Yahoo的流計算引擎基準測試
Yahoo的流計算引擎對比測試
(雅虎Storm團隊排名不分先後) Sanket Chintapalli, Derek Dagit, Bobby Evans, Reza Farivar, Tom Graves, Mark Holderbaugh, Zhuo Liu, Kyle Nusbaum, Kishorkumar Patil, Boyang Jerry Peng and Paul Poulosky。
免責聲明:2015年12月17日的數據,數據團隊已經給我們指出,我們不小心在Flink基準測試中留下的一些調試代碼。 所以Flink基準測試應該不能直接與Storm和Spark比較。 我們在重新運行和重新發布報告時已經解決了這個問題。
更新:2015年12月18日有一個溝通上的誤解,我們運行的Flink的測試代碼不是checked in的代碼。 現在調試代碼已經刪除。數據團隊檢查了代碼,並證實它和目前的運行的測試是一致的。 我們仍然會在某個時候重新運行它。
摘要-由於缺乏真實世界的流基準測試,我們1比較了Apache Flink,Apache Storm和 Apache Spark Streaming。 Storm 0.10.0/0.11.0-SNAPSHOT和 Flink 0.10.1 測試表明具有亞秒級的延遲和相對 較高的吞吐量, Storm 99%情況下具有最低的延遲。 Spark Streaming 1.5.1支持高吞吐量,但是具有相對 較高的延遲。
在雅虎,我們已經在一些日常使用中支持我們的商業開源的大數據平台上投入巨資。 對於流工作負載,我們的首選平台一直Apache的Storm,它取代了我們的內部開發的S4平台。 我們一直在廣泛使用Storm,目前雅虎運行Storm節點的數量現在已經達到了2300個(並且還在不斷增加中)。
由於我們最初使用 Storm是在2012年決定的,但目前的流處理係統現狀已經發生了很大的改變。 現在有幾個其他值得關注的競爭對手包括 Apache Flink,Apache Spark(Spark Streaming),Apache Samza,Apache Apex和穀歌的Cloud Dataflow。 有越來越多的議論探討哪個係統可以提供最佳的功能集,哪一個在哪些條件下性能更好(例如見 這裏 , 這裏 , 這裏 ,還有這裏 )。
為了給我們的內部客戶提供最好的流計算引擎工具,我們想知道Storm擅長什麼和它與其他係統相比哪些還需要提高。 要做到這一點,我們就開始尋找那些可以為我們提供流處理基準測試的資料,但目前的資料都在一些基本領域有所欠缺。 首先,他們沒有任何接近真實世界的用例測試。 因此,我們決定寫一個並將它開源https://github.com/yahoo/streaming-benchmarks。 在我們的初步評估中,我們決定在我們的測試限製在三個最流行的和有希望的平台(Storm,Flink和Spark),但對其他係統,也歡迎來稿,並擴大基準的範圍。
基準設計
