开放搜索-阿里云
下一篇: 搜索摘要配置__应用高级配置_产品使用手册_开放搜索-阿里云
- GetCallerIdentity__操作接口_STS API文档_访问控制-阿里云
- 示例二__快速开始_Quick BI-阿里云
- 阿里云发布Link物联网平台:未来将赋予物联网以智能
- 云服务器 ECS 快照(Snapshot)技术优势对比
- 管理缓存数据__用户指南_云数据库 Memcache 版-阿里云
- 【推荐】ECS Windows开启内核转储(Core Dump)配置说明__蓝屏夯机_操作系统类问题_Windows操作运维问题_云服务器 ECS-阿里云
- EDAS 账号合并计费说明___服务条款和价格说明_企业级分布式应用服务 EDAS-阿里云
- APP设备统计__API列表_OpenAPI 1.0_移动推送-阿里云
- TXC 控制台快速入门__TXC for EDAS_二方服务_企业级分布式应用服务 EDAS-阿里云
- 队列使用手册__Java SDK_SDK使用手册_消息服务-阿里云
相关内容
- 常见错误说明__附录_大数据计算服务-阿里云
- 发送短信接口__API使用手册_短信服务-阿里云
- 接口文档__Android_安全组件教程_移动安全-阿里云
- 运营商错误码(联通)__常见问题_短信服务-阿里云
- 设置短信模板__使用手册_短信服务-阿里云
- OSS 权限问题及排查__常见错误及排除_最佳实践_对象存储 OSS-阿里云
- 消息通知__操作指南_批量计算-阿里云
- 设备端快速接入(MQTT)__快速开始_阿里云物联网套件-阿里云
- 查询API调用流量数据__API管理相关接口_API_API 网关-阿里云
- 使用STS访问__JavaScript-SDK_SDK 参考_对象存储 OSS-阿里云