![]() 476
476
![]()
![]() windows
windows
導入導出數據__快速開始_大數據計算服務-阿裏雲
MaxCompute提供多種數據導入導出方式:直接在客戶端使用Tunnel命令 或者通過 TUNNEL 提供的SDK自行編寫Java工具,以及通過Flume及Fluentd插件方式導入。
Tunnel命令導入數據
準備數據
假設我們準備本地文件wc_example.txt,內容如下:
I LOVE CHINA!MY NAME IS MAGGIE.I LIVE IN HANGZHOU!I LIKE PLAYING BASKETBALL!
這裏我們把該數據文件保存在D:odpsodpsbin目錄下。
創建ODPS表
我們需要把上麵的數據導入到MaxCompute的一張表中,所以需要創建一張表:
CREATE TABLE wc_in (word string);
執行tunnel命令
輸入表創建成功後,可以在MaxCompute客戶端輸入tunnel命令進行數據的導入,如下:
tunnel upload D:odpsodpsbinwc_example.txt wc_in;
執行成功後,查看表wc_in的記錄,如下:
odps@ $odps_project>select * from wc_in;ID = 20150918110501864g5z9c6Log view:https://webconsole.odps.aliyun-inc.com:8080/logview/?h=https://service-corp.odps.aliyun-inc.com/api&p=odps_public_dev&i=20150918QWxsb3ciLCJSZXNvdXJjZSI6WyJhY3M6b2RwczoqOnByb2plY3RzL29kcHNfcHVibGljX2Rldi9pbnN0YW5jZXMvMjAxNTA5MTgxMTA1MDE4NjRnNXo5YzYiXX1dLC+------+| word |+------+| I LOVE CHINA! || MY NAME IS MAGGIE.I LIVE IN HANGZHOU!I LIKE PLAYING BASKETBALL! |+------+
注意:
- 有關Tunnel命令的更多詳細介紹,例如:如何將數據導入分區表,請參考Tunnel操作。
- 當表中含有多個列時,可以通過“-fd”參數指定列分隔符;
Tunnel SDK
關於如何利用tunnel SDK進行上傳數據,下麵也將通過場景介紹。場景描述:上傳數據到ODPS,其中,項目空間為”odps_public_dev”,表名為”tunnel_sample_test”,分區為”pt=20150801,dt=hangzhou”。
- 創建表,添加分區:
CREATE TABLE IF NOT EXISTS tunnel_sample_test(id STRING,name STRING)PARTITIONED BY (pt STRING, dt STRING); --創建表ALTER TABLE tunnel_sample_testADD IF NOT EXISTS PARTITION (pt='20150801',dt='hangzhou'); --添加分區
- 創建UploadSample的工程目錄結構,如下:
UploadSample : tunnel源文件pom.xml : maven工程文件|---pom.xml|---src|---main|---java|---com|---aliyun|---odps|---tunnel|---example|---UploadSample.java
編寫UploadSample程序,程序如下:
package com.aliyun.odps.tunnel.example;import java.io.IOException;import java.util.Date;import com.aliyun.odps.Column;import com.aliyun.odps.Odps;import com.aliyun.odps.PartitionSpec;import com.aliyun.odps.TableSchema;import com.aliyun.odps.account.Account;import com.aliyun.odps.account.AliyunAccount;import com.aliyun.odps.data.Record;import com.aliyun.odps.data.RecordWriter;import com.aliyun.odps.tunnel.TableTunnel;import com.aliyun.odps.tunnel.TunnelException;import com.aliyun.odps.tunnel.TableTunnel.UploadSession;public class UploadSample {private static String accessId = "####";private static String