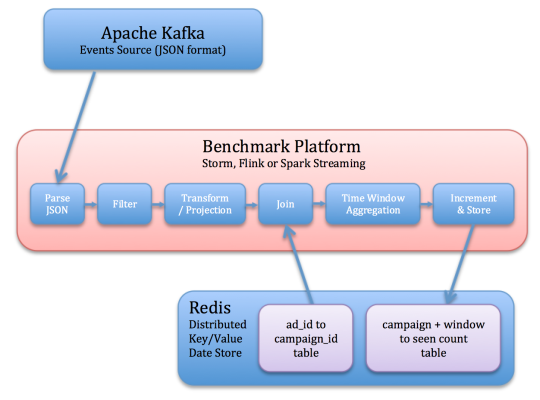
基準的任務是從Kafka讀取各種JSON事件,確定相關的事件,並存儲每個campaigns活動相關的事件轉換成Redis的時間窗口計數。 這些步驟試著偵測數據流所進行的一些常用的操作。
操作的流程如下(和在下麵的圖中示出):
- 讀取Kafka事件。
- 反序列化JSON字符串。
- 過濾掉不相關的事件(基於EVENT_TYPE字段)
- 取相關字段的快照(ad_id和EVENT_TIME)
- ad_id及其關聯的campaign_id加入每個事件。 這個信息被存儲在Redis中。
- 每campaign活動一個窗口計數,每窗口計數存儲在Redis中,附帶最後更新的時間戳。 此步驟必須能夠處理延遲的事件。
輸入數據有以下模式:
- USER_ID:UUID
- PAGE_ID:UUID
- ad_id:UUID
- ad_type:字符串在{banner,modal,讚助搜索,郵件,Mobile}
- EVENT_TYPE:字符串在{視圖,點擊,購買}
- EVENT_TIME:事件發生時間戳
- IP地址:字符串
生產者創建帶有創建時間戳標記的事件。 截斷此時間戳到一個特定的數字,這個特定的數字給出了時間窗口和事件所屬的開始時間 ,在Storm和Flink中,雖然更新Redis是定期的,但常常足以滿足選定的SLA。 我們的SLA為1秒,因此我們每秒一次往Redis寫入更新的窗口。 Spark由於其設計的巨大差異,操作上略有不同, 有一個關於在Spark部分的更多細節是我們與數據一起記錄時間,並在Redis中記錄每個窗口的最後更新時間。
每次運行時,程序會讀取Redis的Windows和Windows的時間窗口並比較它們的last_updated_at次數、產生的延遲數據點。 因為如果上次事件窗口不能被發送(emit),該窗口將關閉,一個窗口的時間,其last_updated_at時間減去其持續時間之差表示是在窗口從給Kafka到Redis期間通過應用程序的時間。
window.final_event_latency =(window.last_updated_at – window.timestamp) – window.duration
這一個有點粗糙,但這個基準測試並沒有對這些引擎定義窗口數據粒度的粗細,而是提供了他們行為的更高級視圖。
基準設置
- 10秒時間窗口
- 1秒SLA
- 100 個 campaigns 活動
- 每次campaigns 活動有10個事件
- 5 個 Kafka與5個分區節點
- 1 個 Redis節點
- 10個工作節點(不包括像Storm的Nimbus協調節點)
- 5-10 個Kafka生產者節點
- 3 個ZooKeeper節點
因為在我們的架構中,Redis的節點使用一個精心優化的散列方案,僅執行內存查找,它並不會成為瓶頸。 節點被均勻配置,每一個節點有兩個英特爾E5530 2.4GHz處理器,總共16個核心(8物理核心,16超線程)每節點。 每個節點具有24GB的內存,機器都位於同一機架內,通過千兆以太網交換機相連。 集群共擁有40個節點。
因為單個生產者最大每秒產生約一萬七千事件,我們跑了Kafka生產者的多個實例,以創建所需的負載。我們使用在這個基準測試中利用了20到25個節點(作為生產者實例)。
每個topology使用10個worker,接近我們看到的雅虎內部正在使用的topology的平均數目。 當然,雅虎內部的Storm集群更大,但是它們是多租戶並運行著許多的 topology。
Kafka開始基準測試時會被清空數據,Redis填充了初始數據(ad_id到campaign_id映射),流作業開始後會等待一段時間,讓工作完成啟動,讓生產者的生產活動穩定在一個特定的速率,並獲得所需的總吞吐量。 該係統在生產者被關閉之前會運行30分鍾。停止前允許有幾秒鍾的滯後以讓流工作引擎處理完所有事件。 基準測試工具運行會生成含有window.last_updated_at的列表的文件– window.timestamp數據。 這些文件被保存為我們測試各個引擎的吞吐量並用來生成這份測試報告中的圖表。
Flink
該基準測試中, Flink 使用Java的DataStream的API實現。 該Flink的DataStream中的API和Storm的API有許多相似之處。 對於這兩種Flink和Storm,數據流可以被表示為一個有向圖。 每個頂點是一個用戶定義的運算,每向邊表示數據的流動。 Storm的API使用spout 和bolts 作為其運算器,而Flink使用map,flatMap,以及許多預建的operators ,如filter, project, 和 reduce。 Flink使用一種叫做檢查點,以保證處理它提供類似Storm的ACKING擔保機製。 我們跑這個基準測試時Flink已默認關閉檢查點。在Flink中值得注意的配置列表如下:
- taskmanager.heap.mb:15360
- taskmanager.numberOfTaskSlots:16
該Flink版本的基準測試使用FlinkKafkaConsumer從Kafka讀取數據。 數據在Kafka中是一個JSON格式的字符串,然後由一個定製的flatMap operator 反序列化並解析。 一旦反序列化,數據通過自定義的過濾器過濾。 之後,經過濾的數據,通過使用project 投影(projected )。 從那裏,將數據由自定義的flapMap函數產生Redis的數據,最終的數據計算結果寫入Redis。
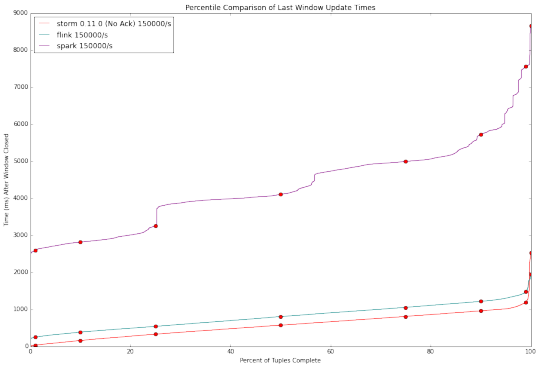
在該Kafka發出的數據事件到Flink基準速率從50,000個事件/秒到17萬次/秒變化。 對於每個Kafka發射(emit)率,Flink完全處理元組的百分比與延遲時間的基準示於下圖。
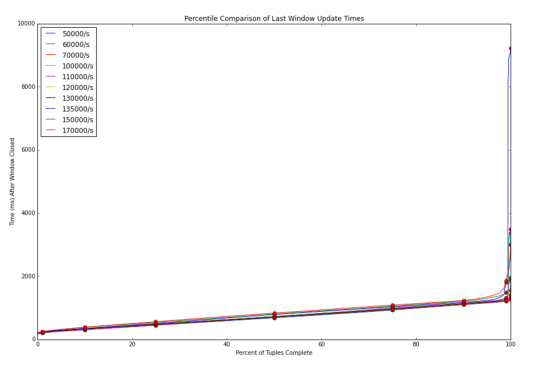