accessKey = "####";private static String tunnelUrl = "https://dt-corp.odps.aliyun-inc.com";private static String odpsUrl = "https://service-corp.odps.aliyun-inc.com/api";private static String project = "odps_public_dev";private static String table = "tunnel_sample_test";private static String partition = "pt=20150801,dt=hangzhou";public static void main(String args[]) {Account account = new AliyunAccount(accessId, accessKey);Odps odps = new Odps(account);odps.setEndpoint(odpsUrl);odps.setDefaultProject(project);try {TableTunnel tunnel = new TableTunnel(odps);tunnel.setEndpoint(tunnelUrl);PartitionSpec partitionSpec = new PartitionSpec(partition);UploadSession uploadSession = tunnel.createUploadSession(project,table, partitionSpec);System.out.println("Session Status is : "+ uploadSession.getStatus().toString());TableSchema schema = uploadSession.getSchema();RecordWriter recordWriter = uploadSession.openRecordWriter(0);Record record = uploadSession.newRecord();for (int i = 0; i < schema.getColumns().size(); i++) {Column column = schema.getColumn(i);switch (column.getType()) {case BIGINT:record.setBigint(i, 1L);break;case BOOLEAN:record.setBoolean(i, true);break;case DATETIME:record.setDatetime(i, new Date());break;case DOUBLE:record.setDouble(i, 0.0);break;case STRING:record.setString(i, "sample");break;default:throw new RuntimeException("Unknown column type: "+ column.getType());}}for (int i = 0; i < 10; i++) {recordWriter.write(record);}recordWriter.close();uploadSession.commit(new Long[]{0L});System.out.println("upload success!");} catch (TunnelException e) {e.printStackTrace();} catch (IOException e) {e.printStackTrace();}}}
注解:這裏我們省略了accessId和accesskey的配置,實際運行時請換上您自己的accessId以及accessKey。
pom.xml文件配置如下:
<?xml version="1.0" encoding="UTF-8"?><project xmlns="https://maven.apache.org/POM/4.0.0"xmlns:xsi="https://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="https://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.aliyun.odps.tunnel.example</groupId><artifactId>UploadSample</artifactId><version>1.0-SNAPSHOT</version><dependencies><dependency><groupId>com.aliyun.odps</groupId><artifactId>odps-sdk-core</artifactId><version>0.20.7-public</version></dependency></dependencies><repositories><repository><id>alibaba</id><name>alibaba Repository</name><url>https://mvnrepo.alibaba-inc.com/nexus/content/groups/public/</url></repository></repositories></project>