延遲在所有Kafka 發射(emit)率是相對一致的。 等待時間線性上升,直到大約第99百分位數時(約1%的數據處理時間),延遲出現成倍的增加(1%的數據處理延遲遠遠大於99%的數據)。
Spark
Spark基準代碼用Scala編寫。 由於Spark的微批處理方法和Storm的純流計算引擎性質不同,我們需要重新考慮基準實現的部分。 為了滿足SLA, Storm和Flink每秒更新一次Redis,並在本地緩存中保留中間值。按此設計,Spark Streaming 的時間批次被設置為1秒,這會導致較小的吞吐量,為此我們不得不擴大批次的時間窗口以保證更大的吞吐量。
基準用的是典型Spark風格的DStreams。 DStreams是流數據,相當於普通RDDs,並為每個微批次創建一個單獨的RDD。 注意,在隨後的討論中,我們使用術語“RDD”而不是“DSTREAM”來表示在當前活動micro batch中的RDD。 處理直接使用Kafka Consumer 以及Spark1.5。 因為在我們的基準中Kafka輸入的數據被存儲在5個分區,Kafka消費者創建具有5個分區的DSTREAM。 在此之後,一些變換施加在DStreams,包括maps 和 filters。 涉及與Redis的交互數據的變換是一種特殊情況,因為我們不想每次記錄Redis就創建一個單獨的連接,我們使用一個mapPartitions操作,可以給RDD代碼整個分區的控製權。 通過這種方式,我們創建一個連接到Redis的單一連接,並通過該連接從Redis中查詢在RDD分區中的所有事件信息。 同樣的方法在以後我們往Redis寫入最終結果的時候使用。
應當指出的是,我們的寫入Redis的方式被實現為RDD變換,以維持基準測試的簡潔,雖然這不會與恰好一次的語義兼容。
我們發現,Spark沒能保持主足夠的高吞吐量。 在每秒達到100000消息時延遲大大增加了。 我們認為需要沿著兩個方麵進行調整,以幫助Spark應付增長的吞吐量。
第一是microbatch持續時間。 這個控製維度不存於像Storm純流計算引擎係統中。 增加持續時間同時也增加了等待時間,這樣就減少(調度)開銷並因此增加了最大吞吐量。 挑戰是,在處理吞吐量延遲最小化和最優批持續時間之間調整是一個耗時的過程。 從本質上講,我們要選擇一個批處理時間,運行基準30分鍾,檢查結果,並減少/增加批持續時間。
第二個是並行度。 增加並行度似乎簡單,但對Spark來說做起來難。 對於一個真正的流計算引擎係統像Storm,一個bolt 實例可以使用隨機洗牌(reshuffling)方式發送它的結果到其它任何數量的bolt 實例。 要擴大規模,增加第二bolt 的並行度就可以。 Spark在一樣的情況下,我們需要執行類似於Hadoop的MapReduce的程序決定整個集群合並洗牌操作, 但reshuffling 本身引入了值得考慮的開銷。 起初,我們以為我們的操作是計算密集型(CPU-bound)的,為較多分區做reshuffling相對reshuffling 自身的開銷是利大於弊,但實際上瓶頸在於調度,所以reshuffling 隻增加開銷。 我們懷疑高吞吐率的操作(對spark來說)都是計算密集型的。