- 編譯與運行:編譯UploadSample工程:
運行UploadSample程序,這裏我們利用eclipse導入maven project:右擊java工程並點擊< Import->Maven->Existing Maven Projects >設置如下:mvn package
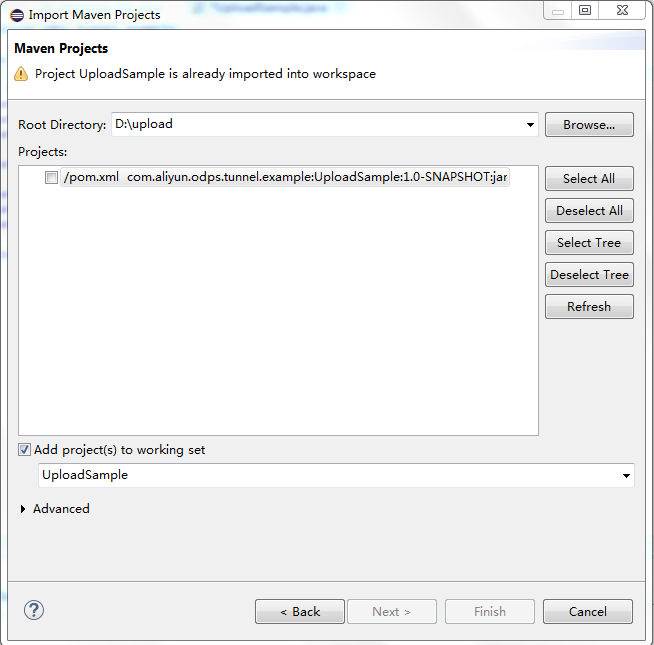
右擊UploadSample.java並點擊< Run As->Run Configurations >,如下:
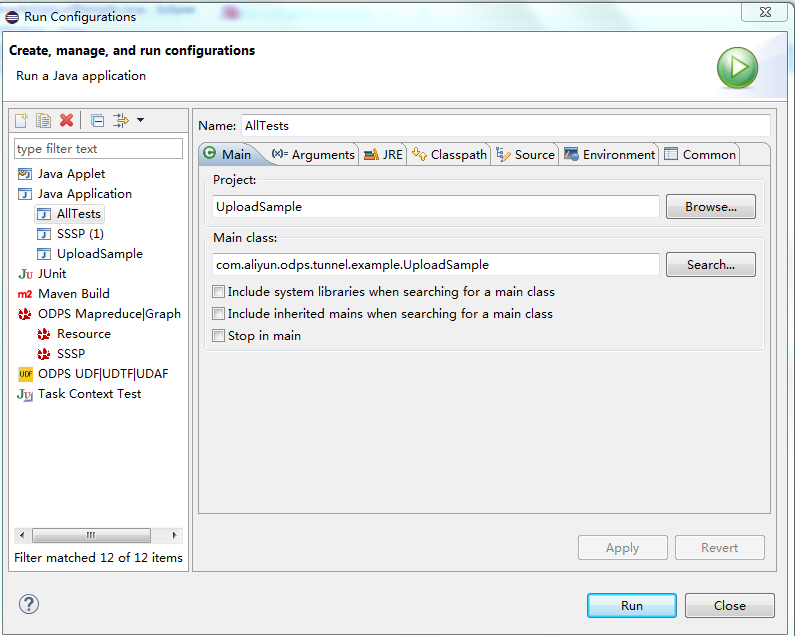
點擊< Run >運行成功:控製台顯示:
Session Status is : NORMALupload success!
- 查看運行結果:在客戶端輸入:
顯示結果如下:select * from tunnel_sample_test;
+----+------+----+----+| id | name | pt | dt |+----+------+----+----+| sample | sample | 20150801 | hangzhou || sample | sample | 20150801 | hangzhou || sample | sample | 20150801 | hangzhou || sample | sample | 20150801 | hangzhou || sample | sample | 20150801 | hangzhou || sample | sample | 20150801 | hangzhou || sample | sample | 20150801 | hangzhou || sample | sample | 20150801 | hangzhou || sample | sample | 20150801 | hangzhou || sample | sample | 20150801 | hangzhou |+----+------+----+----+
備注:
- Tunnel作為MaxCompute中一個獨立的服務,有專屬的訪問端口提供給大家。當用戶在阿裏雲內網環境中,使用Tunnel內網連接下載數據時,MaxCompute不會將該操作產生的流量計入計費。此外內網地址僅對上海域的雲產品有效。
- MaxCompute阿裏雲內網地址:https://odps-ext.aliyun-inc.com/api
- MaxCompute公網地址:https://service.odps.aliyun.com/api
Fluentd導入方案
除了通過客戶端及Tunnel Java SDK導入數據外,MaxCompute還提供了導入數據的工具-Fluentd。
Fluentd是一個開源的軟件,用來收集各種源頭日誌(包括Application Log、Sys Log及Access Log),允許用戶選擇插件對日誌數據進行過濾、並存儲到不同的數據處理端(包括MySQL、Oracle、MongoDB、Hadoop、Treasure Data、AWS Services、Google Services以及ODPS等)。Fluentd以小巧靈活而著稱,允許用戶自定義數據源、過濾處理及目標端等插件。目前在這款軟件中已經有300+個插件運行Fluentd的架構上,而且這些插件全部是開源的。 MaxCompute也在這款軟件上開源了數據導入插件。
環境準備
使用這款軟件,向MaxCompute導入數據,需要具備如下環境:
- Ruby 2.1.0 或更新
- Gem 2.4.5 或更新
- Fluentd-0.10.49 或從 Fluentd 官網 查找最新,Fluentd為不同的OS提供了不同的版本,詳見 Fluentd 官方文檔
- Protobuf-3.5.1 或更新(Ruby protobuf)
安裝導入插件
接下來可以通過以下兩種方式中的任意一種來安裝MaxCompute Fluentd 導入插件。
方式一:通過ruby gem安裝
$ gem install fluent-plugin-aliyun-odps
MaxCompute已經將這個插件發布到GEM庫中, 名稱為 fluent-plugin-aliyun-odps,隻需要通過gem install 命令來安裝即可(大家在使用gem 時在國內可能會遇到gem庫無法訪問,可以在網上搜一下更改gem 庫源來解決)。
方式二:通過插件源碼安裝
$ gem install protobuf$ gem install fluentd --no-ri --no-rdoc$ git clone https://github.com/aliyun/aliyun-odps-fluentd-plugin.git$ cp aliyun-odps-fluentd-plugin/lib/fluent/plugin/* {YOUR_FLUENTD_DIRECTORY}/lib/fluent/plugin/ -r
其中第二條命令是安裝fluentd,如果已經安裝可以省略。 MaxCompute Fluentd插件源碼在github上,clone下來之後直接放到Fluentd的plugin目錄中即可。
插件的使用
使用Fluentd導入數據時,最主要的是配置Fluentd的conf文件,更多conf文件 的介紹請參考 Fluentd 配置文件介紹 。
示例一:導入Nginx日誌 。Conf中source的配置如下。
<source>type tailpath /opt/log/in/in.logpos_file /opt/log/in/in.log.posrefresh_interval 5stag in.logformat /^(?<remote>[^ ]*) - - [(?<datetime>[^]]*)] "(?<method>S+)(?: +(?<path>[^"]*?)(?: +S*)?)?" (?<code>[^ ]*) (?<size>[^ ]*) "-" "(?<agent>[^"]*)"$/time_format %Y%b%d %H:%M:%S %z</source>
fluentd 以tail方式監控指定的文件內容是否有變化,更多的tail配置參見:Fluentd 官方文檔 。
match 配置如下:
<match in.**>type aliyun_odpsaliyun_access_id ************aliyun_access_key *********aliyun_odps_endpoint https://service.odps.aliyun.com/apialiyun_odps_hub_endpoint https://dh.odps.aliyun.combuffer_chunk_limit 2mbuffer_queue_limit 128flush_interval 5sproject projectforlog<table in.log>table nginx_logfields remote,method,path,code,size,agentpartition ctime=${datetime.strftime('%Y%m%d')}time_format %d/%b/%Y:%H:%M:%S %z</table></match>
數據會導入到projectforlog project的nginx_log表中,其中會以源中的datetime字段作為分區,插件遇到不同的值時會自動創建分區。
示例二:導入MySQL中的數據。導入MySQL中數據時,需要安裝fluent-plugin-sql插件作為數據源:
$ gem install fluent-plugin-sql
配置conf中的source:
<source>type sqlhost 127.0.0.1database testadapter mysqlusername xxxxpassword xxxxselect_interval 10sselect_limit 100state_file /path/sql_state<table>table test_tabletag in.sqlupdate_column id</table></source>
這個例子是從test_table中SELECT數據,每間隔10s去讀取100條數據出來,SELECT 時將ID列作為主鍵(id字段是自增型)。關於fluent-plugin-sql的更多說明參見 Fluentd SQL插件官方說明
match 配置如下:
<match in.**>type aliyun_odpsaliyun_access_id ************aliyun_access_key *********aliyun_odps_endpoint https://service.odps.aliyun.com/apialiyun_odps_hub_endpoint https://dh.odps.aliyun.combuffer_chunk_limit 2mbuffer_queue_limit 128flush_interval 5sproject your_projectforlog<table in.log>table mysql_datafields id,field1,field2,fields3</table></match>
數據會導出到MaxCompute projectforlog project的mysql_data表中,導入的字段包括id, field1, field2, field3。
插件參數說明
向MaxCompute導入數據,需要將插件配置在conf文件中match項中。插件支持的參數說明如下:
- type(Fixed): 固定值 aliyun_odps.
- aliyun_access_id(Required):雲賬號access_id.