最後的結果很有趣。 不同的窗口持續時間下Spark有三種不同的結果。 首先,如果批處理的窗口持續時間設定得足夠大,大部分事件都將在當前微批處理中完成處理。 下圖顯示了這種情況下,得到百分比加工圖(100K事件/10秒窗口持續時間)。
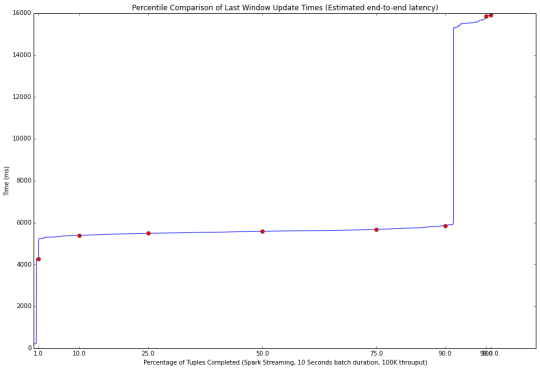
90%的事件在第一個微批處理中被處理,這就有了改善延遲的可能性。 通過減少批處理窗口持續時間,事件被安排至3到4個批次進行處理。 這帶來了第二個問題,每批次的持續時間內無法處理完所有安排到該時間窗口中的事件,但仍是可控的,更小的批處理窗口持續時間帶來了更低的延遲。這種情況示於下圖(100K事件/3秒窗口持續時間)。
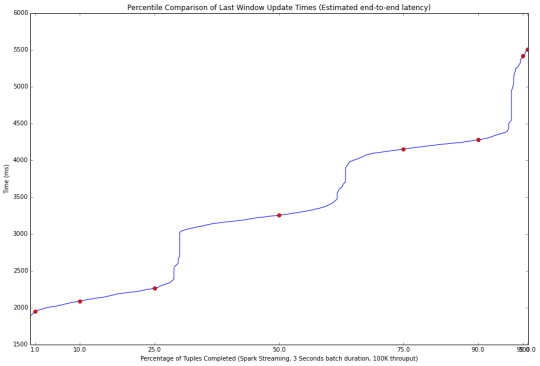
最後,第三個現象是當Spark Streaming 處理速度跟不上時,基準測試的輸入數據需要入隊列並等待幾分鍾以讓Spark 完成處理所有的事件。 這種情況示於下圖。 在這種不良的工作方式,Spark溢出大量的數據到磁盤上,在極端的情況下,我們最終可能出現磁盤空間不足的情況。
最後要說明的是,我們試圖在Spark1.5中引入的新背壓(back pressure)功能。 如果係統是在第一工作區域,背壓沒有效果。 在第二操作區域,背壓導致更長的延遲。 第三操作區域結果顯示背壓帶了副作用。 它改變了批次的長度,此時Spark處理速度仍然跟不上, 示於下圖。 我們的測試表明,目前的背壓功能並沒有幫助我們的基準,因此我們禁用了它。
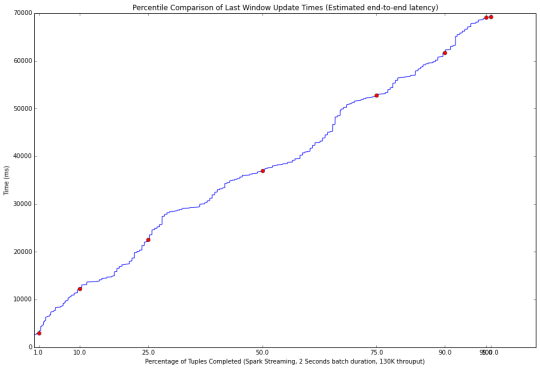
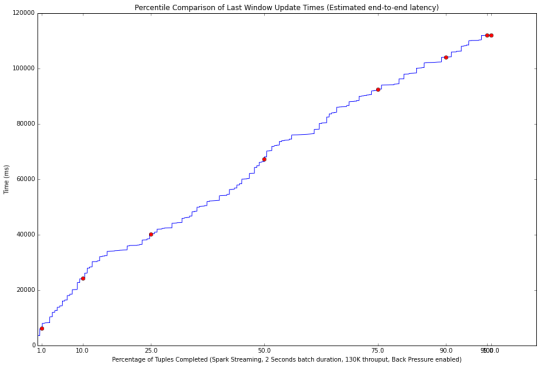
無背壓(上圖)的性能,以及與背壓啟用(下圖)。 啟用背壓後延遲性能較差(70秒VS 120秒)。 注意,這兩種的結果對流處理係統是不可接受的,因為數據處理速度都落後於 輸入數據的速度。 批處理的時間窗口設定為2秒時,具有130000的吞吐量。
Storm
Storm的基準測試使用Java API編寫。 我們測試了Apache的Storm 0.10.0 和 0.11.0-Snapshot版本。 Snapshot commit hash是a8d253a。 每個主機分配一個工作進程,每個worker給予16 tasks 以運行16個executors ,也就是每個cpu核心一個executor。
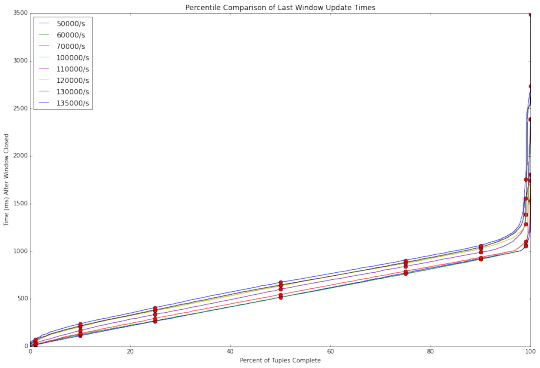
Storm0.10.0:
Storm0.11.0:
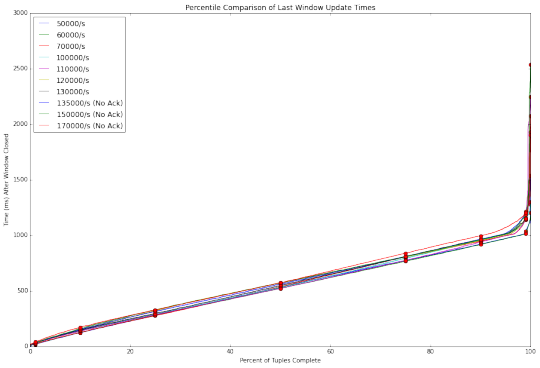
與Flink和Spark Streaming相比,Storm毫不遜色。 Storm 0.11.0 優於 Storm 0.10.0,顯然0.11.0對0.10.0版本做了優化。 然而,在高吞吐量上Storm的兩個版本依舊捉襟見肘, 其中Storm 0.10.0 無法處理超過每秒135000事件的吞吐量。