- aliyun_access_key(Required):雲賬號access key.
- aliyun_odps_hub_endpoint(Required):如果你的服務部署在ESC上,請把本值設定為 https://dh-ext.odps.aliyun-inc.com, 否則設置為https://dh.odps.aliyun.com.
- aliyunodps_endpoint(Required):如果你的服務部署在ESC上,請把本值設定為 https://odps-ext.aiyun-inc.com/api, 否則設置為https://service.odps.aliyun.com/api.
- buffer_chunk_limit(Optional): 塊大小,支持“k”(KB),“m”(MB),“g”(GB)單位,默認 8MB,建議值2MB.
- buffer_queue_limit(Optional): 塊隊列大小,此值與buffer_chunk_limit共同決定整個緩衝區大小.
- flush_interval(Optional): 強製發送間隔,達到時間後塊數據未滿則強製發送, 默認 60s.
- project(Required): project名稱.
- table(Required): table名稱.
- fields(Required): 與source對應,字段名必須存在於source之中.
- partition(Optional):若為分區表,則設置此項.
- 分區名支持的設置模式:
- 固定值: partition ctime=20150804
- 關鍵字: partition ctime=${remote} (其中remote為source中某字段)
- 時間格式關鍵字: partition ctime=${datetime.strftime(‘%Y%m%d’)} (其中datetime為source中某時間格式字段,輸出為%Y%m%d格式作為分區名稱)
- time_format(Optional):如果使用時間格式關鍵字為< partition >, 請設置本參數. 例如: source[datetime]=”29/Aug/2015:11:10:16 +0800”,則設置< time_format > 為”%d/%b/%Y:%H:%M:%S %z”
Flume
除了使用Fluentd可以導入數據外,MaxCompute還支持通過Flume導入數據。Flume是Apache的一款開源軟件,MaxCompute基於Flume開源了導入插件源代碼,感興趣的朋友可以參見 Flume MaxCompute 插件了解更多細節。
最後更新:2016-12-14 16:25:51
上一篇: 創建刪除表__快速開始_大數據計算服務-阿裏雲
創建刪除表__快速開始_大數據計算服務-阿裏雲
下一篇: 運行SQL__快速開始_大數據計算服務-阿裏雲
- 啟用伸縮組__API快速入門_快速入門_彈性伸縮-阿裏雲
- 阿裏雲安全白皮書都有哪些重要內容?
- 雲虛擬主機開源discuz安裝指南__程序安裝_使用指南_雲虛機主機-阿裏雲
- 參數說明__Spark_開發人員指南_E-MapReduce-阿裏雲
- PasswordPolicy__數據類型_RAM API文檔_訪問控製-阿裏雲
- MapReduce開發插件介紹__Eclipse開發插件_工具_大數據計算服務-阿裏雲
- 步驟 1:配置選型__快速入門(Linux)_雲服務器 ECS-阿裏雲
- Decrypt__API 參考_密鑰管理服務-阿裏雲
- 刪除應用__應用管理_用戶指南_容器服務-阿裏雲
- 消費者狀態顯示"是否在線" 為"否" 問題排查__技術分享_技術運維問題_消息隊列 MQ-阿裏雲
相關內容
- 常見錯誤說明__附錄_大數據計算服務-阿裏雲
- 發送短信接口__API使用手冊_短信服務-阿裏雲
- 接口文檔__Android_安全組件教程_移動安全-阿裏雲
- 運營商錯誤碼(聯通)__常見問題_短信服務-阿裏雲
- 設置短信模板__使用手冊_短信服務-阿裏雲
- OSS 權限問題及排查__常見錯誤及排除_最佳實踐_對象存儲 OSS-阿裏雲
- 消息通知__操作指南_批量計算-阿裏雲
- 設備端快速接入(MQTT)__快速開始_阿裏雲物聯網套件-阿裏雲
- 查詢API調用流量數據__API管理相關接口_API_API 網關-阿裏雲
- 使用STS訪問__JavaScript-SDK_SDK 參考_對象存儲 OSS-阿裏雲