Storm 0.11.0同樣遇到了瓶頸,直到我們禁用ACKING。 在基準測試Topology中,ACKING用於流量控製而不是處理擔保。 在0.11.0中,Storm增加了一個簡單的背壓控製,使我們能夠避免ACKING的開銷。 隨著ACKING啟用,0.11.0 版本在在150,000/s的吞吐量測試上 /比0.10.0 -稍好,但依然很糟糕。 隨著ACKING被禁用,Storm在高吞吐量上比Flink的延遲性能要好。 不過注意的是,隨著ACKING被禁用,報告和處理的元組故障的功能也被禁用。
結論和未來工作
下圖比較這三個係統的測試結果, 我們可以看出,Storm和Flink兩者具有線性響應。 這是因為這兩個係統是一個一個的處理傳入事件。 另一方麵,在Spark Streaming 依據微批處理設計, 處理是逐步的方式得到結果。
吞吐量VS延遲曲線圖在係統對比中差異也許是最明顯的,因為它總結了我們的研究結果。 Flink和Storm具有非常相似的性能,而Spark Streaming,需要高得多的等待時間,但能夠處理更高的吞吐量。
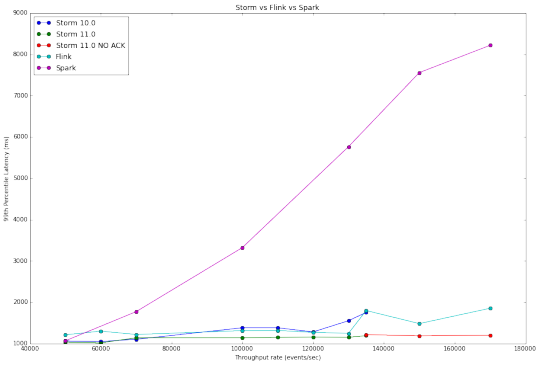
超過每秒135000的事件中不包括 Storm0.10.0和0.11.0在ACKING啟用時的結果,因為他們處理速度無法跟上吞吐量。 由此產生的圖形中Storm0.10.0 在45000毫秒時結束測試, topology 跑的時間越長,得到越高的延遲,這表明它性能在降低。
所有這些標準,除非另有說明, Storm,Spark,和Flink均采用默認設置進行,我們專注於撰寫正確的,容易理解,無需每次優化的,以充分發揮其潛力的方案。 由於這種每六個步驟都是一個單獨的bolt或spout。 Flink和Spark的aggregation合並操作是自動的,但Storm(非trident)沒有。 這意味著對Storm來說,事件經過更多的步驟,相比於其他係統具有更高的開銷。
除了對Storm進一步優化,我們想擴大在功能方麵的測試,並在測試中包括像Samza和Apex 等其他流處理係統,未來也會把容錯性,處理擔保和資源利用率作為測試的基準。
對我們來說 Storm 足夠滿足要求。 拓撲結構寫起來簡單,很容易獲得低延遲, 和Flink相比能得到更高的吞吐量。如果沒有ACKING,Storm甚至在非常高的吞吐量時擊敗Flink,我們期望進一步優化bolts組合,更智能的tuples路由和改進ACKING,讓Storm ACKING啟用時可以在非常高的吞吐量時與Flink相競爭。
近來實時流計算引擎係統之間的競爭日趨白熱化,但並沒有明顯的贏家, 每個平台都有各自的優點和缺點。 性能隻是其中之一,其他如安全、工具集也是衡量因素。 活躍的社區為這些和其他大數據處理項目進行不斷的創新,不斷從對方的進步中受益。 我們期待著擴大這個基準測試並測試這些係統的新版本。
最後更新:2017-05-19 17:33:28